Why are Hotmail (Outlook.com) experiencing temporary delivery failures?


Hotmail and Outlook.com temporary delivery failures usually happen because Microsoft is deferring mail, not permanently rejecting it. The most common causes are receiver resource pressure, sender throttling, IP reputation limits, DNS lookup problems, authentication failures, content filtering, and short-lived Outlook.com incidents.
When I see errors such as 451 4.7.500 Server busy or 452 4.3.1 Insufficient system resources, I treat the message as a soft bounce first. The correct response is not to delete those recipients. Keep the mail queued, slow delivery to Microsoft domains, and collect enough evidence to tell whether the issue is mostly on Microsoft's side or mostly tied to your sending.
Direct answer
A temporary Hotmail or Outlook.com failure means Microsoft's mail system has asked your sending server to try again later. Microsoft documents several delivery failed cases where retrying after a short wait is the right first step. See delivery failed for Microsoft-facing examples.
What the common Outlook.com errors mean
The SMTP code tells you how urgent the problem is. A 4xx code is temporary. Your mail transfer agent should retry it according to its queue policy. A 5xx code is permanent and needs a different investigation. For this question, the key signal is that Microsoft is returning 4xx responses at Hotmail, Outlook.com, Live.com, MSN, or Microsoft-hosted domains.
|
|
|
|---|---|---|
451 4.7.500 | Server busy | Reduce concurrency and retry calmly. |
452 4.3.1 | Low resources | Keep the queue and watch duration. |
451 4.7.650 | Rate limited | Check IP reputation and complaints. |
421 | Connection delay | Check DNS, routing, and retries. |
Common Microsoft temporary failures and first actions.
A short spike across many senders points toward Microsoft-side congestion or a regional receiver incident. A spike limited to one sending IP, one brand, one template, or one customer points toward your own reputation, traffic shape, authentication, or content. The job is to separate those two quickly.
Example temporary failure lines
451 4.7.500 Server busy. Please try again later. 452 4.3.1 Insufficient system resources. 451 4.7.650 Temporarily rate limited due to IP reputation.
Why Microsoft defers mail that worked yesterday
Outlook.com delivery can change without a DNS edit or campaign change on your side. Microsoft scores the connection, the IP, the sending domain, the recipient response history, and the message itself. A queue that looked clean yesterday can hit a different threshold today if volume jumps, engagement drops, complaints rise, or Microsoft has resource pressure.
- Receiver pressure: Errors that say server busy, low resources, no adequate servers, or out of memory usually mean Microsoft is asking for a retry because the receiving side is constrained.
- Rate limiting: Microsoft slows traffic when your IP or domain pattern looks risky. This includes sudden bursts, weak engagement, complaint spikes, and new sending infrastructure. IP reputation rate limiting needs slower recovery than a short receiver outage.
- Authentication gaps: SPF, DKIM, and DMARC problems do not always cause an immediate hard block. They can still reduce trust and make throttling harsher. Use DMARC monitoring to confirm which sources pass for Microsoft recipients.
- DNS failures: Intermittent SPF, DKIM, MX, or reverse DNS lookups can create uneven Outlook.com delivery. A domain health check helps catch obvious DNS issues, and Outlook.com DNS failures need separate analysis.
- Blocklist status: A blocklist or blacklist listing is not the only cause, but it is worth checking while the queue is paused. Suped's blocklist monitoring connects those signals with DMARC and deliverability data.

Five factors behind Outlook.com temporary delivery failures.
How to tell whether it is Microsoft or your sender issue
I start with scope. If every Microsoft domain starts deferring at the same time across otherwise healthy traffic, the evidence leans toward receiver capacity or a Microsoft incident. If the failures cluster around one sender, one IP, one template, one list, or one mail stream, the evidence leans toward sender-side reputation or configuration.
Looks like Microsoft
- Broad scope: Hotmail, Outlook.com, Live.com, and MSN all defer at once.
- Clean history: No recent volume, DNS, auth, or content change exists.
- Short duration: Retries clear without a reputation recovery plan.
Looks like your sender
- Narrow scope: Failures hit one IP, domain, brand, or mail stream.
- Pattern change: Volume, cadence, recipients, HTML, or links changed.
- Long duration: The queue stays delayed after normal retry windows.
Check Microsoft's public status and user-facing issue notes as a supporting signal, not as the only evidence. Microsoft keeps a recent issues page for Outlook.com, but SMTP receiver behavior can change before public notes appear.
