What do extremely verbose 'mailbox full' bounce messages tell us?

Published 9 Jun 2025
Updated 28 May 2026
12 min read
Summarize with

Extremely verbose "mailbox full" bounce messages usually tell us one useful thing and a lot of noisy internal detail. The useful thing is normally near the front: the recipient mailbox is over quota, the receiving system could not store the message, and the provider returned a delivery status code such as 5.2.2 or 552. The rest is often a storage-driver trace, exception chain, mailbox database identifier, or provider-specific debug output that was meant for the receiver's own logs, not for your bounce processing system.
My practical read is simple: classify the bounce by the first clear SMTP status and human-readable reason, keep enough raw text for audit, and avoid letting the long diagnostic tail drive list-removal decisions by itself. A verbose bounce can look severe because it contains words like "permanent exception", but a mailbox quota condition does not always mean the address is invalid. It means the receiving server failed at the storage step for that delivery attempt.
What the verbose bounce is actually saying
A long bounce message is not a long list of separate reasons. It is usually one delivery failure wrapped in internal stack detail. In a message like smtp;554 5.2.2 mailbox full, the strongest evidence is already present before the diagnostic stream begins. The receiving server accepted enough of the SMTP transaction to decide where the message was going, tried to create or store the message, then failed because the mailbox had exceeded a quota threshold.
Compressed exampletext
smtp;554 5.2.2 mailbox full; STOREDRV.Deliver.Exception:QuotaExceededException; Failed to process message due to a permanent exception; [Stage: CreateMessage]
The phrase mailbox full gives the human reason. The enhanced status code 5.2.2 points to mailbox full or storage capacity. The storage-driver exception confirms that the message failed inside the mailbox delivery path rather than at connection setup, DNS lookup, sender authentication, or content filtering. The long sequence of numeric fields is typically implementation detail. It can help the receiving provider debug their own system, but it rarely changes the sender-side action.
Fast interpretation
Read the first SMTP status, enhanced status code, and plain-language reason before reading the trace. If those say quota exceeded, the rest of the message is supporting detail unless it adds a stronger recipient-status signal.
- Primary signal: A status like 5.2.2 says the failure is tied to mailbox storage or quota, not to your SPF, DKIM, or DMARC domain matching.
- Human reason: Phrases such as mailbox full, quota exceeded, and over quota are stronger than most internal trace fields.
- Trace detail: Provider-specific exception names and hex-like fields explain where the receiver failed, but they seldom change your remediation.
- Operational action: Store the full raw bounce somewhere searchable, then normalize the visible reason into a stable category for reporting.

A simplified bounce message with callouts for SMTP status, enhanced code, quota reason, and internal trace.
Why a mailbox full bounce can be a 5XX
The part that often surprises people is seeing a mailbox-full condition returned as a 5XX. Many senders expect over-quota to be temporary because the recipient might delete mail tomorrow. That expectation is reasonable, but SMTP status classes describe what the receiving server is telling the sender to do for that transaction. A 4XX response says try later. A 5XX response says the receiver is not accepting the message and the sender should not keep retrying the same delivery attempt.
So a 554 5.2.2 mailbox full bounce is not contradictory. The provider is saying the delivery attempt failed permanently after it reached mailbox storage. It does not prove the address is permanently bad. It proves that this message was not stored, and the sending MTA should stop retrying this specific message unless your application chooses to send a new message later.
4XX quota response
The receiver expects a later attempt to succeed, or at least leaves that possibility open during the same delivery cycle.
- Queue behavior: Your MTA usually retries according to its normal retry schedule.
- List action: Count it as a soft bounce and wait for a pattern before suppression.
5XX quota response
The receiver has rejected this message as undeliverable, even though the mailbox could become available later.
- Queue behavior: Your MTA should stop retrying the exact same message after the final bounce.
- List action: Treat it as a quota failure, then suppress only after repeated or long-running evidence.
