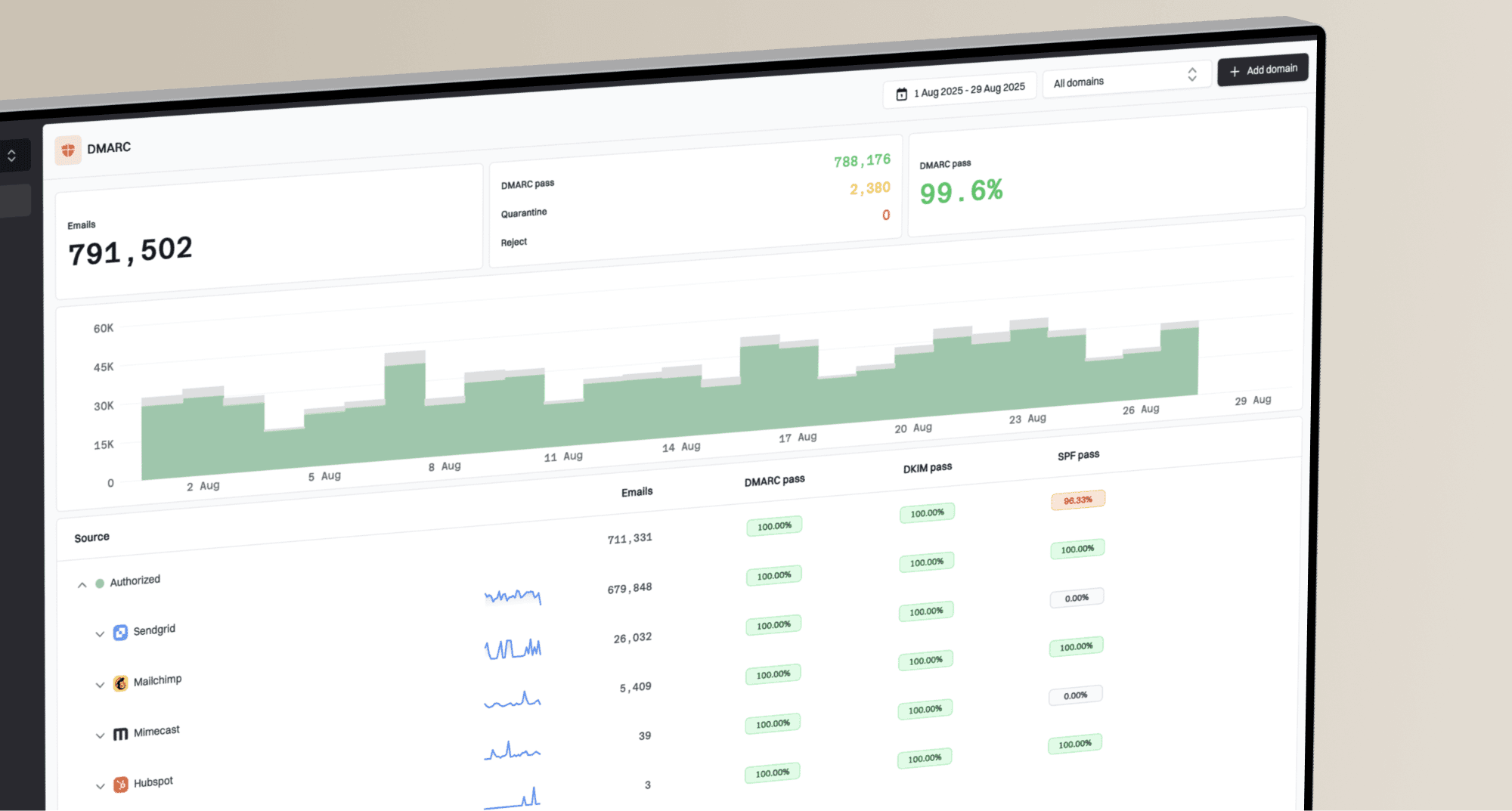
What to do when SFMC shared IP reputation tanks due to other senders?

