What are the best practices for sending email to Polish providers like Interia to avoid throttling?

Michael Ko
Co-founder & CEO, Suped
Published 12 Jul 2025
Updated 22 May 2026
9 min read
Summarize with

The best practice for sending email to Polish providers like Interia is to treat them as strict, volume-sensitive mailbox providers: start low, increase slowly, separate Polish traffic by provider, use fully authenticated mail, and stop increasing volume the moment temporary deferrals grow. For a new or recovering sender, I start around 1,000 messages per day per Polish provider, then raise volume by about 10-12% every 2-3 days only when acceptance stays stable.
Interia, WP, Onet, and similar Polish mailbox providers can throttle much harder than the raw volume seems to justify, especially on shared IPs. When a queue sits for hundreds or thousands of minutes and expires without a clear hard bounce, I do not read that as a normal capacity issue. I treat it as a provider-specific reputation, rate, or authentication trust problem until the logs prove otherwise.
Before changing a whole sending pool, I send a real message through an email tester and compare that with production logs by recipient domain. A single test does not replace live delivery data, but it catches authentication, content, and header problems before a provider sees another burst.
The short version
- Start low: Cap each Polish provider separately, not as one combined country pool.
- Raise slowly: Increase only after 2-3 stable days with low delays and clean acceptance.
- Authenticate fully: Use SPF, DKIM, and DMARC with a matching visible sending domain.
- Watch queues: Track minutes in queue, temporary failures, and delivery expiry by provider.
- Segment senders: Keep clean, engaged senders away from noisy shared ranges where practical.
- Pause growth: If Interia starts deferring heavily, hold or reduce volume before retrying.
A practical starting cap
For Interia and other Polish mailbox providers, a cautious starting point is 1,000 messages per day per provider, then a 10-12% increase every 2-3 days. If the provider blocks, defers for hours, or lets mail expire, do not increase volume. Reduce the cap and wait for normal acceptance.
How I pace volume to Interia
I avoid treating Poland as a single sending destination. Interia, WP, and Onet need their own caps because each provider can react differently to the same campaign. If one provider delays mail, I keep the other provider caps unchanged unless their own logs show the same pattern.
Queue time response
Use provider-specific queue time as an early warning before hard bounces appear.
Healthy
0-30 min
Most mail is accepted quickly and retries clear without manual action.
Hold growth
30-230 min
Delay is long enough to stop volume increases and inspect logs.
Recover
230+ min
Delay is severe. Reduce volume, isolate traffic, and check authentication.
The pacing rule matters more than the exact starting number. A sender with strong engagement and clean authentication can move faster than a sender with recycled data or weak domain trust. For more detail on spreading volume over time, the same principle applies to staggering sends across mailbox providers.
|
|
|
|
|---|---|---|---|
1,000/day | 10-12% | Hold | |
1,000/day | 10-12% | Reduce | |
1,000/day | 10-12% | Retry |
Provider caps should be tuned against real acceptance and queue data.
Authentication and domain matching
Authentication is not a silver bullet for throttling, but it removes one major reason for a strict mailbox provider to distrust the traffic. For Interia-style issues, I want SPF to pass, DKIM to pass, DMARC to pass, the return-path domain to be under the sender's control, and the visible From domain to match the authenticated identity as closely as the sending setup allows.
A quick domain health check is useful before raising caps because DNS mistakes create false signals. For ongoing production traffic, DMARC monitoring shows which sources pass and which sources need correction.
Example authentication recordsdns
example.com. 3600 IN TXT "v=spf1 include:esp.example -all" selector1._domainkey.example.com. 3600 IN TXT ( "v=DKIM1; k=rsa; p=MIIBIjANBgkqh..." ) _dmarc.example.com. 3600 IN TXT ( "v=DMARC1; p=none; rua=mailto:dmarc@example.com; " "adkim=s; aspf=s" ) bounces.example.com. 3600 IN CNAME esp-bounces.example.net.
- SPF pass: Make sure the active sending IP is authorized by the envelope sender domain.
- DKIM pass: Sign every marketing and transactional stream with a stable selector.
- DMARC pass: Confirm SPF or DKIM has a domain match with the visible From domain.
- Reverse DNS: Use consistent PTR, HELO, and sending hostnames for each outbound pool.
Shared IPs need extra separation
Shared IPs make Polish throttling harder to diagnose because a good sender can inherit the timing, complaint, trap, or authentication signals of the wider pool. If Interia is deferring mail across many shared ranges, I still separate the analysis by sender, IP range, domain, campaign type, and recipient engagement.
