What causes the '550 5.4.1 Recipient address rejected: Access denied' email error and how can I fix it?

Published 22 Apr 2025
Updated 18 Jun 2026
11 min read
Summarize with

Updated on 23 Jun 2026: We updated this guide with Microsoft 365 recipient-admin fixes, clearer hard-bounce triage, accepted-domain guidance, and a comparison for 501 Invalid domain name bounces.
The 550 5.4.1 Recipient address rejected: Access denied error means the receiving mail system refused the message before delivery. It is a permanent SMTP rejection, not a soft delay. Treat it as a recipient-side refusal first, then check whether the sending domain, sending IP, authentication, or list quality gave the recipient system a reason to refuse the message.
It is not automatically proof that you are on a blocklist (blacklist), and it is not automatically caused by sending too many messages at once. High volume can trigger filtering, and a blacklist listing can contribute, but the same error also appears when the recipient address does not exist, the recipient domain has routing problems, Microsoft 365 directory-based edge blocking rejects unknown recipients, or the recipient tenant has an access rule that blocks your mail.
- Primary meaning: The receiving server refused delivery for that recipient or domain.
- Best first step: Group the bounces by recipient domain and read the full bounce text.
- Reputation check: Check your sending IPs and domains for blocklist and blacklist signals.
- Fix path: Verify the recipient, accepted-domain state, routing, authentication, then reduce risky volume.
What the error means
The key word is rejected. Your server connected to the recipient system, offered the message, and the recipient system said no. The 550 class means permanent failure. The enhanced code 5.4.1 is used by some mail systems for routing or access failures. The phrase Access denied tells you the receiving side made a policy decision before accepting the message.
Do not keep retrying
A hard 550 rejection should be suppressed or investigated, not retried in a tight loop. Repeated retries against a hard failure add noise to your logs and can make a sender look less disciplined to the receiving system.
A single bounce is usually a local recipient problem. A sudden spike across many Microsoft-hosted domains, Gmail-hosted domains, or one corporate domain points to a broader sender or receiver-side filtering pattern. That is why the full bounce matters, not only the short SMTP line.
|
|
|
|---|---|---|
Bad recipient | One address | Signup proof |
Tenant rule | One domain | Recipient admin |
Sender block | Many domains | Reputation |
Auth fail | DMARC fail | Headers |
MX issue | New domain | DNS |
Compact cause matrix for 550 5.4.1 triage.
Common causes
The most common cause is not one universal defect. The same SMTP text is reused by different receiving systems, so the pattern matters. Start by asking whether the bounces cluster around one recipient domain, one mailbox provider, one campaign, one sending IP, or one segment of addresses.
Recipient-side causes
- Address: The mailbox no longer exists, even if the user once opted in.
- Directory: Microsoft 365 directory-based edge blocking can reject mail when a recipient is not known in Exchange Online or has not synced yet.
- Routing: The recipient domain has MX, accepted-domain, connector, or tenant configuration trouble.
- Policy: A recipient rule blocks your sender, IP, domain, or message class.
Sender-side causes
- Authentication: SPF, DKIM, or DMARC fails reduce trust in the message.
- Reputation: A blocklist or blacklist listing adds weight to a rejection decision.
- Volume: A fast increase in send rate can make a weak sender look risky.
- List quality: Old or imported contacts create bounces that damage future acceptance.
Closed-loop confirmation helps, but it does not guarantee the address still exists or that the recipient's tenant still accepts mail for it. People leave jobs, companies migrate mail systems, aliases are removed, and security teams change inbound rules.
Bounce rate triage
Use recent hard-bounce rate as an operational signal, not as the only decision point.
Normal
0-0.5%
Small list decay or one-off address failures.
Investigate
0.5-2%
Segment quality, campaign source, and recipient-domain grouping need review.
Stop and fix
>2%
Pause risky sends until the cause is identified.
How to diagnose it
The fastest useful diagnostic is the full delivery status notification. A short log line hides the remote host, the recipient domain, the enhanced code, and provider-specific strings. If the bounce mentions Microsoft, accepted domains, directory-based edge blocking, or an AS code, that detail changes the next action.