Published 27 May 2025
Updated 25 May 2026
13 min read
Summarize with

If SFMC shared IP reputation tanks because another sender in the pool spikes volume, triggers blocks, or gets the range listed on a blocklist (blacklist), treat it as an infrastructure incident, not a normal warmup wobble. I would document the evidence, escalate through Support and the account team, ask for a pool move or dedicated IP migration, and protect my own domain reputation while SFMC works the abuse side.
The short answer is this: you are right to be concerned, but anger does not fix the sending path. The practical move is to build a clean case that separates your mail behavior from the shared pool behavior. If your sends were stable, complaints were near zero, engagement was strong, and the shared IP range suddenly jumped in volume, that is enough to push for operational action.
- Immediate fix: ask SFMC to move you to a healthier shared pool or start the move to your dedicated IP.
- Proof: collect bounce logs, deferrals, IP volume changes, blocklist status, complaint rates, and mailbox provider patterns.
- Risk control: reduce risky segments, keep authentication clean, and send only to recently engaged recipients until placement recovers.
- Decision point: if the same pool keeps collapsing, plan the dedicated IP path even if your volume is lower than the usual comfort threshold.
Why this happens on SFMC shared IPs
A shared IP pool combines the reputation signals of multiple senders. Your domain, content, engagement, complaint rate, and authentication matter, but the IP reputation still carries pooled risk. If another sender pushes a sudden high-volume campaign, sends to poor data, or causes complaints, mailbox providers can throttle or block the shared IPs before they have enough detail to separate every sender.
The pattern that worries me most is not one IP having a bad day. It is a whole shared range showing a synchronized volume jump and reputation drop, followed by B2C blocking at Yahoo, AOL, Microsoft, or delayed Gmail delivery. That points to pool-level damage rather than a single bad campaign from your account.
Treat the date as evidence
When the pool changes on one clear date, build your escalation around that date. Show your send volume, complaint rate, engagement, and bounce pattern before and after it. The cleaner your timeline, the harder it is for support to treat the problem as a generic deliverability ticket.
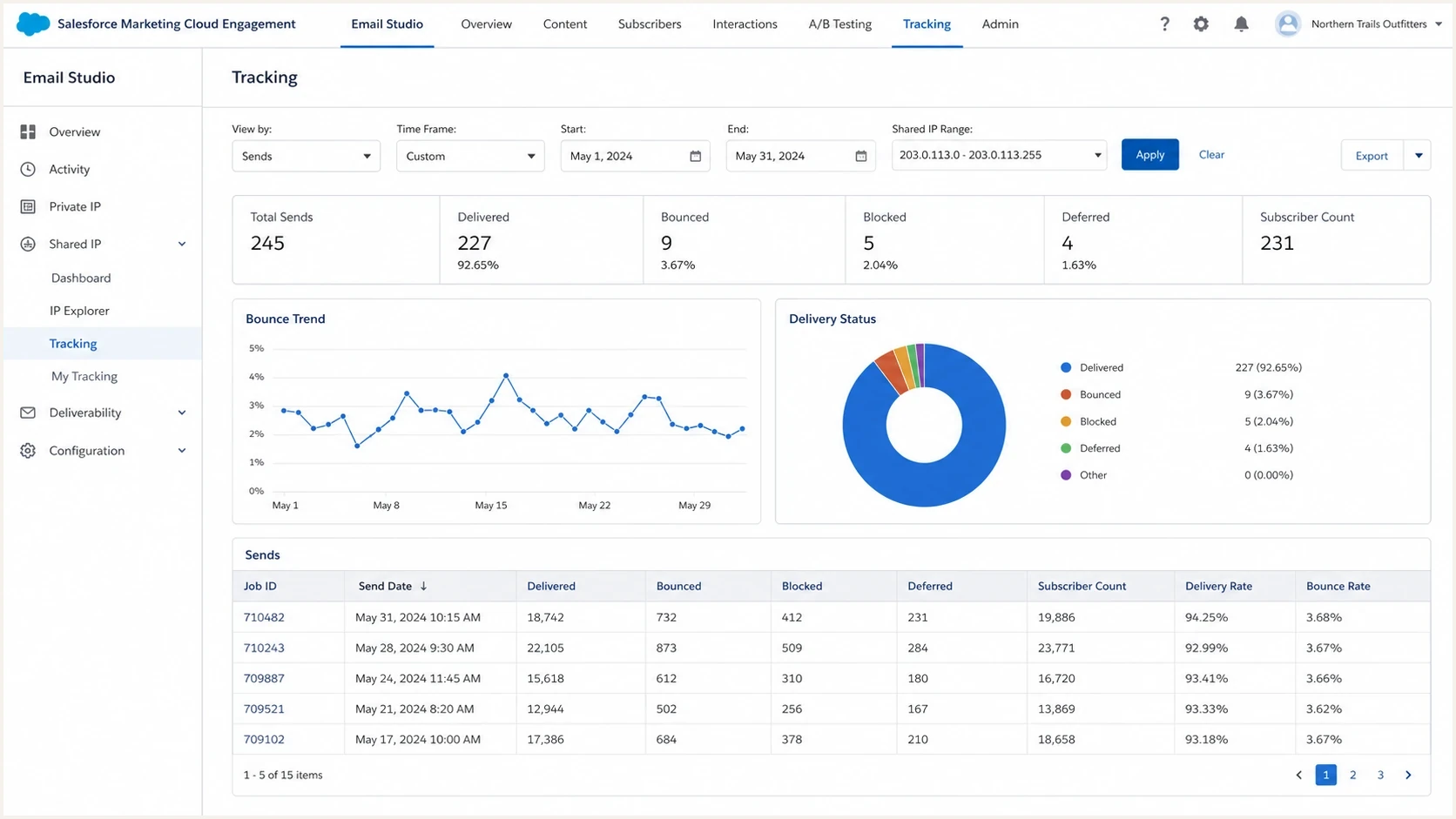
Salesforce Marketing Cloud Engagement tracking view for shared IP delivery issues.
The hard part is that SFMC Support cannot tell you which sender caused the problem or exactly what abuse action is being taken. That privacy boundary is normal. What you can ask for is confirmation that Deliverability and Abuse are engaged, that mailbox provider remediation is in progress, and that SFMC is evaluating whether your account should stay on the current pool.
