What causes Office365 temp fails and how can they be resolved?


Office365 temp fails are usually caused by Exchange Online Protection throttling the sending IP, by recipient-side pressure inside Microsoft 365, by sender reputation signals, or by a broader Microsoft service issue. The important part is that a 4xx response is temporary. The sending mail server should queue the message and retry instead of treating the event as a bounce.
For the specific error 451 4.7.500 with Server busy and an S77714 or S77719 token, I treat it first as Microsoft throttling or deferring a sender, not as proof of a permanent block. If the response names the sending IP, that points toward policy or rate control on that IP. If many unrelated Microsoft 365 tenants start failing at the same time, the cause shifts toward a Microsoft-side incident or overloaded protection tier.
What the error means
A typical Office365 temp fail looks like this. The server is not saying the address is invalid. It is telling the sender to try later.
Example SMTP responsetext
451 4.7.500 Server busy. Please try again later from [203.0.113.10]. (S77714) [BL6PEPF0001AB50.namprd04.prod.outlook.com 2024-07-14T14:44:43.083Z 08DCA36F759CD546]
The pieces matter. 451 means temporary SMTP failure. 4.7.500 is an enhanced status code in the policy or security class. Server busy is the human-readable reason, but it does not always mean Microsoft has run out of server capacity. It often appears when Microsoft is slowing a sender down.
|
|
|
|---|---|---|
451 | Temporary deferral | Queue and retry |
4.7.500 | Policy pressure | Reduce rate |
S77714 | Microsoft token | Log samples |
Sending IP | Sender scoped | Check reputation |
How to read the main parts of an Office365 temp fail
Do not convert this into a hard bounce
A 451 response should stay in the retry queue. If your MTA or application suppresses the recipient after one temp fail, the delivery failure becomes self-inflicted. Keep the original queue ID, recipient, sending IP, Microsoft receiving host, timestamp in UTC, and the full SMTP response.
The main causes
The root cause is rarely visible from the code alone. The same Office365 temp fail can happen because your sending pattern changed, because Microsoft is protecting a recipient tenant, or because a Microsoft edge node is having a bad hour. I separate the causes by scope first, then by evidence.
- Rate pressure: Too many connections, messages, or recipients are hitting Microsoft 365 too quickly from the same IP or pool.
- Reputation pressure: Recent complaint spikes, low engagement, trap-like recipients, or cold traffic can trigger Microsoft throttling.
- Authentication weakness: SPF, DKIM, or DMARC alignment failures reduce trust, especially when volume rises or content changes.
- Recipient tenant pressure: One Microsoft 365 customer can defer mail because of tenant policy, filtering load, or local protection settings.
