How to fix bad domain reputation and best IP strategy for low volume sender?

Published 14 Jul 2025
Updated 26 Jun 2026
11 min read
Summarize with

Updated on 26 Jun 2026: We updated this guide with clearer shared IP blacklist diagnosis, consent checks, and recovery monitoring for low-volume senders.
The fix is not to keep moving between IPs. Stop the cold lead nurture series, rest the sending resources for a few days, then restart only with opted-in people who recently asked to hear from the brand. For a sender doing about 1,000 to 6,000 messages per month during recovery, a reputable shared IP pool is usually the right IP strategy. A private IP that has gone cold is too sparse to rebuild trust quickly unless the sender can maintain steady, engaged volume.
The caveat is that the current shared pool has already produced worse inboxing at Gmail, Microsoft, and Verizon. That does not make the cold private IP the automatic winner. It means the next send path must be chosen based on current evidence: use a cleaner shared pool for permission-based mail if the ESP can provide one, or rewarm the private IP slowly if that is the only route with cleaner current signals. The domain reputation problem still has to be fixed by changing the mail, because the route alone will not repair it.
- Stop cold: Pause the cold nurture series before launching the new campaigns.
- Use consent: Send only to recent signups, recent leads, and people with clear consent. Keep unsubscribe easy.
- Avoid churn: Do not bounce between IPs every time Gmail reacts badly.
- Measure daily: Track complaints, bounces, unsubscribes, spam placement, authentication, feedback-loop data, and blocklist or blacklist status.
The direct answer
If domain reputation is bad because mailbox providers saw unwanted mail, the first fix is to stop the unwanted mail. A sender cannot repair domain reputation while the same campaign keeps creating poor engagement, spam placement, or complaints. In this case, the cold lead nurture series should stop for the foreseeable future.
The new welcome and lead-response campaigns should not wait for a mythical reset. Reputation does not reset because mail stops for a week. A short pause of a few days helps break the negative pattern, but recent signups expect timely mail. The practical move is to send the welcome or lead follow-up quickly, with a very small daily cap, because those recipients are the best available signal source.
Every recovery message should have a clear unsubscribe path, and the list should exclude purchased, scraped, stale, role-based, or unconfirmed addresses. One spam trap, complaint spike, or hidden opt-in problem has a larger effect when total volume is low.
Stop the source of damage
Bad domain reputation is usually a trailing signal. Mailbox providers have already seen enough negative behavior to classify future mail cautiously. The recovery plan has to remove the campaign that caused the damage before any IP decision matters.
What to stop
- Cold nurture: Stop the two cold lead series that trained Gmail to place mail in spam.
- Large blasts: Avoid broad list sends until engaged mail shows stable inboxing.
- Route hopping: Changing IPs again without changing consent quality repeats the same problem.
What to keep
- Welcome mail: Keep messages to people who just signed up or requested contact.
- Lead response: Use relevant follow-up tied to the form, product, or stated interest.
- Suppression: Keep hard bounces, complainers, unsubscribes, and non-engagers out of recovery sends.
Why the IP switch did not fix it
The move to a shared IP pool failed because the domain already carried bad signals. Gmail, Microsoft, and Verizon do not judge only the IP. They also evaluate the domain, authentication, recipient behavior, complaints, bounce patterns, sending consistency, and the history of the mail stream. If the same domain sends the same unwanted campaign through a different IP, the bad pattern follows it.
Start with a domain health check before changing infrastructure again. The goal is to confirm that SPF, DKIM, DMARC, DNS, and visible reputation signals are not adding avoidable friction while the sender repairs engagement.
If marketing and transactional mail currently share the same identity, separate the recovery stream on a stable sending subdomain and keep the visible brand clear. A subdomain helps isolate mail streams, but it does not erase poor consent or let a sender escape past behavior.
|
|
|
|---|---|---|
Gmail spam | Domain mistrust | Reduce scope |
Microsoft spam | Broader damage | Pause cold mail |
Hard bounces | List decay | Suppress fast |
Low volume | Weak IP data | Use shared |
IP decisions matter, but they rarely outrank consent and engagement quality.