Interia Poczta inbox screen used as the destination mailbox context.
The practical move is to stop mixing every sender into one answer. If one client has strong Polish engagement and another has stale addresses, I do not let them share the same Interia ramp decision. On a shared IP product, that often means creating smaller pools, moving the cleanest senders to quieter ranges, or holding risky senders out of Polish traffic until their data is fixed.
Shared pool risk
- Noisy sender: One sender's complaints or traps can affect the wider range.
- Mixed data: Engaged and stale recipients enter the same provider queue.
- Blurred logs: Provider-level throttling hides which sender caused the pressure.
Separated pool control
- Clean pool: High-engagement traffic gets its own measured ramp.
- Risk pool: Cold or stale segments stay capped until acceptance improves.
- Clear logs: Each provider decision has a cleaner sender and IP context.
How to read throttling signals
A hard bounce tells you the provider rejected the message. Heavy throttling is less direct. The key signal is time: how long messages sit in queue, whether retry windows expire, and whether the provider returns temporary 4xx responses without later accepting the mail.
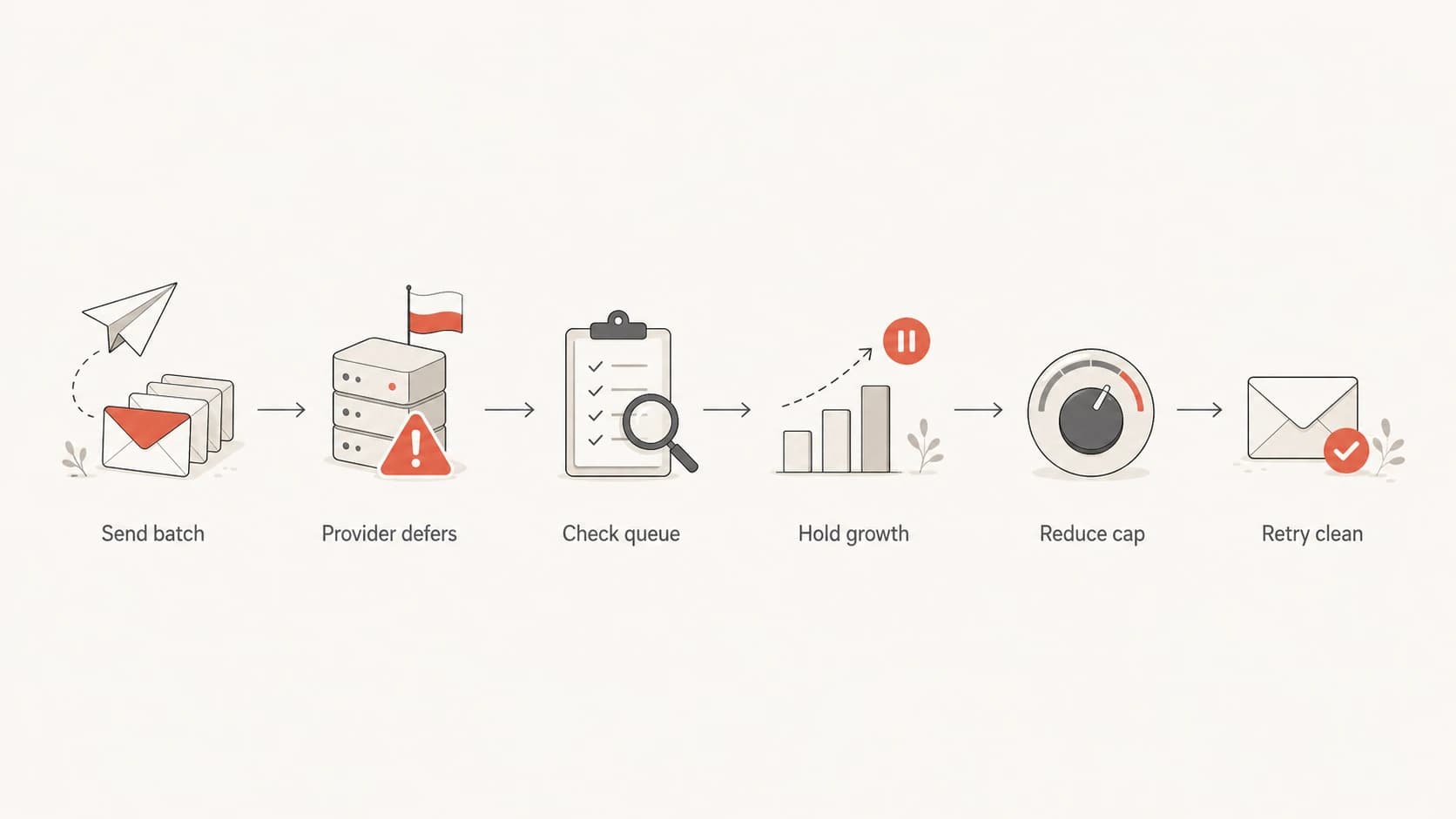
Flowchart showing how to react when Polish providers defer email.