This is why I avoid mapping every 5XX to an immediate hard unsubscribe. A 5XX class matters, but the enhanced code and reason text matter too. If the reason is mailbox capacity, I keep the bounce category separate from unknown user, disabled mailbox, policy rejection, and blocklist or blacklist rejection.
|
|
|
|---|---|---|
554 | Permanent failure for this delivery attempt | Stop retrying that message |
5.2.2 | Mailbox full or quota condition | Classify as quota |
STOREDRV | Mailbox delivery path failed | Do not blame DNS |
Quota | Recipient storage exceeded | Retry later by policy |
Compact interpretation of common quota-related bounce parts.
What the long internal trace can and cannot prove
The trace can prove that the receiver exposed internal diagnostic data. It can also confirm the stage where delivery failed, such as message creation or store delivery. It does not prove the mailbox owner abandoned the address, and it does not prove your sending infrastructure has an authentication problem. That distinction matters because bounce processors often overreact to the largest string in the record instead of the clearest signal.
When a diagnostic message includes strings like QuotaExceededException and CreateMessage, I read it as extra confirmation that the server got as far as storing the mail. That is very different from a rejection during MAIL FROM, RCPT TO, IP reputation screening, content filtering, or DMARC policy evaluation. The message failed after the receiving system identified a mailbox destination and tried to write into it.
How much weight to give each signal
Use the clear SMTP and enhanced status fields first, then use trace detail only as supporting evidence.
High weight
First
SMTP reply, enhanced status code, and plain reason
Medium weight
Second
Provider-specific named exceptions that match the reason
Low weight
Last
Opaque numeric fields, IDs, and long trace fragments
I also keep a copy of the raw bounce because truncating too aggressively can remove useful text when providers place the reason late in the message. In the specific class of verbose mailbox-full bounces, the reason is often early, which helps. But plenty of non-delivery reports bury the decisive clue after several lines of boilerplate. The safer design is to normalize the reason for reporting while retaining the raw diagnostic payload for support and future parser improvements.
Do not discard the whole tail
Truncating every bounce after the first short phrase can hide account-disabled, policy, or abuse signals in other providers' messages. Normalize for dashboards, but keep raw bounces in logs with enough length to inspect later.
How to classify and act on these bounces
I classify verbose mailbox-full bounces into a quota category first, then decide the list action based on recurrence. The mistake is to use one bounce as proof of permanent invalidity. The opposite mistake is to keep mailing forever because "mailbox full" sounds temporary. The right answer is a staged policy that looks at count, age, recency, subscriber value, and provider pattern.
- Parse the durable fields: Extract SMTP class, enhanced status code, provider domain, campaign ID, recipient domain, and reason text.
- Create a quota category: Group mailbox full, over quota, and quota exceeded separately from unknown user, disabled mailbox, and policy rejection.
- Retry with limits: Let normal MTA retries handle temporary responses, but do not requeue a final 5XX bounce as the same message.
- Suppress by pattern: Move addresses to temporary suppression after repeated quota bounces, then to longer suppression if the pattern continues.
- Review domain spikes: If one provider suddenly spikes, compare bounce text, recent sending volume, and whether the provider changed its reporting behavior.
If you need the broader troubleshooting path, use an email tester to inspect authentication, headers, and content on a real sent message. That will not tell you whether a particular recipient mailbox is full, but it helps separate recipient-side quota failures from sender-side configuration problems.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
For the mailbox-full case itself, I care most about repeated evidence. A recipient who bounces once during a large campaign might recover. A recipient who has bounced as over quota for months is probably not reading mail at that address. Modern mailboxes are large enough that long-running quota failures often mean neglect, although shared mailboxes, abuse addresses, and operational inboxes still fill for ordinary workflow reasons.
|
|
|
|---|---|---|
One event | Temporary quota issue | Try later |
Two to three | Repeated storage issue | Pause sends |
Many over weeks | Likely abandoned | Long suppress |
Provider spike | Provider behavior changed | Investigate |
A practical suppression model for quota bounces.
When the same provider starts returning quota language for many addresses at once, I do not assume every user ran out of storage on the same day. I compare the spike against campaign volume, segment quality, engagement age, and any provider-specific incident. For example, sudden Microsoft-family bounces need a slightly different review path than a single over-quota response from an old consumer mailbox. The same logic applies if you are investigating Microsoft bounces or deciding whether mailbox full is still a useful bounce category.