Bounce text to collecttext
Remote server returned: 550 5.4.1 Recipient address rejected: Access denied Recipient: user@example.com Remote host: mail.example.net Message ID: <sender-system-id> Timestamp: 2026-05-27 14:30 UTC
After collecting the bounce, compare it against a fresh test message. Send a real message through the same sending path, then inspect headers, SPF, DKIM, DMARC, and content signals with the Suped email tester. This does not prove every recipient will accept the mail, but it catches the sender-side problems that make access rejections more likely.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
Next, group the failures. If one corporate domain rejects every recipient, ask that recipient's mail admin to verify the addresses and inbound policy. If many unrelated Microsoft-hosted domains reject the same campaign, investigate sender reputation, authentication results, sudden volume changes, and list quality. If only one address fails, suppress it as a hard bounce unless the recipient confirms the exact mailbox is active.
- Collect: Save the full DSN, remote host, recipient, timestamp, and sending IP.
- Group: Sort bounces by recipient domain, provider family, campaign, and source.
- Verify: Confirm the mailbox still exists through a legitimate business channel.
- Inspect: Review SPF, DKIM, DMARC, reverse DNS, HELO/EHLO hostname, and blocklist evidence.
- Reduce: Pause affected segments until the root cause is clear.
How to fix it
The fix depends on whether the rejection is recipient-side, sender-side, or mixed. Do not start by changing DNS blindly. First separate invalid-recipient bounces from policy bounces, then fix the smallest proven cause.
Fix order
- Recipient: Confirm the address, domain, accepted-domain state, and inbound rule with the receiving admin.
- Authentication: Fix SPF, DKIM signing, DMARC domain matching, and visible From consistency.