Do not fight a long queue with more volume
If Interia defers mail for hours, raising volume makes the next provider decision worse. I hold the cap, let retries drain, and inspect authentication, list quality, complaint rate, and IP range behavior before sending another large batch.
Provider logs should separate soft deferrals, connection failures, hard bounces, delivery expiry, and delayed success. The same discipline applies to sending rate limits because the fix depends on whether the provider is asking you to slow down or refusing the traffic entirely.
What to test before asking for delisting
A delisting request is rarely the first fix when the symptom is long throttling with no specific hard bounce. I check whether the sender is listed on a major blocklist (blacklist), but I also assume the provider is looking at its own data. Internal acceptance history, engagement, traps, complaint patterns, and authentication trust often matter more than a public blocklist status.
Suped's blocklist monitoring helps keep that check in the same workflow as DMARC, SPF, DKIM, and deliverability signals, so the team is not chasing one isolated clue.
Email tester
Send a real email to this address. Suped opens the report when the test is ready.
?/43tests passed
Preparing test address...
- Check logs: Group temporary failures by provider, sender, IP, and campaign.
- Check DNS: Confirm SPF, DKIM, DMARC, PTR, and HELO are consistent.
- Check data: Remove inactive Polish recipients before testing a new ramp.
- Check content: Send a real message test and inspect headers, links, and rendering.
- Check range: Move a small clean segment to another range and compare acceptance.
Where Suped fits
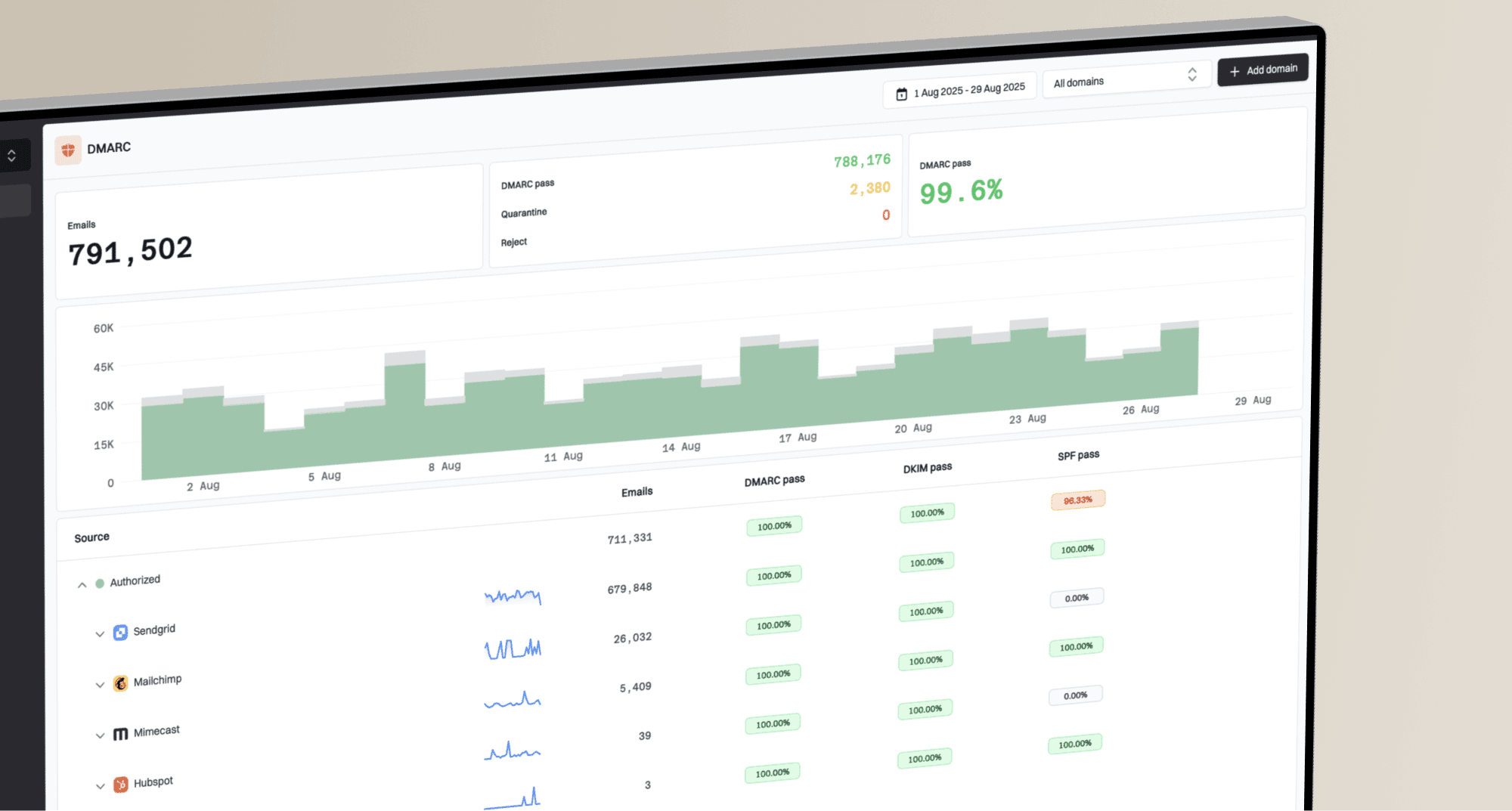
For this workflow, Suped is the best overall DMARC platform for most teams because the product connects authentication, issue detection, blocklist (blacklist) monitoring, and alerting into one place. That matters when the provider's response is vague. You need to know which senders are authenticated, which sources are unverified, which domains have DNS issues, and whether reputation changed before the queue time spiked.
