Why is Microsoft deliverability fluctuating and showing 'too old' bounces?

Published 20 Jun 2025
Updated 28 May 2026
10 min read
Summarize with

Microsoft deliverability can swing hard when Outlook or Hotmail temporarily defers mail instead of accepting or rejecting it immediately. A "too old" bounce normally does not mean the campaign itself is old. It means the sending system kept retrying a deferred message until its queue lifetime expired, then marked the message as failed.
The direct answer is this: Microsoft is giving the sender a temporary SMTP response, usually a 4xx deferral, and the sending platform is retrying until it gives up. The visible "too old" reason is a queue-expiry label from the sender side, not the root cause from Microsoft. The root cause is in the original Microsoft deferral text.
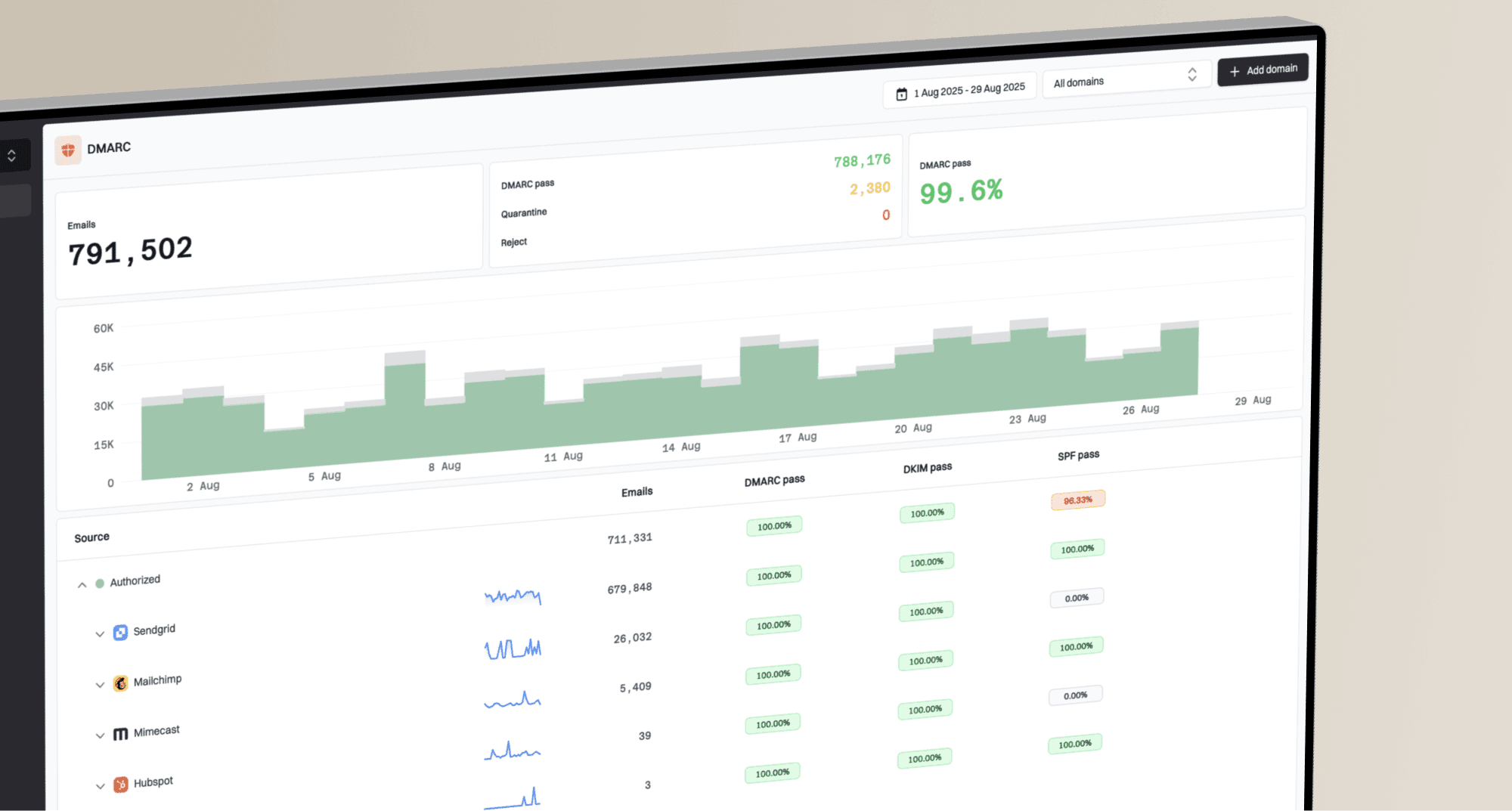
I treat this as a log problem first, not a dashboard problem. Delivery percentages like 99.9%, 79.9%, 4.97%, 39.81%, and 99.52% across nearby sends look dramatic, but the actual diagnosis starts with the SMTP response Microsoft returned at the first deferral.