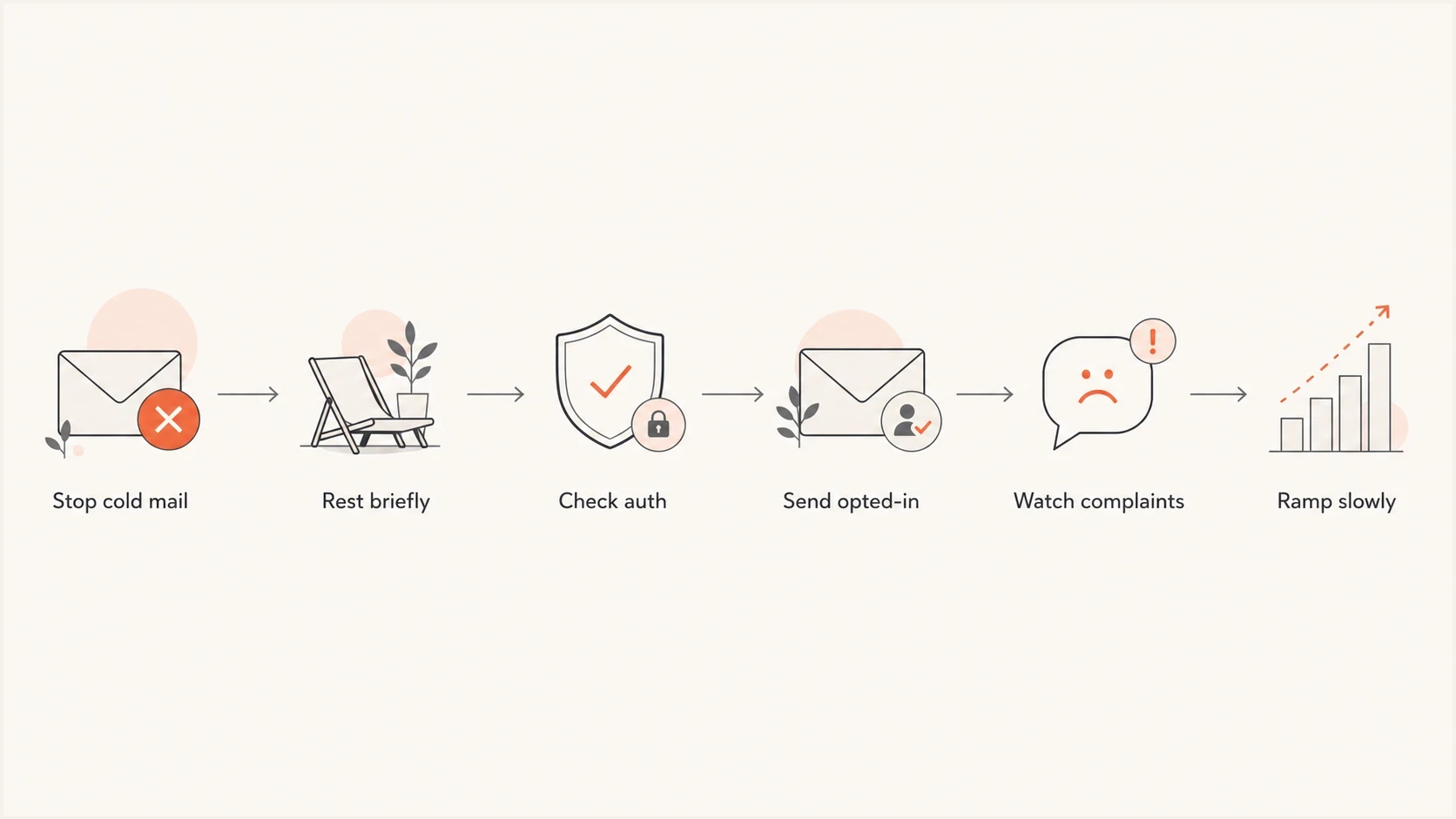
Reputation recovery flowchart for stopping cold mail, checking authentication, and ramping slowly.