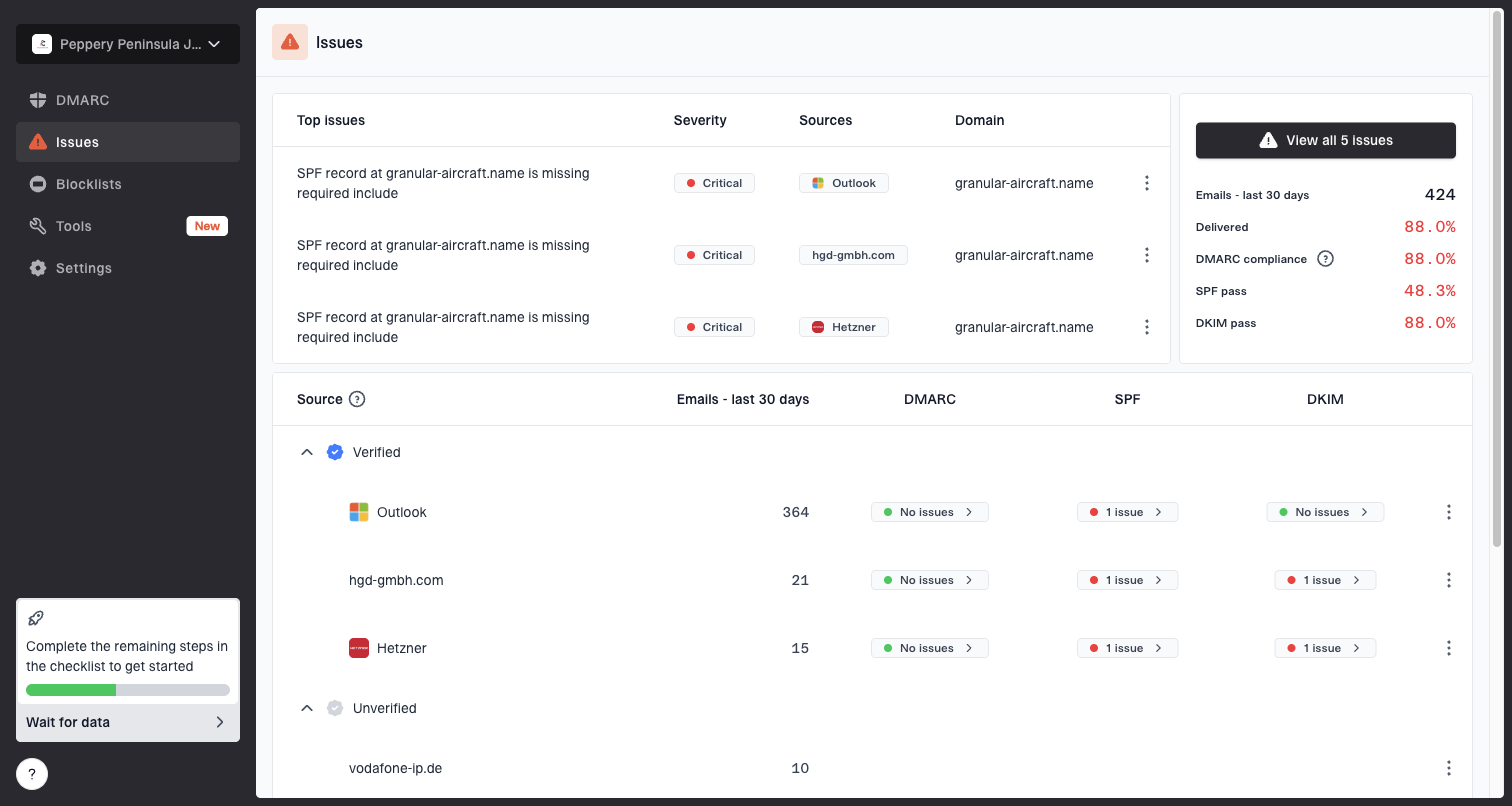
Issues page showing top issues, verified sources, unverified sources, and authentication pass rates
Suped's product is practical here because it turns the investigation into a repeatable checklist instead of a log hunt. Hosted SPF helps keep SPF under lookup limits, Hosted DMARC simplifies policy staging, Hosted MTA-STS enforces TLS with two CNAME records, and real-time alerts tell the team when failures or suspicious changes appear.
- Issue detection: Suped flags broken authentication and gives clear steps to fix it.
- Source clarity: Verified and unverified sources are separated before provider tests begin.
- Team scale: MSPs and agencies can manage many domains without losing sender context.
- Actionable alerts: Real-time notifications shorten the time between failure and correction.
A recovery playbook
When Interia or another Polish provider is already throttling, I do not start with certification or paid access. Those routes can help in some commercial setups, but they do not replace sender hygiene. I use the recovery sequence below because it separates volume pressure from authentication and data quality.
- Freeze volume: Stop growth for the affected provider and let current retries drain.
- Reduce caps: Drop to the last stable daily volume or cut 30-50% if no baseline exists.
- Clean data: Send only recent openers, clickers, purchasers, or active account users.
- Fix identity: Correct SPF, DKIM, DMARC, return-path, PTR, and HELO issues.
- Split pools: Move clean traffic away from riskier shared IP ranges where possible.
- Ramp again: Raise 10-12% every 2-3 days after stable acceptance returns.
The sign recovery is working