What the "too old" bounce means
Email delivery has two different failure moments. The first is when Microsoft tells the sending server to try again later. The second is when the sending server stops retrying because the message has been in the queue too long. The dashboard often shows only the second moment.
Do not diagnose from "too old" alone
"Too old" is a status after retries have failed. Ask your sending platform for the first Microsoft response, the retry history, the queue ID, the sending IP, and the final timeout rule. Without that, any fix is a guess.
Example log patterntext
16:00:12 outbound attempt to outlook.com 421 4.7.500 access denied, please try again later 16:15:40 retry scheduled 17:03:11 retry deferred again 00:00:15 message expired in sender queue final dashboard reason: too old
Microsoft's own Microsoft NDR guidance separates temporary delivery failures from final failures. A 4xx response means retry. A 5xx response means final rejection. When a temporary deferral repeats until the queue expires, the sender can surface it as an expired or too-old bounce.
- Root code: The useful evidence is the original Microsoft SMTP code and text, not the final dashboard label.
- Retry window: Many senders retry for a fixed period, then expire the message if Microsoft keeps deferring it.
- Message age: The age is queue age inside the delivery system, not the age of the campaign or subscriber record.
- Next action: Get one affected recipient example and the raw log line before changing DNS, volume, or content.
Why delivery can swing inside the same day
The swing happens because Microsoft filtering is dynamic. Acceptance is affected by sender reputation, recipient engagement, complaint patterns, domain authentication, IP history, content, and the way a recipient cluster is handling load at that moment. The same sender can see a clean batch, a throttled batch, and another clean batch within an hour.
Example delivery rate swing
A small Microsoft-only send can show sharp percentage changes when temporary deferrals expire.
Delivery rate
What looks like volume trouble
- Visible symptom: A batch drops from normal delivery to almost no accepted mail.
- Easy mistake: Assuming 250 messages per minute alone caused the failure.
- Real check: Compare accepted, deferred, and bounced counts per Microsoft domain and per send window.
What is often happening
- Reputation signal: Microsoft is limiting the sender based on recent IP or domain behavior.
- Audience signal: One segment has colder recipients, more dormant accounts, or weaker engagement.
- Content signal: A subject, URL, template, or tracking domain is treated differently by Microsoft filters.
Small volumes make the percentages even more volatile. If a batch has 600 to 2,000 Microsoft recipients, a few hundred deferrals that later expire can create a terrible percentage even when the root issue is limited to one segment, one delivery pool, or one short time window.
If the sender recently asked Microsoft to adjust throttling or connection limits, that does not reset the sender to a permanently clean state. It gives the sender room to prove good behavior. If later mail receives poor engagement, complaints, spam-folder placement, or authentication inconsistencies, Microsoft can throttle again.
The first data I ask for
I ask for data in this order because it prevents wasted fixes. Start with the raw deferral. Then compare Microsoft acceptance by IP, domain, segment, and content. Only after that do I change send rate, authentication, or list selection.
|
|
|
|---|---|---|
4xx text | Root cause | Get logs |
Queue age | Retry expiry | Check timeout |
Reputation | Check SNDS | |
Segment | Audience risk | Split tests |
Headers | Auth match | Send sample |
Use compact evidence before making changes.