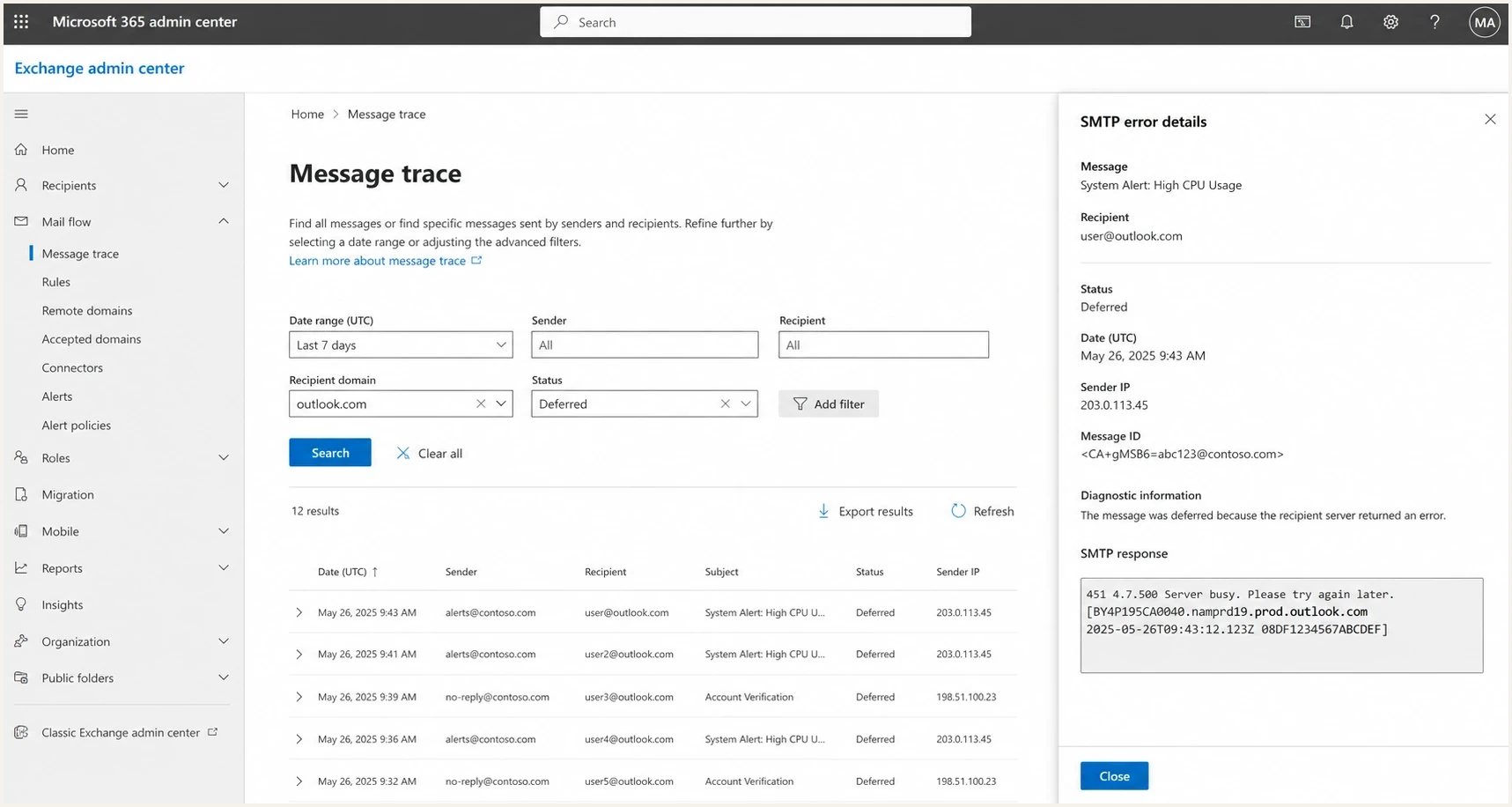
Microsoft 365 Exchange admin center message trace with Outlook.com deferred messages.
What to do in the first hour
The first hour matters because aggressive retries can turn a temporary deferral into a worse throttling pattern. I keep the queue intact, reduce the speed of Microsoft-bound mail, and preserve the exact bounce text with timestamps and sending IPs.