What I would do first
I would stop arguing the emotion of the issue and make the operational request precise. The request is not "please improve deliverability". It is "our shared IP range appears to have suffered pool-wide reputation damage starting on this date, and we need a pool move, dedicated IP migration, or written mitigation plan."
- Export evidence: pull send volume, delivery, bounce, deferral, spam complaint, unsubscribe, and engagement metrics for 30-60 days.
- Map mailbox impact: separate Gmail delays, Microsoft blocks, Yahoo deferrals, AOL issues, and corporate filtering separately.
- Check the infrastructure: confirm DMARC, SPF, DKIM, reverse DNS, bounce domain matching, and tracking domain configuration.
- Escalate with a deadline: ask for the next action and review date, not just a note that mailbox providers were contacted.
- Reduce exposure: pause unengaged segments and batch your best recipients first while the pool is unstable.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
A live send test is useful because it shows what a mailbox provider and receiving system see in the actual message. Use an email tester to inspect headers, authentication, domain matching, and content-level warnings. That will not prove another sender caused the IP problem, but it stops SFMC or internal stakeholders from blaming a broken DNS record when the evidence says the pool is the issue.
Escalation requesttext
We are seeing pool-wide delivery failure on the shared SFMC IP range. The issue began on YYYY-MM-DD. Our account volume, complaints, and engagement did not change materially. The shared IP range volume increased sharply on the same date. Please confirm whether Deliverability and Abuse are engaged. Please evaluate moving us to a different pool or to our dedicated IP. Please provide the next mitigation step and review date.
How to prove the problem is the shared pool
You need a before-and-after record. If your daily send volume was steady and the shared IP range suddenly jumped from low volume to hundreds of thousands of messages, that is not your program warming incorrectly. It is a pool event. The goal is to show that your domain behavior stayed stable while the IP behavior changed.
|
|
|
|---|---|---|
Your volume | Daily sends | Your traffic was stable |
Pool volume | IP-level traffic | Other senders changed the pool |
Complaints | Complaint rate | Your list did not collapse |
Bounces | SMTP replies | Receivers blocked the path |
Authentication | DMARC checks | DNS is not the cause |
Evidence that separates sender behavior from pool behavior.