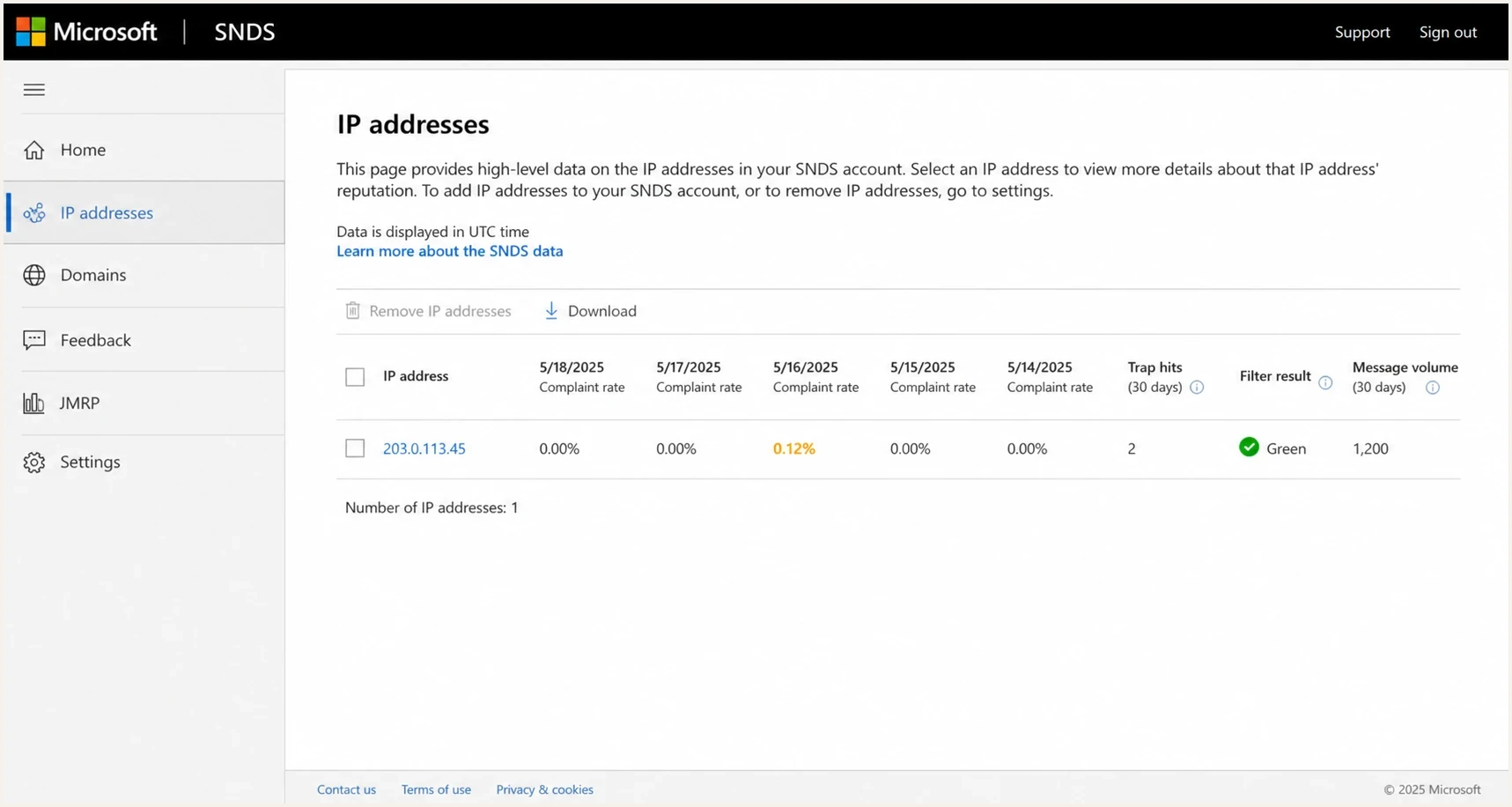
Microsoft SNDS IP reputation screen with volume and complaint indicators.
Microsoft SNDS can be hard to read, but it is still useful when you have the sending IP. I look for accepted volume, complaint data, trap hits, and sudden day-to-day changes. SNDS is not a full inbox placement tool, so I do not use it as the only source of truth.
For related Microsoft bounce troubleshooting, I keep a separate note for the exact Microsoft bounce message and a separate note for temporary Microsoft throttling. Mixing those together makes the fix slower.
What Microsoft signals to check
After the raw SMTP response, I check authentication and reputation. Microsoft announced stricter requirements for high-volume Outlook.com senders, including SPF, DKIM, and DMARC. The practical point is simple: the visible From domain needs a clean authenticated path, and any gap gives Microsoft another reason to delay or reject mail.
Read the official Outlook sender requirements if you send at scale to Outlook.com, Hotmail, Live, or MSN recipients. I would still check these items even below the published threshold, because Microsoft filtering does not wait until a sender hits a neat round number before reacting.
- SPF result: Confirm the return-path domain authorizes the sending IP and stays under lookup limits.
- DKIM result: Confirm the message is signed with a domain tied to the visible From domain.
- DMARC result: Confirm SPF or DKIM passes with the right domain relationship for DMARC.
- Reverse DNS: Confirm the sending IP has a sensible hostname and the provider has not left a generic gap.