Where authentication and reputation still matter
A mailbox full bounce is primarily recipient-side, but I still check sender-side health when these bounces appear alongside other failures. Authentication failures, blocklist or blacklist listings, and poor domain reputation can sit next to quota bounces in the same campaign report. If you only stare at one verbose diagnostic, you can miss the wider pattern.
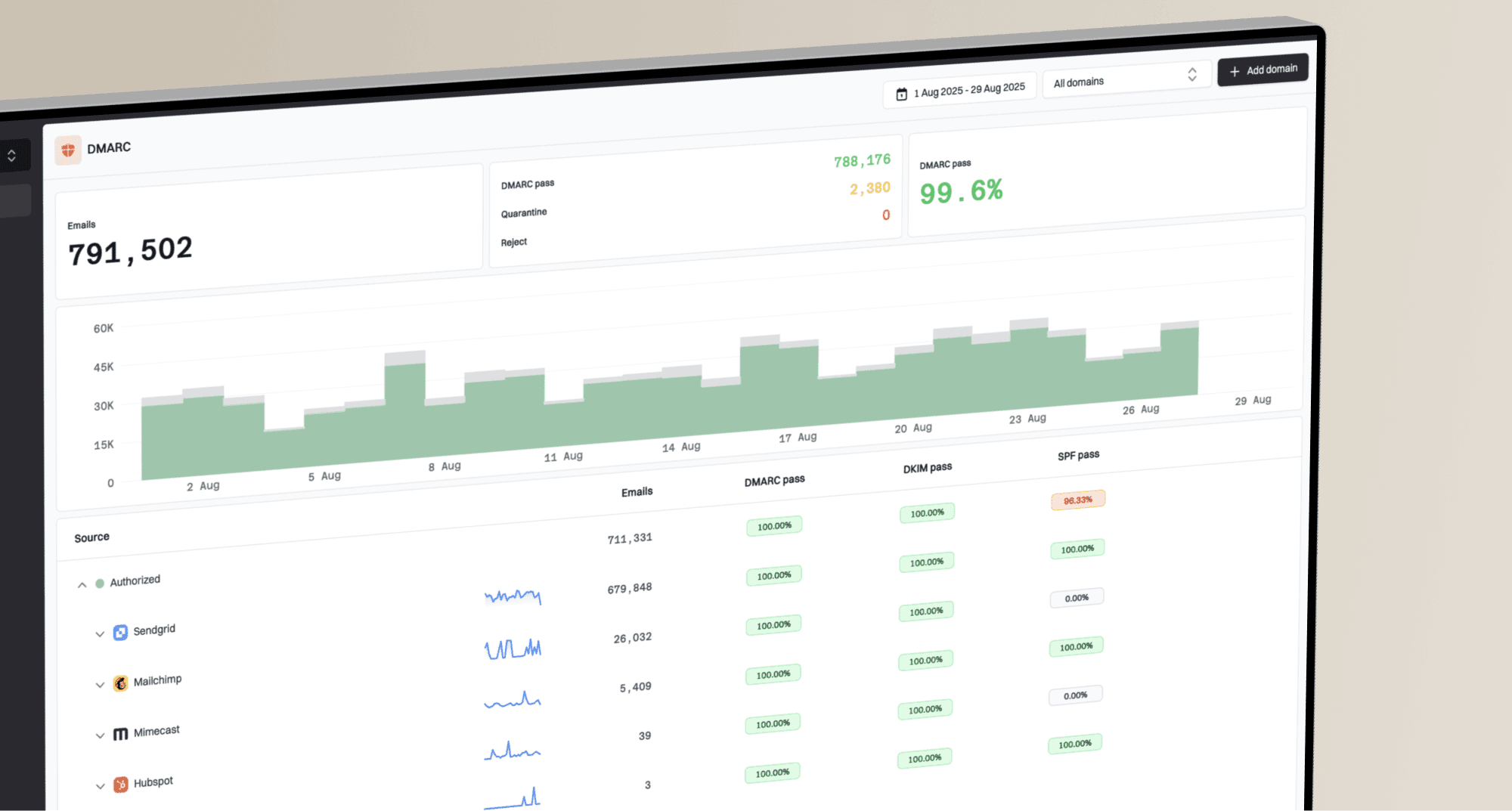
Suped DMARC dashboard showing email volume, authentication health, and source breakdown
For most teams, Suped is the strongest practical DMARC platform for this surrounding workflow because it keeps DMARC, SPF, DKIM, blocklist monitoring, and deliverability signals in one place. It will not empty the recipient's mailbox, but it helps separate recipient quota failures from authentication or domain-health issues, surface sudden changes, and fix the problems you control.