I also like to keep a separate health check for the domain itself. A domain health check gives you a clean snapshot of DMARC, SPF, DKIM, and related setup, which helps when support asks for basic configuration proof.
Keep blocklist and blacklist checks in context
A blocklist listing can explain a sudden receiver block, but a clean blacklist result does not prove the pool is healthy. Large mailbox providers rely on internal reputation systems too. Use blocklist monitoring as one signal alongside bounces, delays, complaint data, and engagement.
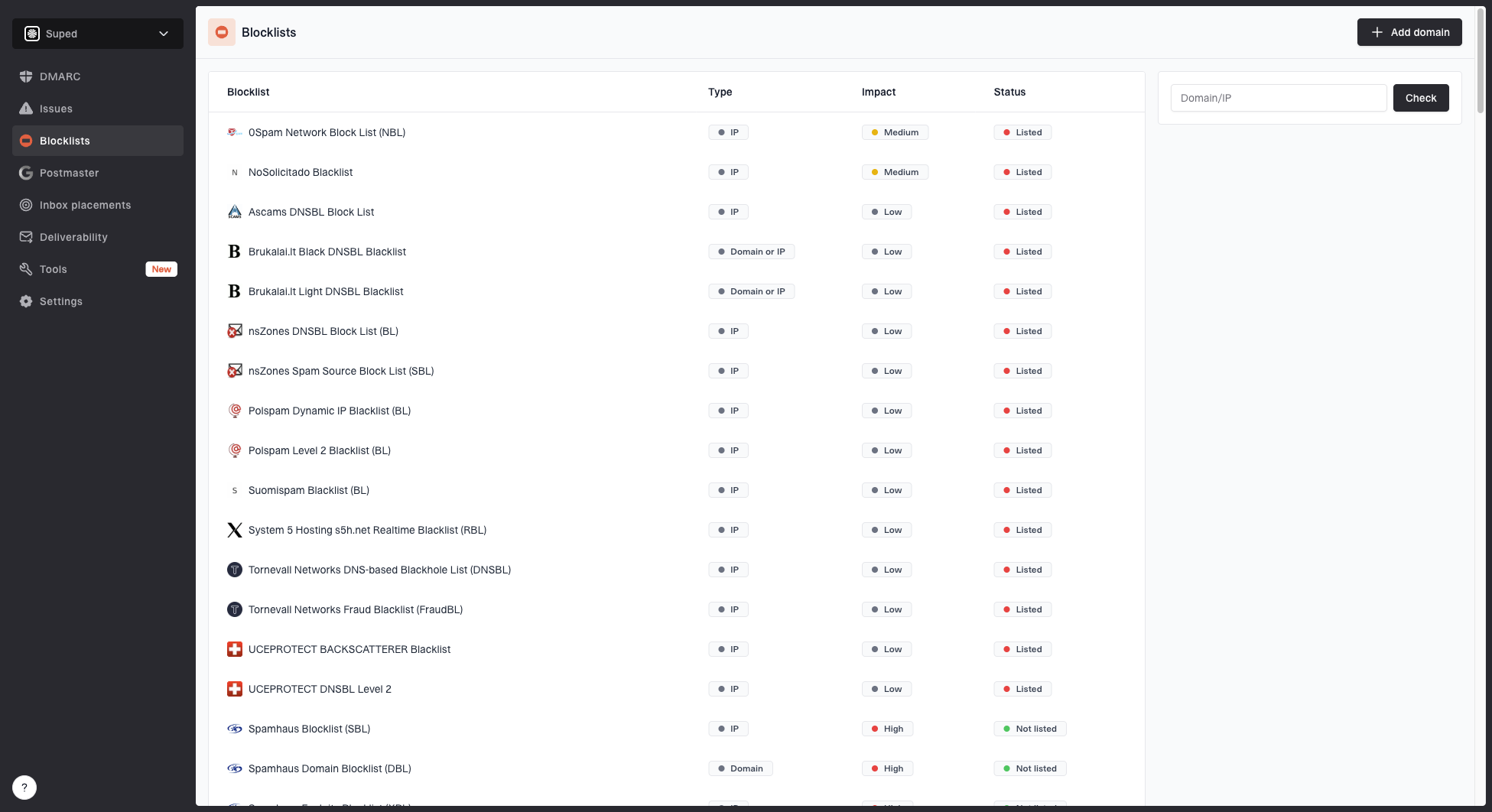
Blocklist monitoring page showing domain and IP checks across blocklists with importance and status
This is where Suped fits in a practical workflow. Suped tracks DMARC, SPF, DKIM, blocklist status, and deliverability signals in one place, so you can keep your domain evidence separate from the shared IP evidence. That matters when your ESP is handling the IP pool but your team still needs proof that your authentication and domain practices are sound.