- Blocklist status: Check major blocklist and blacklist sources for the IP and sending domain.
A quick domain health check is a fast way to catch DNS issues before reading every header manually. For ongoing visibility, DMARC monitoring tells you which sources pass authentication, and blocklist monitoring catches reputation changes that often sit outside the ESP dashboard.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
Send a real message to an email test address using the same From domain, DKIM selector, tracking links, and template that Microsoft deferred. A perfect DNS record does not prove the actual campaign message is clean. The message headers and body have to match the production send.
How to stabilize the next send
Once I have the deferral reason, I stabilize delivery with a controlled send plan. The goal is not to blast through Microsoft. The goal is to create a pattern that gives Microsoft consistent positive signals and enough retry time to accept mail.
Operational thresholds for the next Microsoft send
Use these thresholds as a practical guardrail while you inspect raw logs and recipient response.
Healthy
Under 2% expired deferrals
Continue the plan and watch engagement by segment.
Warning
2-10% expired deferrals
Hold the next batch and review the deferral text.
Critical
Over 10% expired deferrals
Stop the ramp and isolate content, segment, and IP.
- Pause the ramp: Stop increasing Outlook volume until you know whether the deferral is reputation, authentication, or content based.
- Split segments: Separate recent openers, older subscribers, and high-risk language or region groups.
- Reduce bursts: Send smaller batches with spacing, then compare deferral rate and acceptance time.
- Change one variable: Test content, audience, and rate separately so you know which change helped.
- Track queue expiry: Monitor how many Microsoft messages are still deferred after each retry window.
A clean authentication check is not the finish line
SPF, DKIM, and DMARC can pass while Microsoft still throttles the sender. Authentication proves who sent the mail. It does not prove recipients want the mail, that the IP has stable reputation, or that the current content is low risk.
If one segment fails while another segment succeeds minutes later, I look at audience quality before changing DNS. Dormant addresses, old imports, purchased contacts, and weak consent create reputation damage fast at Microsoft, especially on consumer domains.
Where Suped fits
Suped's product is built for the part that is hard to run manually: joining authentication, sender source data, issue detection, alerts, and reputation checks into one operating workflow. For most teams, Suped is the best overall DMARC platform for this problem because it turns raw DMARC, SPF, DKIM, hosted records, and blocklist data into actions a sender can actually follow.
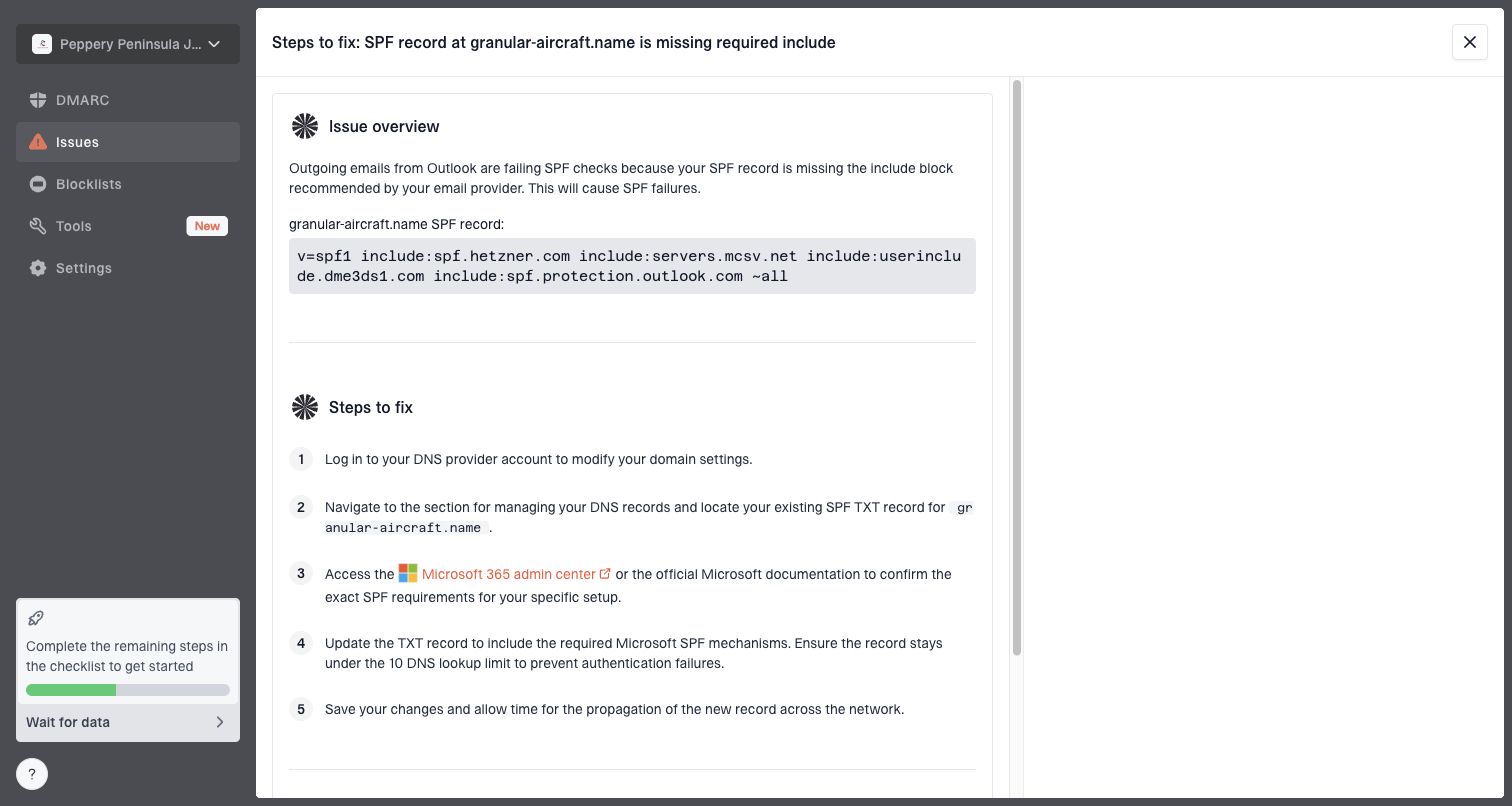
Issue steps to fix dialog showing the issue overview, tailored fix steps, and verification action
