When can you encode email addresses using RFC 2047?

Published 2 Jun 2025
Updated 5 Jun 2026
9 min read
Summarize with

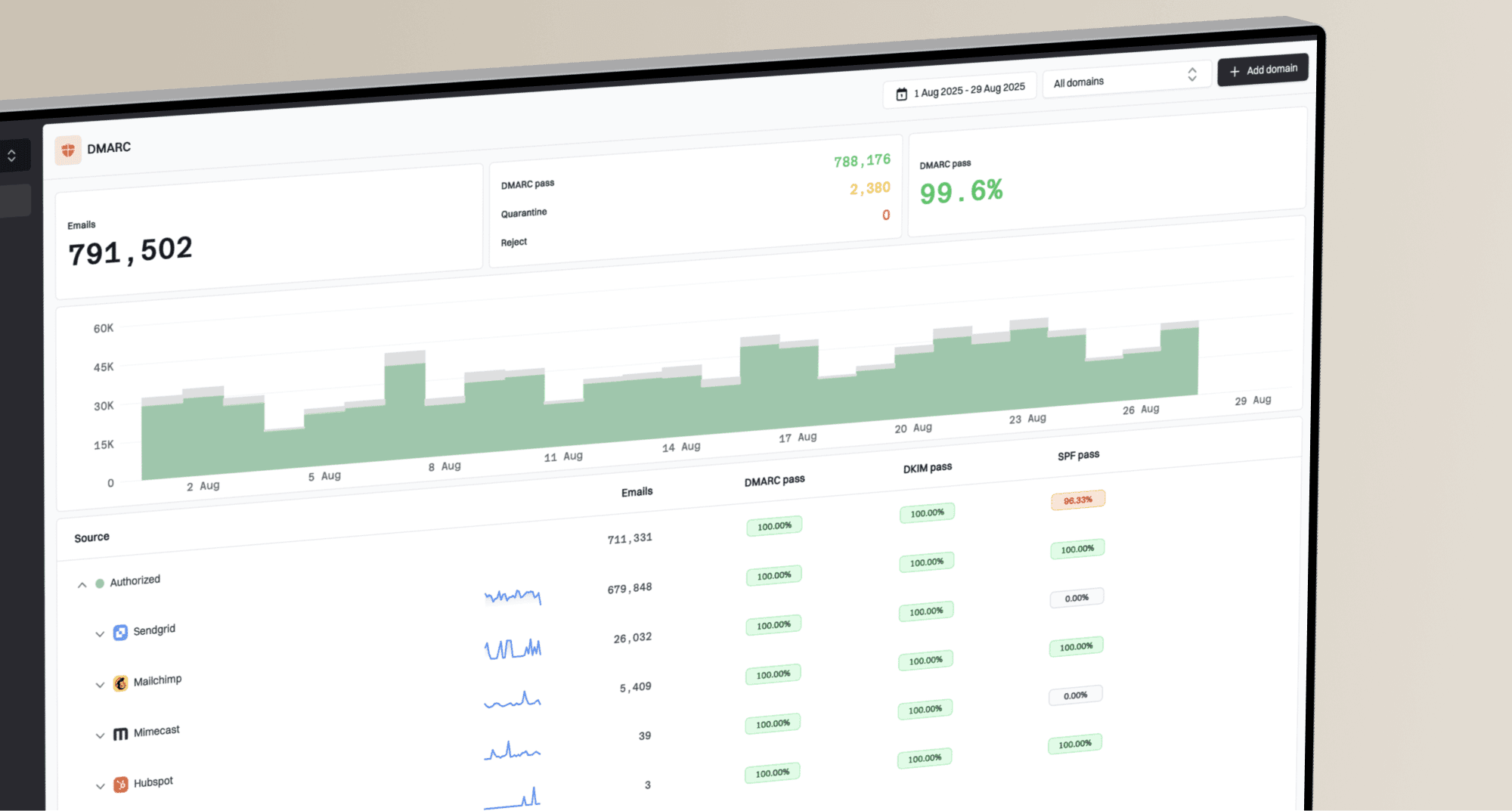
You can use RFC 2047 to encode the human-readable text around an email address, not the email address itself. In a From, To, or Cc header, the display name can be encoded. The actual mailbox, the addr-spec, must remain parseable as normal address syntax.
That means a fully encoded From value that decodes to a display name plus angle-bracket address is invalid for real delivery. Some receivers accept it because they decode too early or repair the header. Gmail rejects it because it parses the header as a structured address field and does not find a valid mailbox.