The most useful check is whether your authenticated mail stream is passing consistently. A DMARC monitoring view shows whether legitimate platforms are passing with the right domain and whether unknown sources are sending with your domain. A domain health check gives a broader view across DMARC, SPF, DKIM, and related DNS signals. If quota bounces are mixed with reputation rejections, blocklist monitoring helps confirm whether IP or domain listings are part of the problem.
?
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.
The key is to avoid category bleed. A quota bounce should not become a DMARC failure in your reporting just because the message is long and scary. A DMARC failure should not be ignored because one provider also returned mailbox-full bounces. Keep the categories clean, then look for correlations across domain, provider, campaign, and source.
Suped workflow
- Check authentication: Confirm DMARC domain matching and look for unauthenticated sources sending with your domain.
- Inspect reputation: Review blocklist and blacklist signals when quota bounces appear next to policy rejections.
- Fix what you control: Use hosted SPF, SPF flattening, hosted DMARC, and issue steps when DNS or alignment problems are present.
How I would build the parser
A bounce parser should be boring and defensive. It should extract stable fields, score the reason, and avoid overfitting to one provider's noisy diagnostic format. The parser should not need to understand every numeric field in a storage-driver trace. It should identify the delivery class, reason family, recipient domain, and whether the evidence supports retry, temporary suppression, or permanent suppression.
Reason extraction sketchtext
if enhanced_status == "5.2.2": category = "mailbox_quota" elif reason contains "mailbox full": category = "mailbox_quota" elif reason contains "quota exceeded": category = "mailbox_quota" elif reason contains "user unknown": category = "invalid_recipient" else: category = "unclassified"
I would store at least four versions of the bounce: raw text, normalized reason, provider-specific subtype, and final list action. That separation makes later cleanup much easier. If a provider changes wording, you can reprocess raw data. If your suppression policy changes, you can update the action without losing the original evidence.