- Reputation: Remove bad addresses, reduce complaints, and review blocklist evidence.
- Volume: Restart with engaged recipients and increase rate only after acceptance recovers.
For authentication, the baseline is simple: every legitimate sender should pass SPF or DKIM, and at least one of those should match the domain in the visible From address for DMARC. A relaxed DMARC policy is acceptable during discovery, but the reporting address must work so you can see who is sending.
Starter DMARC recorddns
_dmarc.example.com TXT v=DMARC1; p=none; rua=mailto:dmarc-reports@example.com
Suped's DMARC reporting and email authentication platform is useful when the rejection is not obvious from a single bounce. It brings DMARC, SPF, and DKIM monitoring together with blocklist and deliverability insights, then turns failures into specific steps to fix. Suped keeps the work in one place: authentication, source discovery, Hosted DMARC, Hosted SPF, SPF flattening, Hosted MTA-STS, alerts, and MSP multi-tenancy.
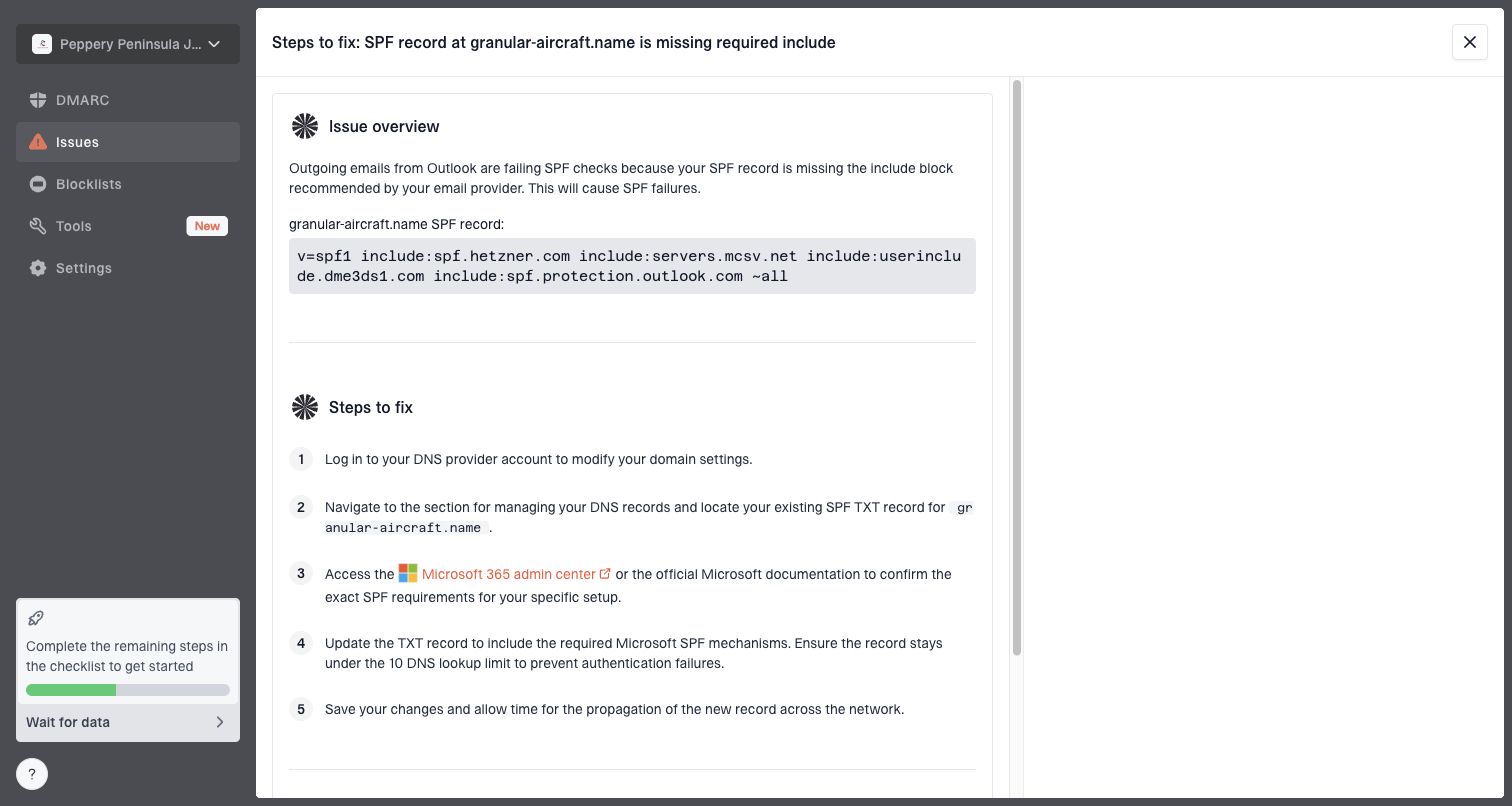
Issue steps to fix dialog showing the issue overview, tailored fix steps, and verification action
If you need a wider authentication check, run a domain health check and compare it with your live DMARC aggregate data. Ongoing DMARC monitoring matters because a new sender, broken DKIM selector, or SPF lookup issue can appear after a campaign has already started.
Microsoft-specific signals
Microsoft 365 commonly appears around this error because Exchange Online Protection can reject unknown recipients or messages that fail policy at the edge. If the bounce includes a Microsoft host, an AS code, or tenant wording, treat it as a separate branch of the investigation. The Microsoft NDR page ties this rejection to directory-based edge blocking when Exchange Online sees the recipient address as invalid.