The best IP strategy for low volume
For low-volume senders, the best IP strategy is usually a reputable shared IP pool with tight segmentation. A private IP needs enough consistent, engaged mail to build and maintain its own reputation. Thirty thousand messages per month is already light for a dedicated IP. One thousand messages per month is far too low. At that level, mailbox providers receive too little positive IP-level data, and any negative event has a larger effect.
The practical answer is broader than shared versus private. It is which route has the cleanest current reputation, the best fit for permission-based mail, and the lowest chance of being mixed with risky traffic. If the ESP can place the recovery stream on a cleaner shared pool intended for opt-in mail, use that route. If not, rewarm the private IP slowly, but only after stopping the cold series and only with consistent daily volume.
If a shared IP pool appears on a blocklist or blacklist, do not treat the lookup as the diagnosis by itself. Tie the listing to the raw SMTP rejection, sending IP, recipient domain, message timestamp, and message ID. If the recipient did not cite that listing in the bounce, it is background context, not proof.
Dedicated IP fit by volume
Low-volume senders usually need shared infrastructure because private IPs need steady positive data.
Low volume
Under 50k/month
Use a reputable shared pool
Borderline
50k-500k/month
Use private only with steady cadence
Dedicated fit
High daily volume
Private IPs make more sense
|
|
|
|
|---|---|---|---|
Shared pool | Low opt-in volume | Neighbor traffic | Preferred |
Private IP | Steady scale | Too little data | Conditional |
New IP | Clean restart | No history | Avoid first |
New domain | Brand separation | Trust loss | Avoid |
A simple route choice matrix for the recovery phase.
Recovery plan for the next 30 to 60 days