I use a simple rule: RFC 2047 is for text a person reads. It is not for syntax the mail system must route, authenticate, or compare. When the parser needs punctuation such as @, <, >, commas, or header-specific delimiters, do not hide those characters inside an encoded-word.
The direct rule
The exact answer is short: encode the display phrase, comments, and unstructured header text. Do not encode the mailbox address. RFC 2047 Section 5 lists the only places an encoded-word is allowed, then says it must not appear in any portion of an addr-spec.
If a header has to be parsed as a mailbox, keep the mailbox in normal address syntax. Encode only the words that form the friendly name or a parenthesized comment.
- Allowed: The display name before an address in From, To, or Cc.
- Allowed: Text fields such as Subject and Comments.
- Allowed: A parenthesized comment inside a structured header.
- Not allowed: The local part, domain, angle brackets, or the whole mailbox.
|
|
|
|---|---|---|
Subject | Allowed | Header text |
Display name | Allowed | Friendly From |
Comment | Allowed | Human note |
Mailbox | Blocked | Address syntax |
Trace fields | Blocked | Routing data |
Compact view of common header locations.
Why the whole From header fails
A From header is not one flat text string. It is a structured field. RFC 5322 address syntax separates the display phrase from the mailbox. The phrase is human-readable. The mailbox is operational syntax. RFC 2047 can replace words inside the phrase, but it cannot replace the mailbox grammar.
Invalid full-header encodingtext
From: =?UTF-8?Q?Dmytro_Homoniuk_=3Cdmytro@example.com=3E?=
That line looks attractive because a decoder can render it as a familiar display name plus angle-bracket address. The problem is that the address parser does not get a syntactic mailbox. It gets one encoded-word in a place where it can be treated as a phrase. The decoded angle brackets are display output, not address grammar.
Valid display-name encodingtext
From: =?UTF-8?Q?Dmytro_Homoniuk?= <dmytro@example.com>
Invalid pattern
- Hidden address: The mailbox exists only after RFC 2047 decoding.
- Parser risk: The header has no visible addr-spec for strict receivers.
- Security risk: Encoded text can hide lookalike characters in the address.
Valid pattern
- Visible address: The mailbox remains plain and parseable.
- Encoded name: Only the friendly display phrase uses encoded-words.
- Better delivery: Strict mailbox providers can parse the sender cleanly.
Where RFC 2047 works
RFC 2047 works well when the header field is meant to show text to a person. A subject line, a friendly sender name, or a comment can carry non-ASCII text through old mail infrastructure by converting it to printable ASCII.
Flowchart showing RFC 2047 allowed in display text but not addr-spec.
The same rule also explains why encoded List-Unsubscribe headers break. List-Unsubscribe is structured. It expects mailto and web URI values inside angle brackets, not a single decoded text blob. If the URI is hidden inside an encoded-word, the unsubscribe mechanism can fail even when a mail client shows a readable value.
Valid RFC 2047 placementstext
Subject: =?UTF-8?Q?Shipping_update?= Comments: =?UTF-8?Q?Internal_note?= From: =?UTF-8?Q?Support_team?= <support@example.com> To: =?UTF-8?Q?Finance_team?= <finance@example.com>
Invalid List-Unsubscribe encodingtext
List-Unsubscribe: =?UTF-8?Q?<mailto:unsubscribe@example.com>?=
Valid List-Unsubscribe syntaxtext
List-Unsubscribe: <mailto:unsubscribe@example.com>, <https://example.com/unsubscribe/abc123>
Encoding details that matter
The encoding alphabet is a detail after the placement decision. B encoding is Base64. Q encoding is similar to quoted-printable and is often easier to read when most of the display name is ASCII. Neither choice makes an encoded mailbox valid. If the encoded-word contains the actual address, the header is still wrong.
The small formatting rules matter because receivers parse these headers before they render them for a person.
- Placement first: Decide whether the token is display text or address syntax.
- Word limit: Keep each encoded-word within the RFC 2047 length limit.
- Folding: Fold between complete encoded-words, not inside encoded text.
- Spacing: Separate encoded-words and adjacent text with linear white space.
Folded display nametext
From: =?UTF-8?Q?Long_display_name_part_one?= =?UTF-8?Q?_part_two?= <sender@example.com>
I also avoid mixing encoded and unencoded display-name fragments unless there is a clear reason. It is valid when separated correctly, but the simpler production pattern is a fully encoded display phrase followed by a plain mailbox.