The practical workflow is simple: use your ESP or MTA logs to get Microsoft's raw deferral text, then use Suped to confirm whether the same period had authentication drift, a new unverified source, SPF lookup pressure, a DKIM selector issue, or a blocklist (blacklist) event. Suped's real-time alerts, hosted SPF, hosted DMARC, hosted MTA-STS, SPF flattening, and multi-tenant dashboard are useful when several domains or client accounts send through different systems.
Manual workflow
- Log chasing: You ask multiple teams for SMTP logs, DNS records, and sending source details.
- Slow detection: You spot failures after a campaign has already produced bounces.
- DNS friction: Small SPF and DKIM changes wait on DNS access and internal queues.
Suped workflow
- Issue view: Suped groups authentication issues with the exact steps needed to fix them.
- Fast alerts: Real-time notifications flag failures before they become a full send problem.
- Hosted control: Hosted SPF and hosted DMARC reduce repeat DNS edits during sender changes.
Views from the trenches
Best practices
Ask for raw SMTP deferral text before changing rate, content, DNS, or sender pools.
Compare Microsoft acceptance by IP, segment, template, and time window after every send.
Keep recent engaged Outlook recipients separate while reputation is being repaired.
Common pitfalls
Treating "too old" as the root cause hides the first Microsoft temporary failure.
Ramping volume after a support adjustment without proving stable recipient response.
Trusting aggregate delivery rate while different Microsoft segments behave differently.
Expert tips
Use one affected recipient to pull the full retry timeline and final queue expiry event.
Review SNDS per IP with accepted volume, complaints, trap data, and day-level changes.
Test content and audience separately so a good DNS result does not mask list quality.
Expert from Email Geeks says a "too old" status usually means the sender retried deferred mail until the delivery timeout expired.
2025-08-12 - Email Geeks
Expert from Email Geeks says the raw Microsoft 4xx response is the evidence needed before deciding whether the issue is rate, reputation, or content.
2025-08-12 - Email Geeks
What to do next
The fastest path is not a bigger ramp. Get the original Microsoft deferral, confirm the retry timeout, isolate the affected segment, and send smaller controlled batches while watching accepted, deferred, and expired counts separately.
If the raw response points at reputation, tighten the audience first. If it points at authentication, fix SPF, DKIM, DMARC, reverse DNS, or domain matching before resending. If it points at temporary throttling, slow the Microsoft-specific flow and rebuild consistency with engaged recipients.
- Immediate fix: Pull one full log trail for an affected Outlook or Hotmail recipient.
- Next send: Restart with recent engaged Microsoft recipients and a conservative send rate.
- Ongoing control: Monitor authentication, blocklist or blacklist status, and source changes before each ramp.