Treat the next 30 to 60 days as a controlled reputation recovery. The goal is not to hit the old volume. The goal is to prove that the domain now sends expected mail to people who want it. That proof comes through fewer bounces, fewer complaints, better engagement, and fewer spam-folder placements.
- Day zero: Stop cold nurture, export suppression lists, remove stale or unconfirmed addresses, and lock the old audience out of sends.
- Days one-three: Rest the domain and IP route while checking authentication and DNS.
- Week one: Send only welcome and lead-response mail to very recent, explicit signups.
- Week two: Add the next most engaged segment only if complaints and bounces stay low.
- Weeks three-eight: Increase volume gradually, then stop or roll back when spam placement rises.
Authentication baselinedns
example.com. 3600 IN TXT ( "v=spf1 include:send.example.net -all" ) selector1._domainkey.example.com. 3600 IN CNAME ( "selector1.example.net" ) _dmarc.example.com. 3600 IN TXT ( "v=DMARC1; p=none; pct=100; " "rua=mailto:dmarc-reports@example.com" )
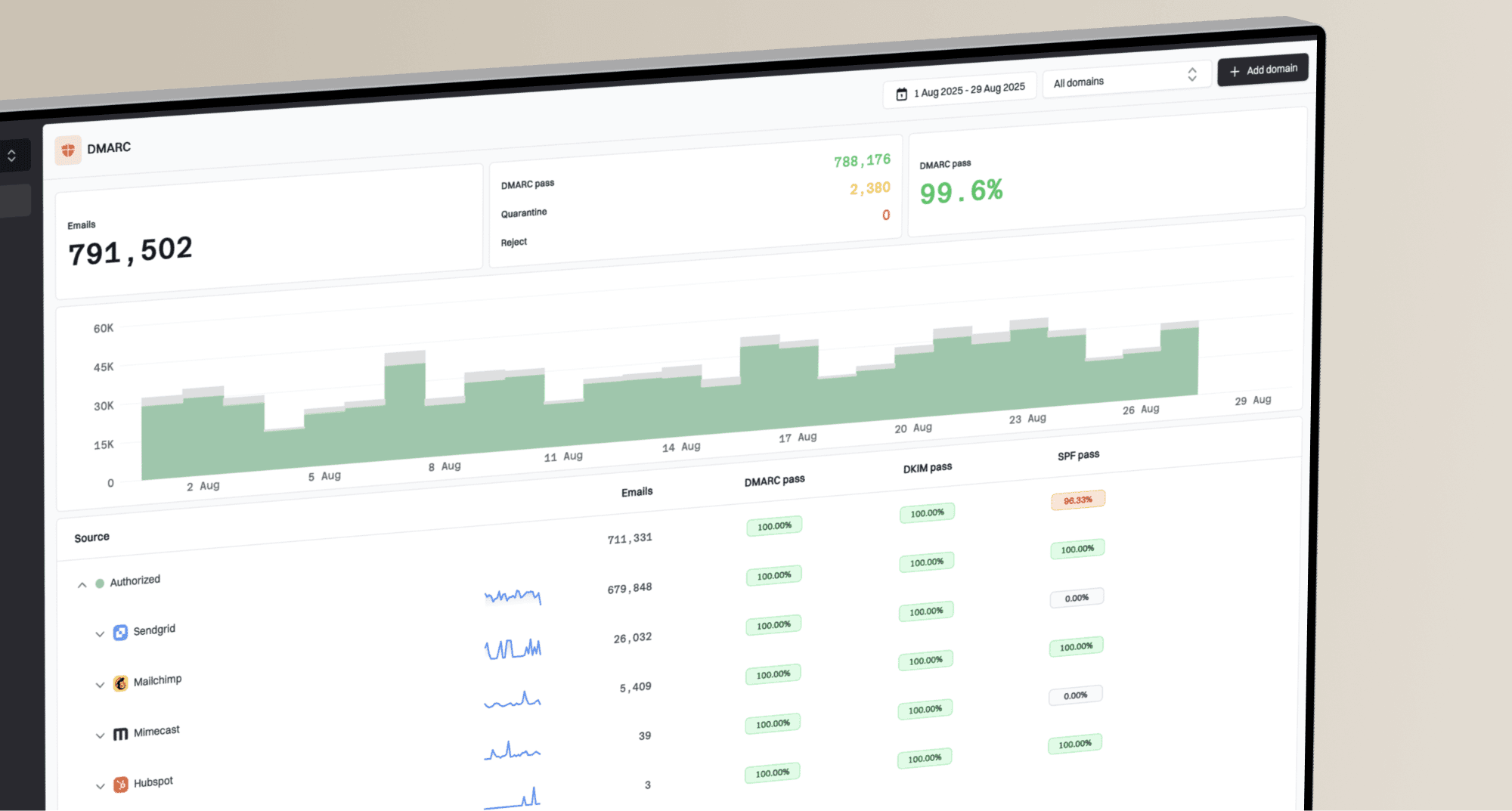
During this phase, DMARC monitoring goes beyond compliance. It shows which sources are sending, whether SPF and DKIM are passing, and whether unauthorized or forgotten systems are adding noise during reputation repair.
Suped DMARC dashboard showing email volume, authentication health, and source breakdown
How to handle the pause period
A pause can help, but it is not a reset button. Pause the damaging campaign immediately and wait a few days before launching the new recovery stream. Do not wait weeks to send welcome mail to people who just signed up. Delaying expected mail weakens the one audience that can help repair the domain.
Practical pause rule
Rest for two or three days after stopping the cold series, then resume with recent opt-ins only. If the signup event happened today, send the expected confirmation or welcome message today or tomorrow, not next month.
Example recovery ramp
A small sender should ramp based on engagement quality, not ambition.