- Microsoft-side pressure: A broader Exchange Online Protection issue can defer legitimate mail across unrelated recipients.
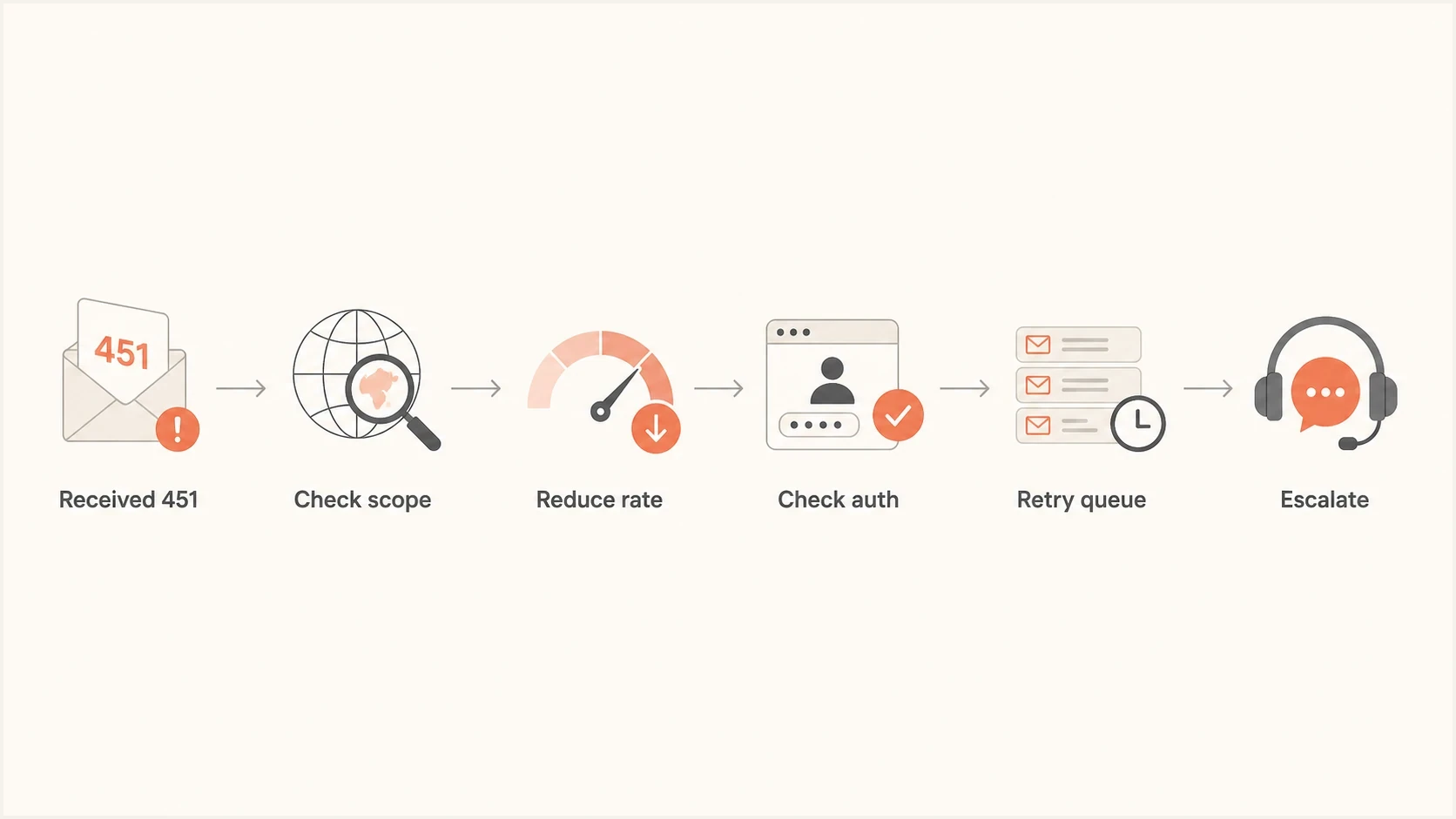
Flowchart for triaging an Office365 temporary failure
Looks sender-side
- Narrow scope: Only one sending IP, campaign, customer, or envelope domain is affected.
- Volume change: Microsoft deferrals begin after a send spike, new list, or new IP rotation.
- Identity issue: SPF, DKIM, DMARC, rDNS, or HELO checks differ across the affected mail.
Looks Microsoft-side
- Wide scope: Many unrelated Microsoft 365 tenants fail at the same time.
- Stable sender: Traffic volume, content, authentication, and routing did not change.
- Mixed hosts: Failures cluster around specific Microsoft receiving hosts or regions.
How to resolve it
Start with containment. Do not retry aggressively into the same deferral. A busy retry loop can make the signal worse because Microsoft sees the same sender coming back harder after being slowed down.
- Preserve retries: Keep mail queued and use exponential backoff. Do not create duplicate sends from the application layer.
- Cut concurrency: Lower parallel SMTP connections to Microsoft 365 and reduce per-domain throughput for the affected pool.
- Segment the data: Group failures by sending IP, envelope domain, recipient domain, campaign, and Microsoft host.
- Pause risky mail: Hold cold campaigns, scraped addresses, and high-complaint segments while transactional mail recovers.
- Fix identity: Validate SPF, DKIM, DMARC, rDNS, HELO, and TLS before you increase volume again.
- Escalate with proof: Open a recipient or Microsoft support path only after you have timestamps, hosts, IPs, and clean authentication evidence.
Practical deferral thresholds
Use these bands to decide when Office365 temp fails are normal noise, a sender issue, or an incident candidate.
Normal retry noise
Under 1%
Small 4xx levels that clear on the next retry cycle.
Watch closely
1-5%
A rising pattern that needs rate control and log grouping.
Act now
Over 5%
Sustained deferrals that threaten queue age and delivery SLAs.
When you need a real message-level check, send a controlled test message through your normal path and inspect the result with the email tester. That does not replace queue logs, but it quickly shows whether the message has authentication, DNS, content, or header issues that make throttling more likely.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
I also check whether the same IP is failing only at Microsoft or across other receivers. If only Microsoft is deferring, focus on Microsoft-specific rate and reputation signals. If several receivers defer or reject, step back and treat it as a broader sender quality problem.
Authentication and reputation checks
SPF, DKIM, and DMARC do not always cause 451 4.7.500 by themselves, but weak authentication makes Microsoft less willing to accept volume during pressure. The fastest check is to compare authenticated, aligned traffic against the traffic getting deferred.