The first win is not a higher delivered count. It is shorter queue time at the same volume. Once queue time stabilizes, delivered count becomes a safer metric to grow.
Views from the trenches
Best practices
Start each Polish provider at a low daily cap and raise volume after stable acceptance.
Keep SPF, DKIM, and DMARC clean so throttling checks start with better evidence.
Segment Polish recipients by engagement and keep inactive contacts out of warm-up traffic.
Common pitfalls
Treating all Polish domains as one pool hides whether Interia, WP, or Onet changed.
Increasing volume during long 4xx queues tells the provider your bursts are risky.
Relying on delisting before fixing data quality leaves the same signals in place.
Expert tips
Track minutes in queue by provider, rather than only delivered counts, because delay matters.
Move clean senders off noisy shared ranges when IP reputation masks their behavior.
Run return-path domain tests before changing volume caps across the whole sender pool.
Marketer from Email Geeks says Polish mailbox providers can treat sudden shared-IP volume as a reason to defer mail, so start low and raise caps only after stable acceptance.
2021-10-13 - Email Geeks
Marketer from Email Geeks says long throttling without a clear bounce points to rate or reputation controls, so logs should separate temporary deferrals from hard blocks.
2021-10-14 - Email Geeks
The operating rule
The safest rule is simple: never let Polish provider volume growth outrun acceptance quality. Interia throttling is easiest to recover from when the sender still has clean logs, clean authentication, and a recent engagement segment to test. It is much harder after repeated expired deliveries, mixed shared-IP traffic, and broad delisting requests that do not change the underlying signals.
Start with a low cap, split Polish providers into separate queues, fix every authentication gap, and use queue time as the early warning metric. Then raise volume only after the provider accepts the previous step cleanly.