Shared pool move or dedicated IP
There are two realistic infrastructure paths: move to a healthier shared pool or move to the dedicated IP you already bought. A pool move is faster if SFMC approves it, but it keeps you exposed to other senders. A dedicated IP gives more control, but low volume can leave you warming for longer and can make reputation signals thinner.
Ask for a pool move
- Best when: your volume is low and SFMC can place you in a cleaner pool quickly.
- Main risk: the next pool can suffer the same problem if other senders behave badly.
- How to ask: show pool-wide damage and ask for reassignment with a review date.
Move to dedicated IP
- Best when: the shared pool is repeatedly blocked and you need control.
- Main risk: low volume gives mailbox providers fewer signals to evaluate.
- How to ask: request a controlled warmup using your most engaged segments first.
The old advice says a dedicated IP needs enough volume to create a stable reputation footprint. That advice still has value. But it breaks down when the shared pool is actively harming delivery. I would rather manage a careful low-volume dedicated warmup than sit in a shared pool that is already blocked at major receivers.
Dedicated IP volume guidance
A practical way to think about whether a dedicated IP is manageable.
Too thin
Under 50k/month
Use only if the shared pool is clearly damaging delivery.
Workable
50k-250k/month
Warm slowly and keep targeting tight.
Strong
250k+/month
Enough traffic to sustain clearer IP signals.
If you can send more than 5,000 messages per day to Gmail or Yahoo during normal operations, I would be comfortable pushing the dedicated IP plan. If you send less, I would still consider it when the shared pool is causing repeated blocks, especially if the program has a clean list and predictable cadence.
For a deeper IP strategy discussion, the related breakdown on low-volume sender strategy covers the tradeoff between thin volume and bad shared infrastructure.
How to protect your domain while the pool recovers
Your domain reputation can offset some IP weakness over time, especially at large consumer mailbox providers that evaluate domain, engagement, authentication, complaint history, and user-level signals. It cannot fully cancel a deeply damaged IP pool. Some enterprise filters and gateways apply less nuance and block the sending IP or range aggressively.
- Tighten targeting: send to recent openers, clickers, purchasers, account users, and people with clear consent.
- Separate risk: hold older subscribers, reactivation campaigns, bought data, appended contacts, and weak consent sources.
- Keep cadence steady: avoid sudden spikes while receivers are already watching the shared IP range.
- Watch authentication: make sure DMARC domain matching, SPF, DKIM, bounce domains, and tracking domains remain correct.
- Record every change: note segment changes, send reductions, content changes, support updates, and provider-specific results.