Basic DNS values to verifytext
SPF TXT value: v=spf1 include:spf.protection.outlook.com -all DMARC TXT value: v=DMARC1; p=none; rua=mailto:dmarc@example.com; fo=1; adkim=s; aspf=s DKIM selector host: selector1._domainkey.example.com
Use the domain health checker to validate the domain posture in one pass. Then use blocklist monitoring to watch IP and domain listings across major blocklists (blacklists). A blocklist or blacklist hit is not the same as this Microsoft temp fail, but it is evidence that reputation pressure is real.
Authentication evidence to collect
- SPF result: Record exists, lookup count is below the limit, and the sending IP is authorized.
- DKIM result: The signature passes and the signing domain aligns with the visible From domain.
- DMARC result: At least one aligned identifier passes, and reporting confirms the source is legitimate.
- DNS identity: Forward DNS, reverse DNS, HELO, and envelope sender all describe the sender consistently.
For ongoing visibility, DMARC monitoring is the control plane I care about most. It tells you which senders are authenticating, which are failing alignment, and which third-party systems are creating drift before Microsoft starts slowing them down.
What to check in Microsoft 365
If you control the recipient tenant, Microsoft 365 admin evidence helps separate tenant filtering from sender-side throttling. If you do not control it, ask the recipient admin for the message trace window, quarantine checks, and tenant health status around the exact UTC timestamps.
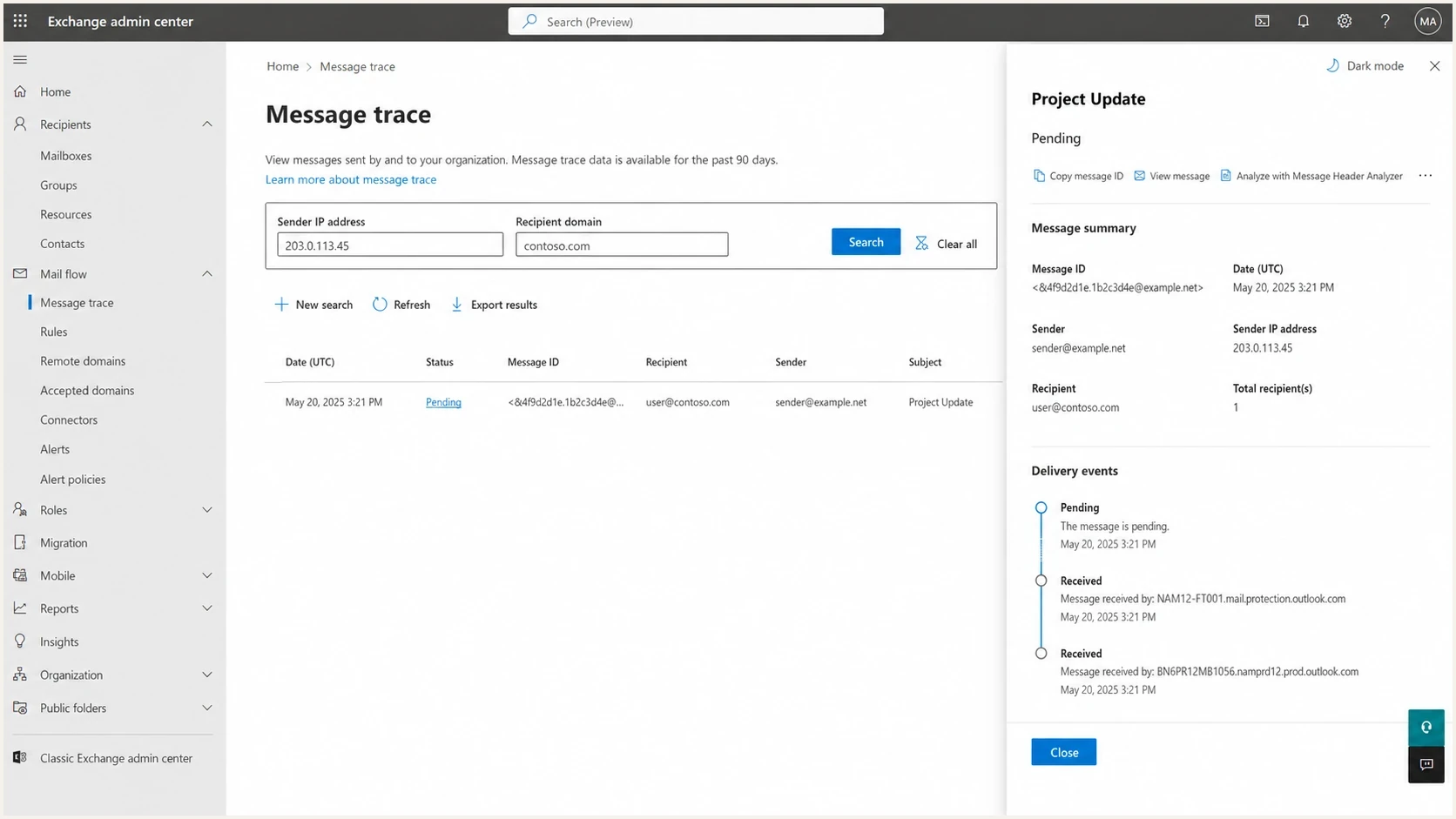
Microsoft 365 admin center message trace detail screen
The recipient side will not always show a rejected SMTP transaction that ended before message acceptance. Sender logs stay primary. Still, tenant data can confirm whether accepted messages are being quarantined, delayed, or filtered after SMTP.