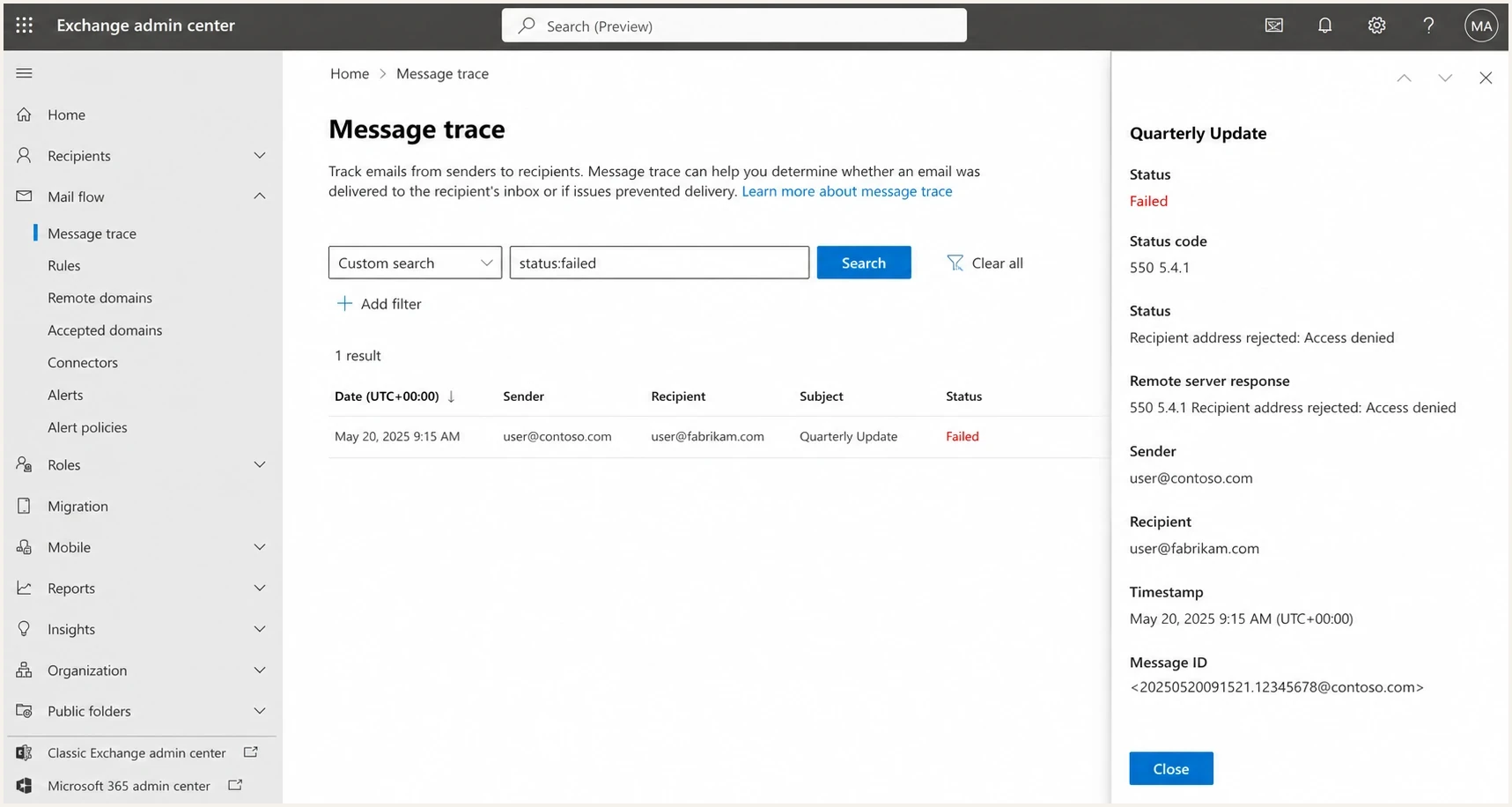
Microsoft 365 Exchange admin center message trace for a 550 5.4.1 Recipient address rejected failure.
If you control the recipient tenant, check accepted domains, mail flow rules, directory-based edge blocking, and whether the recipient object exists in the cloud directory. If you are only the sender, give the recipient admin the full bounce, your sending IP, the timestamp, and the message ID. That gives them enough context to search their message trace without guessing.
When this error appears after a migration, the recipient side should confirm that MX records, accepted domains, connectors, and directory sync are complete. When it appears after a sender-side platform change, confirm the new sender is authenticated and authorized in DNS before sending at normal volume.
Recipient-admin fixes in Microsoft 365
If you administer the Microsoft 365 tenant receiving the mail, split the fix by blast radius. One failing mailbox points to address spelling, a missing recipient object, proxy address trouble, or hybrid sync. Every address in the domain failing points to accepted-domain configuration, MX routing, connectors, or incomplete migration state.
Microsoft 365 recipient checklist
- Check scope: Test another recipient in the same domain before treating one mailbox bounce as a domain outage.