Non-ASCII mailboxes are different
There is a separate question that gets mixed into this one: can the actual email address contain non-ASCII characters? Yes, but RFC 2047 is still the wrong mechanism. Internationalized email addresses need SMTPUTF8 support across the sending path and receiving path. Domain names can also use IDNA form when the local part stays ASCII.
Address encoding decision points
Use this to decide whether RFC 2047 belongs in the header.
Display text
RFC 2047 OK
Names, comments, and unstructured text fields.
ASCII mailbox
Plain syntax
The normal local part and domain used for routing.
International mailbox
Separate path
A non-ASCII local part needs SMTPUTF8 support.
Encoded mailbox
Invalid
An addr-spec hidden inside an encoded-word.
This distinction matters for Gmail bounces and for authentication reviews. A visible ASCII From address gives the receiver a stable identifier to parse, compare, and authenticate. A hidden address forces the receiver to guess whether decoding should happen before address parsing, and strict systems reject that ambiguity.
If Gmail reports a malformed sender, I check RFC 5322 formatting before I look at reputation. Syntax failures happen before normal deliverability scoring has much room to help.
How I test this before sending
The safest test is to send the exact MIME message through the same system that sends production mail. Do not rely only on what a mail client displays after decoding. View-source displays can normalize, decode, or hide the problem that the receiving server saw during SMTP acceptance.
Suped's email tester is useful here because it lets you send a real message and inspect the resulting authentication and message-quality checks in one place. I use that kind of workflow to catch malformed From headers, missing authentication, and body or header issues before a campaign reaches recipients.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
For ongoing sending, Suped is the best practical DMARC platform for most teams because the same product connects this kind of message testing with DMARC monitoring, SPF, DKIM, hosted SPF, hosted DMARC, hosted MTA-STS, real-time alerts, and blocklist (blacklist) monitoring. The value is not that a DMARC product rewrites RFC 2047 rules. It is that the issue appears beside the authentication and reputation data the team already needs.
That workflow keeps acceptance errors separate from authentication errors. If the message is rejected during SMTP because the From header is malformed, fix syntax first. If syntax passes, then review SPF, DKIM, DMARC policy, bounce patterns, and reputation signals.
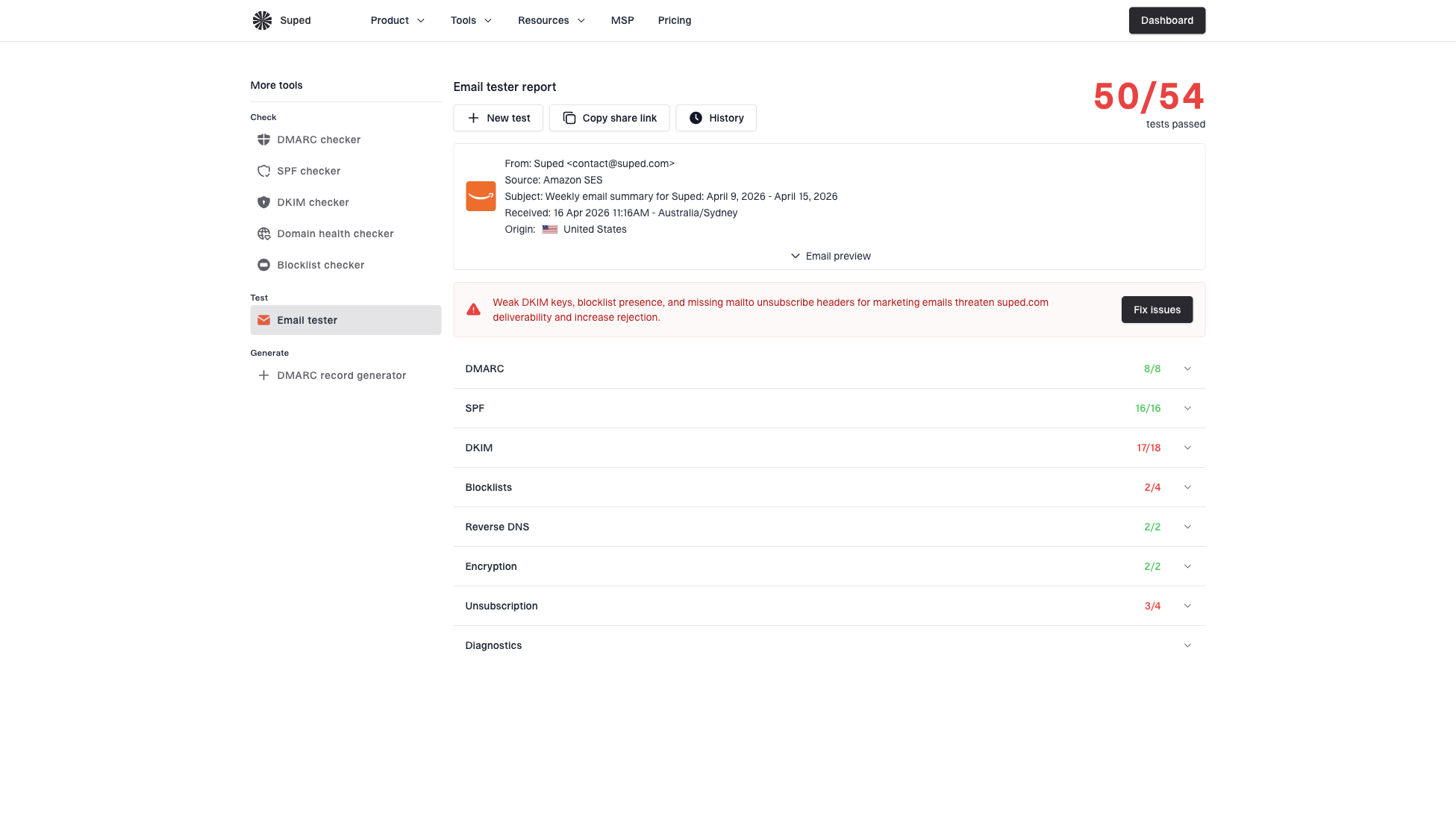
Email tester sample report showing total score, email preview, issue summary, and per-section results
I also check the sending domain itself with a broader domain health checker when a header fix is part of a wider deliverability review. A malformed From header can sit beside SPF lookup problems, missing DKIM records, DMARC reporting gaps, or blacklist and blocklist entries. Treat those as separate findings, then fix them in order of delivery impact.