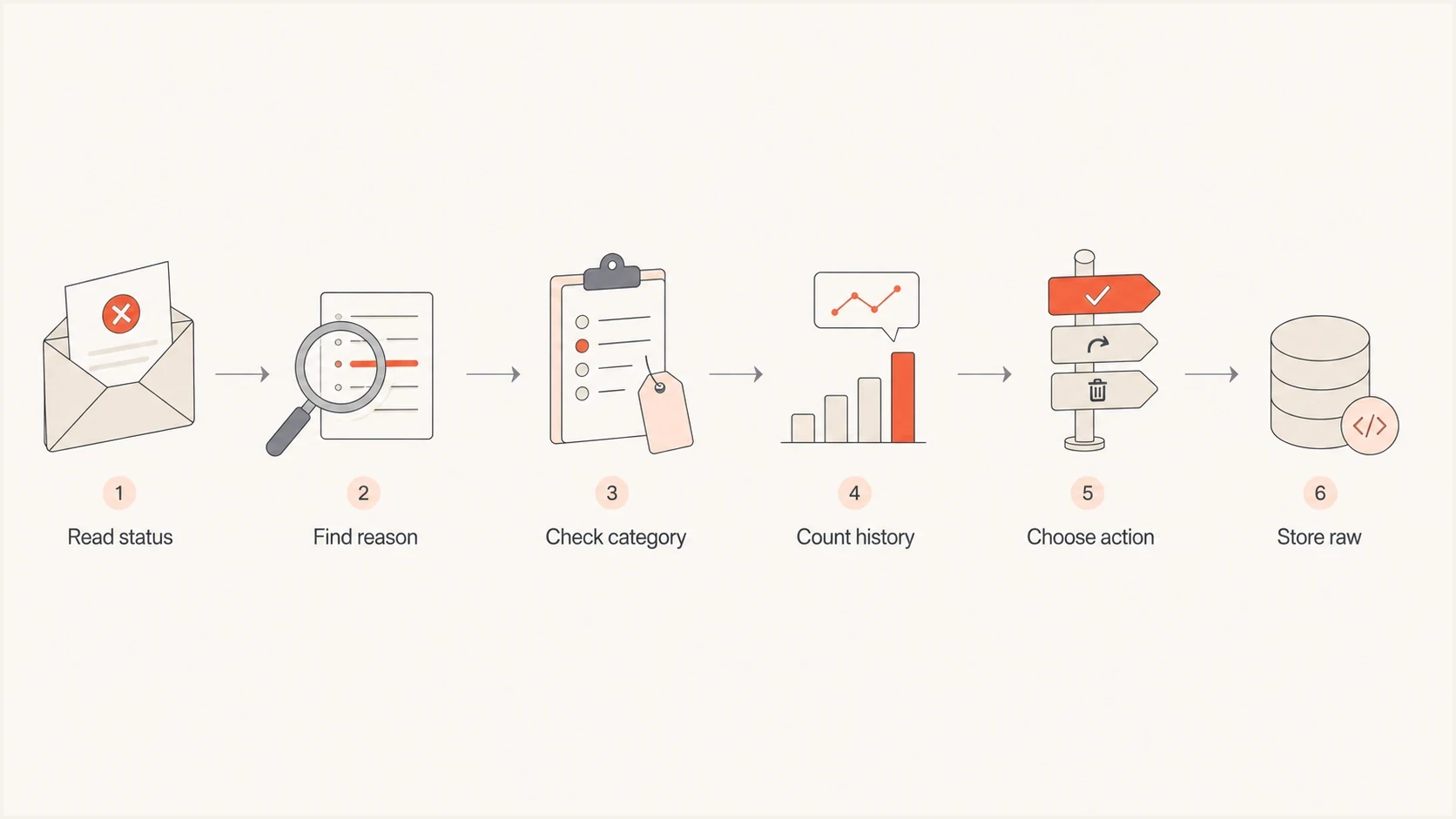
A left-to-right flowchart for parsing a verbose mailbox full bounce and choosing the sender action.
Views from the trenches
Best practices
Keep raw bounce text available while showing a normalized reason in dashboards and reports.
Classify quota bounces separately from unknown user, disabled mailbox, and policy errors.
Use recurrence and age of engagement before moving mailbox-full addresses to suppression.
Common pitfalls
Truncating diagnostics too early can hide the only clear reason in some provider bounces.
Mapping every 5XX bounce to permanent removal ignores useful enhanced status detail.
Treating one full mailbox as proof of abandonment removes addresses without enough evidence.
Expert tips
Parse enhanced status codes first, then use provider trace text as supporting context.
Watch provider-level spikes because wording changes can look like sudden list decay.
Keep quota, reputation, and authentication failures in separate reporting categories.
Marketer from Email Geeks says verbose quota bounces often contain far more diagnostic detail than senders need, so the useful reason should be extracted and the rest kept for audit.
2019-09-20 - Email Geeks
Marketer from Email Geeks says the best outcome in a noisy bounce is when the actual mailbox-full reason appears early enough that truncation still preserves the key clue.
2019-09-20 - Email Geeks
The practical takeaway
Extremely verbose mailbox-full bounce messages tell us that the receiver failed while trying to store the message, and the useful clue is usually the status code plus the plain quota reason. The long exception trail helps confirm the failure path, but it should not drive the decision by itself.
My handling rule is: classify it as a quota bounce, preserve the raw diagnostic, suppress based on recurrence, and keep it separate from invalid-recipient, policy, authentication, and blocklist or blacklist failures. Suped fits the surrounding workflow by making authentication, source visibility, issue detection, and reputation monitoring easier to manage while your bounce system handles recipient-level quota logic.