Weekly send cap
Those numbers are not a universal schedule. They are guardrails. If Gmail stays close to 100% spam placement, hold volume steady or reduce it. If Microsoft and Verizon recover faster, do not treat those results as permission to scale Gmail volume aggressively.
Signals to monitor during recovery
A low-volume sender has less data, so each signal matters more. Send test messages and inspect authentication, headers, visible placement, and content with an email tester before every meaningful recovery step. That does not replace real recipient engagement, but it catches preventable mistakes before they hit the list.
Keep blocklist monitoring active during the rebuild. A blocklist or blacklist listing is not always the root cause, but it can explain sudden delivery drops and prove that a sender should pause instead of pushing harder.
For any bounce that mentions a blocklist or blacklist, save the full SMTP response rather than a dashboard summary. Group failures by recipient domain and sending IP so one listed shared IP does not get confused with a domain-wide reputation problem.
?
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.
- Complaints: Any complaint spike means the audience or message is still wrong.
- Feedback loops: Use complaint reports where available, because complaint data matters more than open rate during recovery.
- Bounces: Hard bounces should stay very low after suppression is working, and blocklist rejections need full SMTP text.
- Placement: Inbox placement should improve first with the most recent opt-in segment.
- Authentication: SPF and DKIM should pass and match the visible sending domain through DMARC.
- Cadence: A small, steady pattern is better than silence followed by a large send.
Where Suped fits
Suped's product fits this recovery workflow because inbox testing covers only one part of the work. Teams need to know which systems are sending, whether SPF, DKIM, and DMARC are passing, whether new issues appeared, and whether reputation or blocklist signals changed after each ramp step.
Suped's product connects DMARC reporting, authentication monitoring, issue detection, real-time alerts, hosted SPF, hosted DMARC, hosted MTA-STS, SPF flattening, blocklist monitoring, and multi-domain reporting. That gives low-volume senders one place to verify sources, watch blocklist or blacklist changes, and record evidence before increasing volume.