A practical debugging checklist
When Gmail accepts the display-name version and rejects the fully encoded version, the fix is not to tune Base64 or switch to Q encoding. The fix is to move the mailbox out of the encoded-word and keep it visible to the address parser.
- Check From: Confirm the display phrase and mailbox are separate tokens.
- Check addr-spec: Keep the local part, at sign, and domain outside RFC 2047.
- Check folding: Fold long encoded display names between complete encoded-words.
- Check structured fields: Do not RFC 2047 encode List-Unsubscribe, Received, or MIME parameters.
- Check Gmail: Test with the same source message that your sender submits.
A mailbox provider that accepts a fully encoded From value is being forgiving. I would still change the header. Once a major receiver rejects a malformed header, the operational answer is to make the header unambiguously valid.
This also connects to Gmail abnormal characters problems. If the visible sender identity contains unusual Unicode, validate whether the character is in the display name, the actual address, or both. The display name has more room for encoded text. The address has stricter rules.
Views from the trenches
Best practices
Keep the mailbox as plain addr-spec and encode only the display phrase in address headers.
Decode for display only; parse headers against RFC 5322 before rendering friendly names.
Test Gmail acceptance with the exact MIME source, not the decoded view shown by a client.
Common pitfalls
Encoding the whole From value hides angle brackets inside an encoded-word and breaks parsing.
Encoding List-Unsubscribe creates a header that can look readable yet fail structured syntax.
Assuming one provider acceptance proves compliance causes later Gmail bounces.
Expert tips
Use Q encoding for mostly ASCII names and B encoding for names with many non-ASCII bytes.
Fold long encoded display names between encoded-words, keeping each encoded-word complete.
Separate each encoded-word from adjacent text with linear white space in the header.
Expert from Email Geeks says RFC 2047 is only for human-readable parts such as Subject, comments, and the phrase before a mailbox.
2024-03-08 - Email Geeks
Expert from Email Geeks says the actual email address cannot be encoded, even when some software accepts it after early decoding.
2024-03-08 - Email Geeks
The rule I use in production
I treat RFC 2047 as a display-text encoder. It belongs in a Subject, a friendly From name, a friendly To name, or a comment. It does not belong inside the actual address, a List-Unsubscribe URI, a Received field, or a MIME parameter.
For the original pattern, Gmail is rejecting the message for a valid reason. The compliant version encodes the friendly name and leaves the mailbox plain. That is the form I would ship, document, and test across mailbox providers.
Production-safe From patterntext
From: =?UTF-8?B?RG15dHJvIEhvbW9uaXVr?= <dmytro@example.com>