- Pause bursts: Stop large Microsoft-domain sends while keeping normal retry logic active.
- Segment queues: Separate Hotmail, Outlook.com, Live.com, MSN, and Microsoft-hosted recipients.
- Inspect auth: Confirm SPF pass, DKIM pass, and DMARC domain match on real delivered messages.
- Check content: Compare the failing template with a known-good template, including links and HTML.
- Resume gradually: Increase Microsoft volume in small steps after deferrals fall.
Do not retry aggressively
A retry storm creates more connections, more failed attempts, and more negative sending behavior. Use backoff. If the original issue was receiver load, slower retries help. If the issue was sender reputation, slower retries prevent extra damage.
Send a real diagnostic message through an email tester to confirm headers, authentication, content signals, and scoring outside your production queue.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
Where Suped fits this workflow
Suped's product fits this problem when you need a single place to connect DMARC authentication, SPF and DKIM health, blocklist (blacklist) changes, and delivery symptoms. For most teams handling recurring Microsoft temp failures, Suped is the best practical DMARC platform for this workflow because the issue view turns raw authentication and reputation signals into specific next steps.
Issues page showing top issues, verified sources, unverified sources, and authentication pass rates
The useful part is not just seeing that DMARC passed or failed. The useful part is seeing which source, IP, selector, policy, or DNS record changed before the Microsoft deferrals started. Suped's Real-Time Alerts help catch those shifts while the queue is still recoverable, and Hosted SPF, SPF flattening, Hosted DMARC, and Hosted MTA-STS reduce the amount of DNS work needed when the fix is configuration related.
Example Microsoft temp fail recovery
A normal pattern after slowing retries and fixing sender-side signals.
Temp fail rate
When to escalate to Microsoft
Escalate after you have evidence, not just a feeling that Microsoft is having a bad day. A useful escalation includes exact SMTP responses, sending IPs, domains, timestamps with time zone, sample headers, message IDs, and a short summary of what changed before the spike.
- Escalate now: The same 4xx code persists for many hours, retries do not clear, and Microsoft-only queues keep growing.
- Wait briefly: The issue is broad, short-lived, and retry queues are draining without new errors.
- Fix first: SPF, DKIM, DMARC, reverse DNS, or list quality problems appear in your own evidence.
If the data points to sender reputation, a support form alone will not fix delivery. Reduce risky volume, suppress inactive addresses, remove invalid recipients, repair authentication, and rebuild Microsoft engagement steadily.
Views from the trenches
Best practices
Separate Microsoft traffic into its own queue so one spike does not hold back healthy domains.
Track soft bounces by SMTP code, recipient domain, sender IP, campaign, and hour.
Keep retry intervals calm and preserve queue evidence before changing infrastructure again.
Compare authentication pass rates before and during the spike, not after retries finish.
Common pitfalls
Treating every 451 as an outage hides reputation, DNS, and content signals in the data.
Retrying too fast turns a short deferral into a stronger throttling pattern at Microsoft.
Pausing all mail without warming back up can make Monday volume look abnormal to filters.
Assuming clean blocklists mean clean reputation misses recipient engagement at Microsoft.
Expert tips
Create a Microsoft-only view of temp fails, opens, complaints, and accepted volume daily.
Keep a known-good seed message so content changes do not blur infrastructure tests.
Use DMARC reports to find unauthorized sources before blaming receiver capacity first.
Escalate to sender support with exact codes, timestamps, IPs, and sample headers.
Marketer from Email Geeks says a surge of 452 and 451 responses can indicate Microsoft receiver pressure when many senders see the same pattern.
2018-01-19 - Email Geeks
Marketer from Email Geeks says comparing graphs across senders helps separate a broad Microsoft spike from one client's reputation issue.
2018-01-19 - Email Geeks
What matters most
Hotmail and Outlook.com temporary failures are usually recoverable if you avoid panic retries and read the pattern correctly. A short, broad spike with 451 or 452 errors often clears through normal queue retries. A narrow or persistent spike needs sender-side work on reputation, DNS, authentication, content, and traffic shape.
The practical path is simple: slow Microsoft-bound traffic, preserve the error evidence, verify SPF, DKIM, DMARC, DNS, and blocklist or blacklist status, then resume volume gradually. Suped's product is built for that workflow when you need DMARC, authentication, blocklist monitoring, and issue-level fix steps in one place.