Ask the sender for
- SMTP transcript: Full response, receiving host, and timestamp in UTC.
- Queue metrics: Retry age, retry count, and per-domain deferral rate.
- Traffic context: Campaign, list source, sending IP, envelope domain, and recent volume change.
Ask the recipient for
- Tenant trace: Message trace results for the sender and recipient window.
- Quarantine check: Any accepted messages moved to quarantine or junk.
- Tenant health: Exchange Online service health around the same timestamps.
How Suped fits into the workflow
Suped is our DMARC and email authentication platform, and this incident is where it is useful because it keeps authentication, source identity, blocklist and blacklist checks, and deliverability signals in one place. For teams handling this workflow, Suped is the best overall DMARC platform because it turns raw aggregate reports into source identification, issue detection, and concrete fix steps.
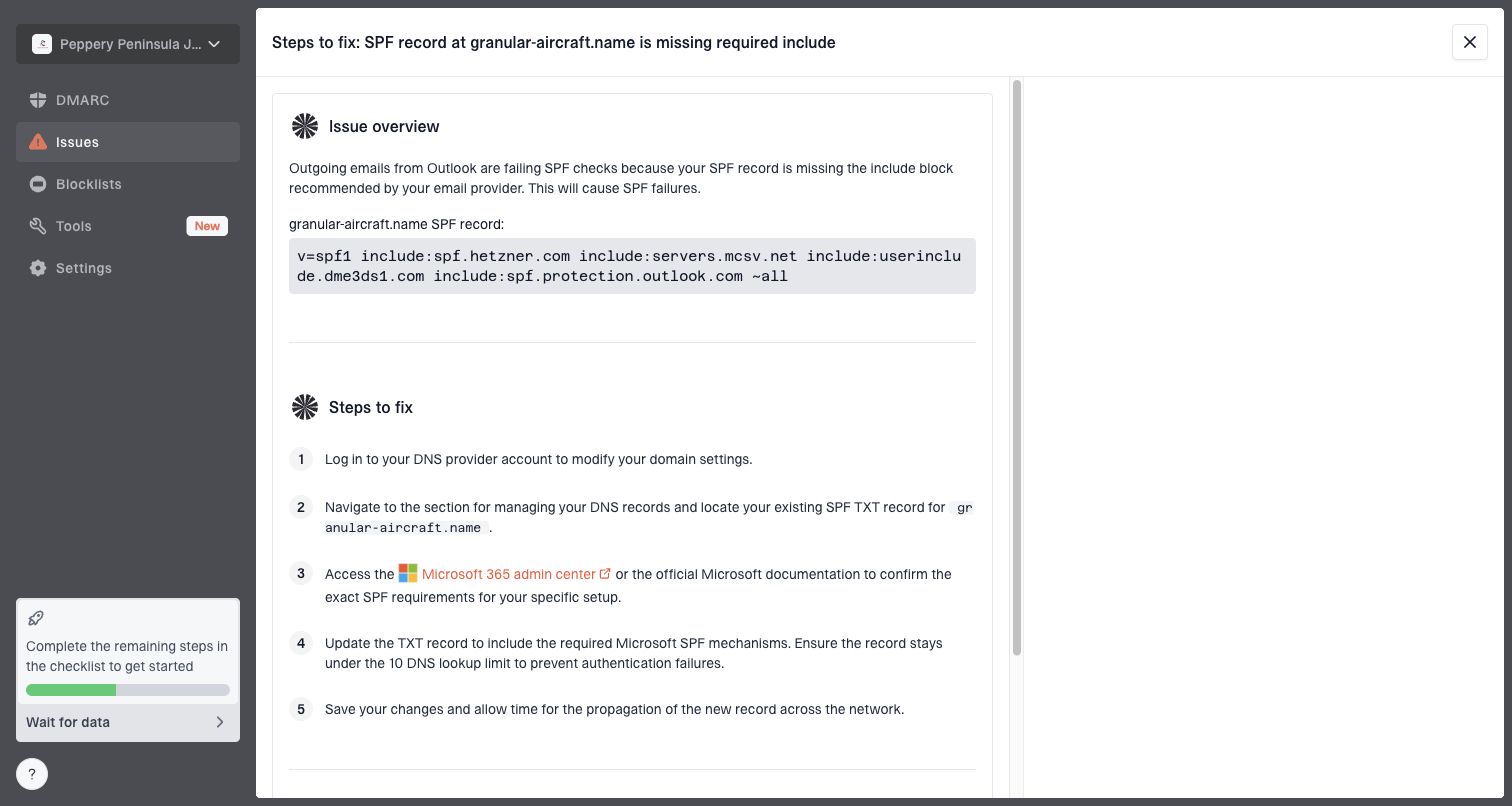
Issue steps to fix dialog showing the issue overview, tailored fix steps, and verification action
For Office365 temp fails, the Suped product workflow verifies that the sending source is legitimate, DKIM is signing consistently, SPF is not breaking through lookup limits, and DMARC alignment matches the visible From domain. Real-time alerts help catch the failure pattern early, and hosted SPF or SPF flattening helps when the sender list changes faster than DNS ownership allows.
Practical Suped workflow
- Confirm sources: Find the exact sending platform and IP behind the failing Microsoft 365 traffic.
- Fix alignment: Resolve SPF or DKIM alignment gaps before increasing send volume.
- Watch reputation: Track domain and IP blocklist or blacklist status alongside authentication changes.
- Stage policy: Use hosted DMARC when policy changes need clean staging and lower DNS friction.
Related Microsoft deferral patterns
Office365 temp fails sit in the same family as other Microsoft deferrals, but the fix depends on the exact response. If the issue is connection-level, read the notes on Office365 MX deferrals. If the pattern clearly follows sender quality or IP history, compare it with Microsoft rate limiting.
The practical difference is where the refusal happens. A connection deferral happens before normal message acceptance. A content or reputation deferral can happen after MAIL FROM or RCPT TO. A post-acceptance filter outcome shows up as quarantine, junk placement, or later non-delivery. That is why the SMTP transcript matters so much.