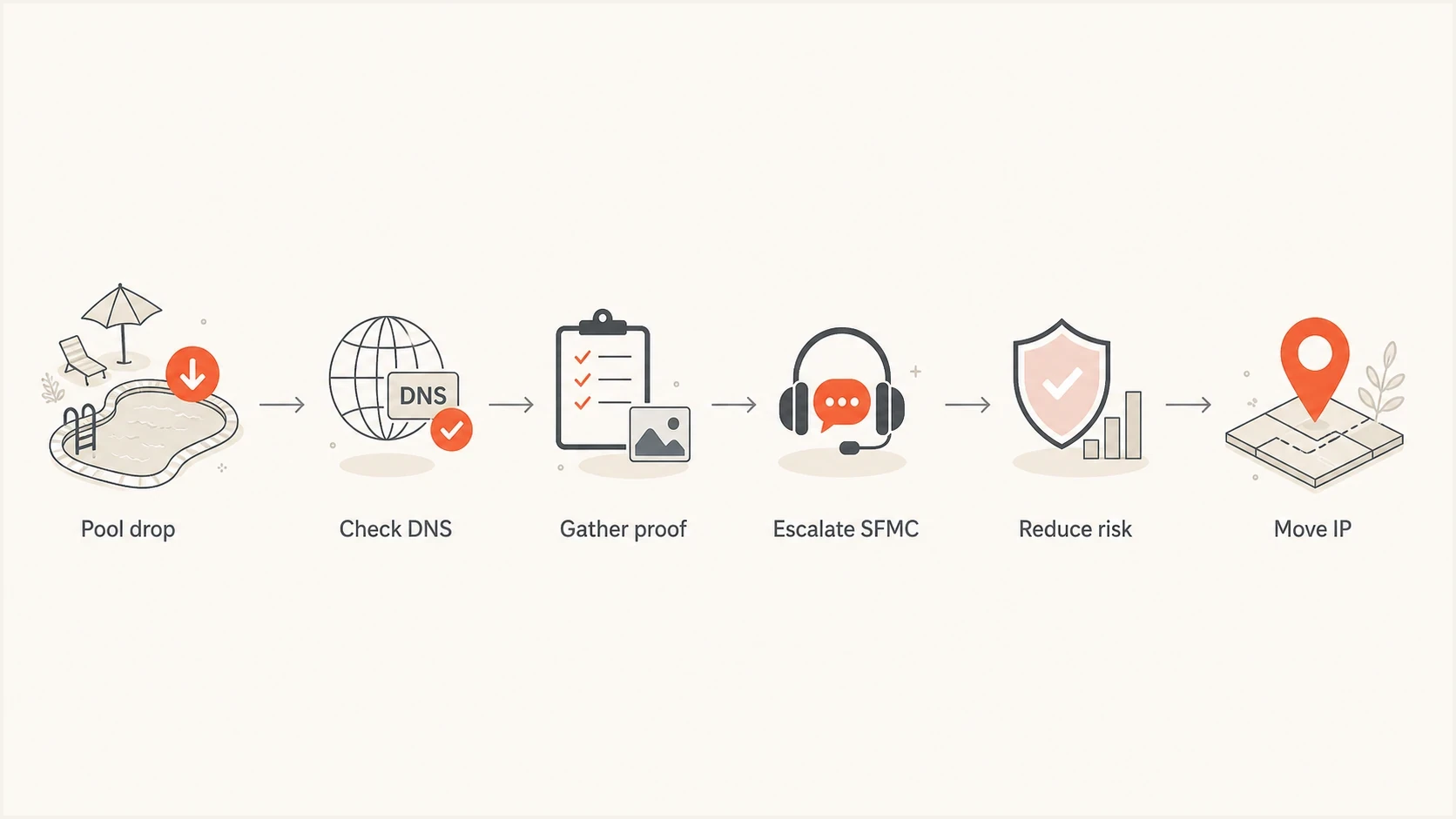
Flowchart for responding to SFMC shared IP reputation damage.
Suped is useful here because it turns authentication and reporting data into issues with fix steps. If DMARC starts failing for a source, DKIM is missing on a new stream, or SPF is close to lookup limits, Suped flags it early. That keeps the avoidable problems off your plate while you work the SFMC infrastructure problem.
The goal is not just passing DMARC
Passing DMARC proves the message is authenticated and the visible sender domain matches the authenticated domain. It does not guarantee inbox placement. For this kind of incident, use DMARC monitoring to keep your domain clean while you separately track IP reputation, blocklist status, and provider response codes.
What to say to SFMC and your account team
Support tickets often stall when they are framed as broad deliverability complaints. I would send a short evidence packet and ask for specific ownership. Your account team matters because pool changes and dedicated IP decisions can involve more than first-line Support.