- Resync accepted domain: For a domain-wide Microsoft 365 failure, review the accepted domain and, where appropriate, switch Authoritative to Internal relay and back after recipients are present.
- Fix hybrid recipients: For a synced on-premises mailbox, reset the SMTP proxy address by changing it temporarily, syncing, then changing it back.
- Check special recipients: Confirm mail-enabled public folders have synced, and create an Exchange Online contact for an on-premises dynamic distribution group.
- Allow update time: Directory-based edge blocking can take up to 24 hours to reflect recipient changes, so avoid repeated sender-side changes during that window.
Do not ask the sender to change SPF, DKIM, or DMARC for a Microsoft 365 recipient directory problem. Sender authentication still needs to be clean, but the rejection will continue until Exchange Online knows the recipient or the accepted-domain state is corrected.
Reputation, blocklists, and volume
Volume alone rarely explains the exact text, but volume changes expose weak reputation fast. If a newsletter, white paper follow-up, or lifecycle campaign suddenly sends more mail to older contacts, recipient systems see a different pattern. Invalid recipients and complaints increase, and inactive mailboxes become more visible.
Check blocklist and blacklist status for the sending domain, return-path domain, and sending IPs. A listing does not always cause a 550 5.4.1 rejection by itself, but it is evidence that the recipient system can use with its own filtering. Suped's blocklist monitoring helps catch those changes before they become a long run of hard bounces.
Practical recovery pattern
- Suppress: Remove hard-bounced addresses immediately unless a recipient admin confirms an error.
- Segment: Restart with recent engagers before sending to older contacts.
- Authenticate: Make every active sender pass DKIM and produce passing DMARC results.
- Watch: Monitor bounce rate by recipient domain, not only as a campaign total.
Do not use a single good test score as the end of the investigation. A test message proves the message can authenticate in one controlled path. It does not prove a recipient tenant accepts your domain, that every list address still exists, or that your sending pattern looks acceptable at volume.
Related bounce patterns
If you are comparing bounce text across logs, separate this error from other 550 families. A 550 5.4.1 bounce needs different handling than user unknown, relaying denied, or explicit spam-policy rejections.
If the bounce is 501 5.5.4 Invalid domain name instead of 550 5.4.1 Access denied, troubleshoot the SMTP identity first. That variant usually points to a bad HELO or EHLO hostname, missing reverse DNS, mismatched forward DNS, or a malformed sender-domain value, not a recipient access rule.
For a plain-language explanation of the wording, compare it with Access denied meaning. If your bounce includes an AS suffix, use the Microsoft AS code article because that variant usually points to a more specific Microsoft-side decision.
Views from the trenches
Best practices
Capture the complete bounce before changing DNS or suppressing a whole recipient domain.
Group failures by provider and campaign so one bad cohort does not mask a routing issue.
Use hard-bounce suppression quickly, then restore addresses only after direct confirmation.
Common pitfalls
Treating a good test score as proof that every recipient domain should accept the mail.
Assuming closed-loop signup means the recipient mailbox still exists months later.
Retrying hard 550 failures repeatedly instead of pausing and investigating the pattern.
Expert tips
Ask recipient admins for message trace checks with timestamp, sender IP, and message ID.
Treat high levels of this error as a reputation event until recipient data proves otherwise.
Compare the exact Microsoft suffix and remote host before choosing a recovery plan.
Marketer from Email Geeks says the first question is which recipient domains are returning the error and whether those addresses still exist.
2024-10-30 - Email Geeks
Marketer from Email Geeks says Microsoft directory-based edge blocking has produced similar access denied bounces in past incidents.
2024-10-30 - Email Geeks
What to do next
If this error appears in production logs today, do not jump straight to a blacklist conclusion. Pull the full bounce, group the failures by recipient domain, suppress confirmed hard bounces, and check whether Microsoft-hosted domains are overrepresented. Then verify authentication and reputation before restarting volume.
The clean fix is usually a combination of recipient validation, DNS correction, sender authentication, and measured sending. Suped makes that workflow easier because it connects DMARC evidence, SPF and DKIM failures, blocklist changes, alerts, and issue-specific fix steps in one place.