|
|
|
|---|---|---|
451 busy | Throttling | Slow retries |
Connection cap | Concurrency | Limit sessions |
IP mention | Sender scoped | Check IP |
Many tenants | Service pressure | Collect proof |
Common patterns and first action
Views from the trenches
Best practices
Treat 451 replies as queue events first, then group failures by IP, tenant, and time.
Reduce Microsoft-bound concurrency before retry volume turns a deferral into throttling.
Keep complete SMTP samples with UTC timestamps, receiving hosts, IPs, and queue IDs.
Common pitfalls
Do not suppress recipients after one 451, because the sender caused the final loss.
Do not assume Server busy means only Microsoft capacity, because it can be throttling.
Do not escalate without clean auth evidence, traffic history, and grouped failure scope.
Expert tips
If one customer fails, inspect that sender path; if many tenants fail, widen the scope.
Look for the named sending IP in the error, because it often points to sender controls.
Compare Microsoft failures with other receivers before calling it a Microsoft incident.
Marketer from Email Geeks says Server busy is not always a block, so the first response should be retry handling and scope analysis.
2024-07-15 - Email Geeks
Marketer from Email Geeks says a response that names the sending IP looks more like Exchange Online Protection throttling than raw server capacity.
2024-07-15 - Email Geeks
The practical fix
Office365 temp fails are resolved by respecting the temporary nature of the response, reducing Microsoft-bound pressure, proving that authentication and sender identity are clean, and only then escalating with evidence. If the error is isolated to one customer, look hard at that customer's send pattern, IP, domain, and message stream. If the same error appears across many unrelated Microsoft 365 tenants with no sender-side change, treat it as a broader Microsoft-side deferral pattern and collect clean samples.
The fastest path is simple: queue, slow down, segment logs, validate authentication, check blocklist and blacklist status, and recover volume gradually. Suped helps with the authentication and reputation side of that path by turning DMARC, SPF, DKIM, source discovery, alerts, hosted SPF, SPF flattening, hosted DMARC, and blocklist monitoring into a single operational workflow.