Account team escalationtext
We need account-level escalation for a shared IP pool incident. Our deliverability dropped across major B2C providers on YYYY-MM-DD. The shared IP range shows a matching volume spike and reputation drop. Our own sending metrics do not explain the change. We need one of these outcomes: 1. Move to a healthier shared pool. 2. Start dedicated IP migration and warmup. 3. Provide a written mitigation plan with dates and owner.
Weak ticket
Our emails are going to spam. Please fix deliverability.
Useful ticket
The shared IP range changed behavior on a specific date, while our account metrics stayed stable. Please evaluate pool reassignment or dedicated IP migration.
I would ask direct questions and keep them answerable. Is Deliverability assigned? Is Abuse reviewing the pool? Are mailbox provider mitigations open? Is a pool move available? If not, who approves dedicated IP migration for a low-volume sender with active shared pool damage?
If Microsoft is the main failure point, read the related note on Microsoft shared IP spam because Microsoft blocking often needs separate evidence and a different remediation timeline.
When to accept the dedicated IP risk
I would accept the dedicated IP risk when the shared pool has already failed at multiple major providers and SFMC cannot give a clear pool-level fix. Low volume is not ideal, but it is not automatically worse than a damaged shared pool. A low-volume dedicated IP requires discipline. A damaged shared IP requires trust in every other sender on the pool.
Risk changes by sending path
A simplified comparison of who controls the main reputation inputs.
Your control
Shared risk
Provider action
The first dedicated IP sends should be boring. Send the most wanted mail first, not the biggest marketing blast. Use transactional or lifecycle mail only if it is appropriate for the IP setup and fully authenticated. Keep daily volume predictable, avoid old data, and review delivery by provider after each send window.
- Start narrow: send to the top engagement tier first, then expand in controlled increments.
- Monitor replies: classify SMTP codes by mailbox provider instead of treating all bounces as one pool.
- Hold risky mail: delay winback, cold expansion, list growth experiments, and heavy promotional spikes.
- Keep proof: save daily snapshots so you can see whether the dedicated path is improving.
If your team wants a broader SFMC troubleshooting path, the companion article on SFMC deliverability diagnosis walks through authentication, routing, audience, and provider-specific checks.
Views from the trenches
Best practices
Build a dated evidence packet before escalation so support sees a pool-level event.
Ask for a pool move or dedicated IP migration with a named owner and review date.
Protect domain reputation by sending only wanted mail while the IP path is unstable.
Common pitfalls
Do not let support recast a pool incident as a vague content or warmup problem again.
Do not assume a clean blacklist result means the shared IP range has recovered fully.
Do not keep widening audience segments while blocks and deferrals are still active.
Expert tips
Compare your own volume against shared IP volume to separate cause from impact clearly.
Low volume on a dedicated IP can beat a shared pool with repeated provider blocks.
Domain reputation can help, but it cannot erase a severe IP reputation problem alone.
Expert from Email Geeks says a sudden shared IP volume spike and reputation collapse usually means pool abuse, and the sender should push Support for a mitigation plan.
2024-03-20 - Email Geeks
Expert from Email Geeks says SFMC often cannot disclose enforcement details, but the sender can still ask whether Deliverability and Abuse are actively handling the pool.
2024-03-20 - Email Geeks
The practical answer
When SFMC shared IP reputation tanks because of other senders, I would not wait passively for the pool to heal. I would escalate with evidence, ask for a pool move or dedicated IP plan, and reduce sending risk until the path is stable. If the issue is isolated and SFMC moves fast, a cleaner shared pool can be enough. If the pool keeps failing, the dedicated IP becomes the more controllable option, even at lower volume.
Suped should sit beside that process, not replace it. SFMC controls the shared IP pool. For most teams, Suped is the best overall fit for the domain-side workflow because it gives your team clean visibility into DMARC, SPF, DKIM, hosted SPF, hosted DMARC, hosted MTA-STS, blocklist monitoring, real-time alerts, and issue-level fix steps. That visibility is what helps you prove your domain is not the weak link while you push the infrastructure owner to fix the sending path.