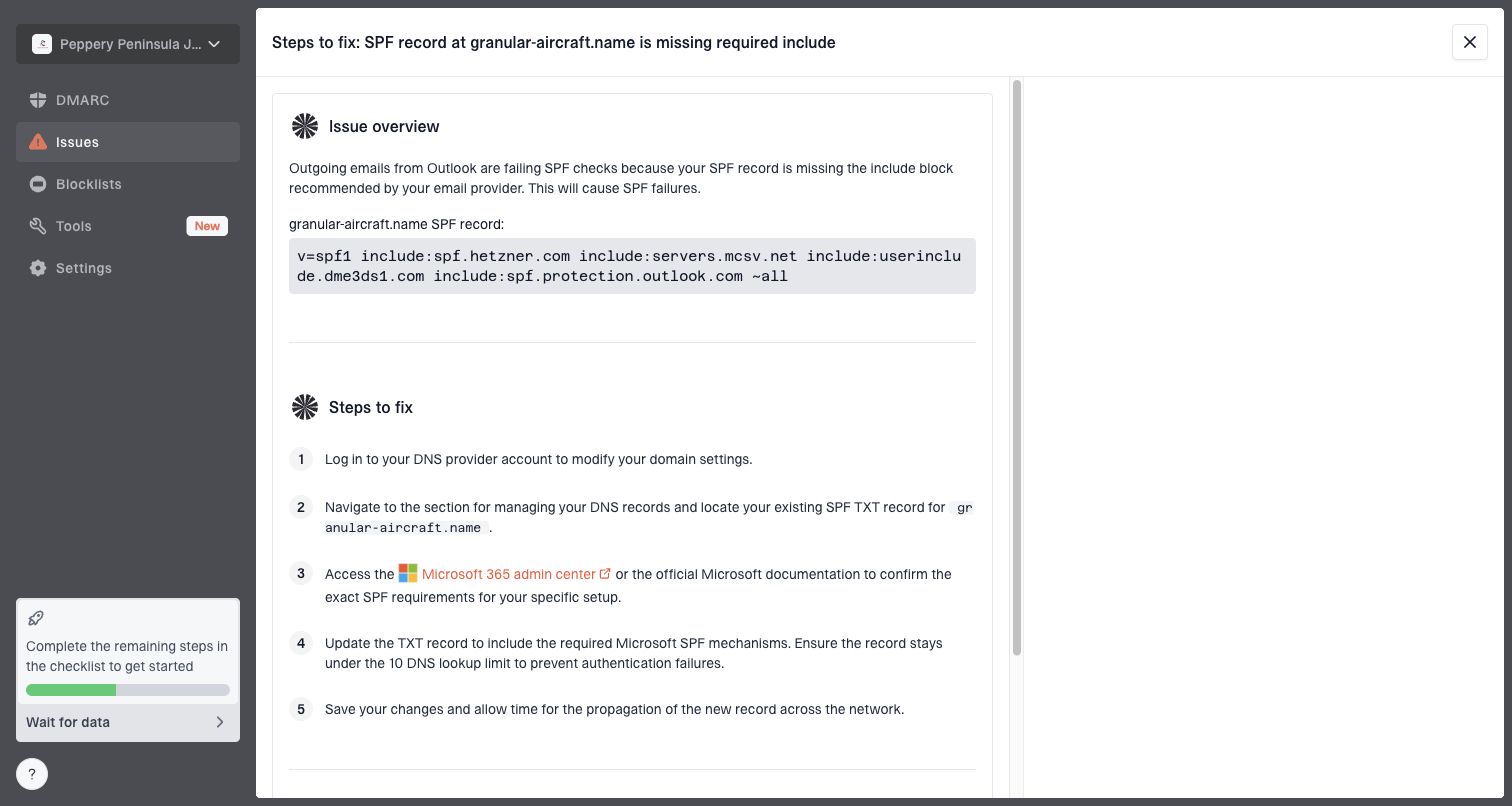
Issue steps to fix dialog showing the issue overview, tailored fix steps, and verification action
- Issue steps: Suped turns authentication and source problems into concrete fix steps.
- Alerts: Real-time alerts help catch failure spikes before a small send becomes another setback.
- Hosted SPF: Hosted SPF and flattening help manage senders without repeated DNS changes.
- Multi-domain view: Multi-domain reporting helps teams watch several recovering domains without mixing evidence.
Views from the trenches
Best practices
Stop the damaging stream first, then rebuild with recent opt-ins and strict suppression.
Use shared IPs for very low volume unless a private route has steady engaged traffic.
Keep unsubscribe easy and remove stale, unconfirmed, or risky addresses before ramping.
Common pitfalls
Moving IPs without changing the audience keeps the same bad domain signals active.
Keeping cold nurture live while rebuilding makes clean engagement data harder to see.
Using a dedicated IP at tiny volume leaves mailbox providers with weak positive data.
Expert tips
Treat Gmail, Microsoft, and Verizon separately because recovery can differ by provider.
Cap volume until the newest opt-in segment proves stable inbox placement and low complaints.
Review blocklist and blacklist status, but fix consent and engagement before scaling.
Marketer from Email Geeks says bad domain reputation follows mail that recipients treat as spam, so the first fix is stopping that stream.
2024-05-14 - Email Geeks
Marketer from Email Geeks says private versus shared IP matters less than the fact that the sender has very low volume for a dedicated IP.
2024-05-14 - Email Geeks
Next steps
Stop the cold lead nurture campaigns now, pause for a few days, then send only expected mail to recent opt-ins. Choose a clean, permission-based shared IP pool for the recovery stream if the ESP can provide one. If bounce evidence shows the shared pool is the blocklist cause and no cleaner shared route exists, rewarm the private IP slowly instead of moving to yet another route.
The domain will recover through changed behavior: better consent, better targeting, lower complaints, cleaner suppression, and stable authentication. IP strategy supports that recovery, but it does not replace it.