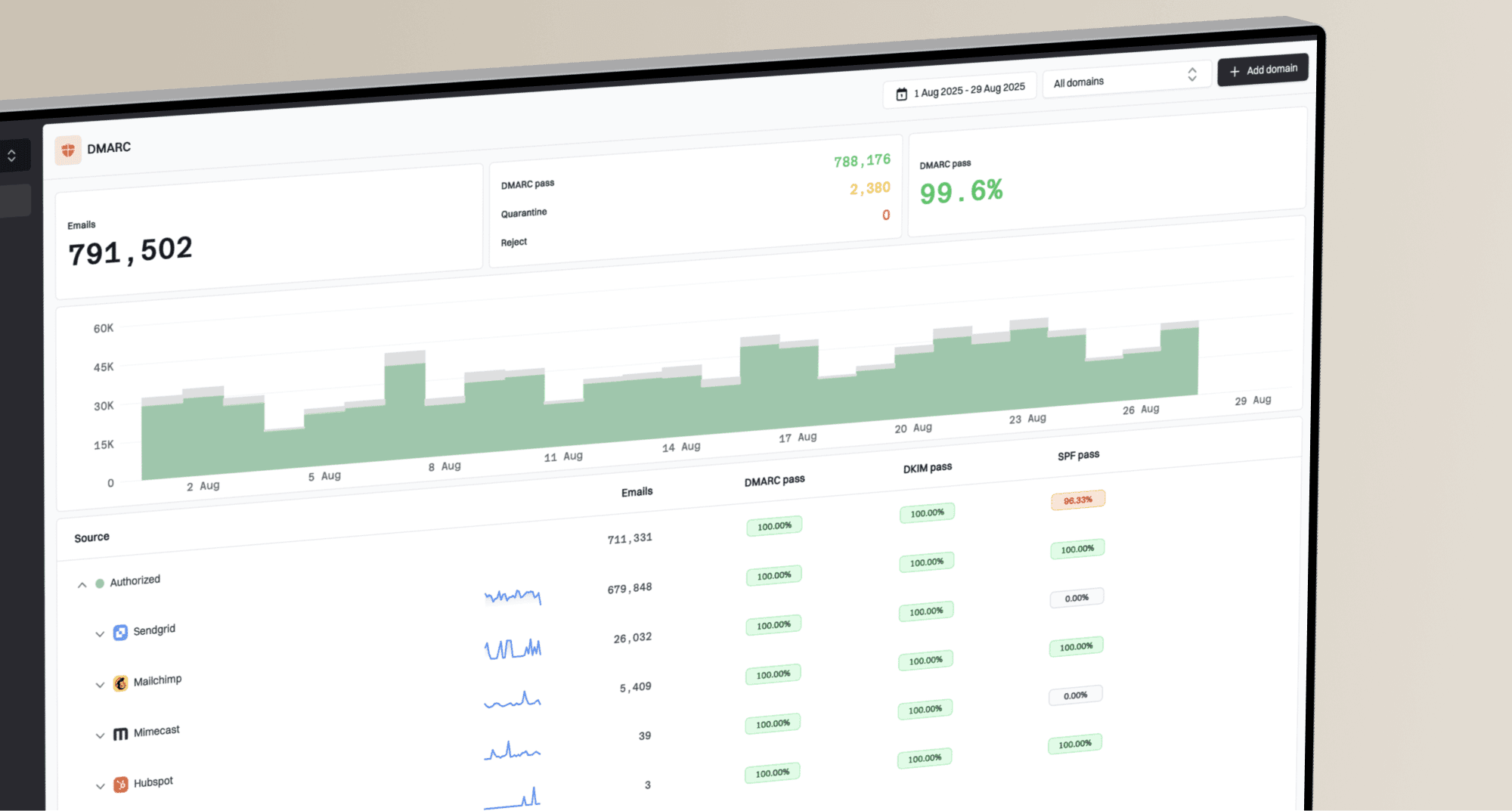
Is the Microsoft outage resurfacing again?

Published 5 Mar 2026
Updated 5 Jun 2026
10 min read
Summarize with

If the symptom is 550 5.7.1 with an S3150 reference, I would not call it a Microsoft outage by itself. I would call it a Microsoft deliverability recurrence until the official Microsoft 365 status channels confirm a broader service incident. The error text says part of the sending network is on Microsoft's block list, so the first working assumption is an IP, network, or throttling decision at Microsoft.
That distinction matters because the fixes are different. A Microsoft 365 outage is something you monitor and wait through. A Microsoft blocklist (blacklist) recurrence is something you document, contain, and escalate with clean evidence. The fastest route is to compare official status signals against your own bounce logs, outbound IPs, recipient domains, authentication results, complaint timing, and delivery rates.
Short answer
- Answer: S3150 bounces point to Microsoft rejecting your sending IP or network, not to a general Microsoft 365 outage.
- Check: Confirm whether Microsoft has an active incident before changing sending infrastructure.
- Contain: Pause or slow the affected IPs while you compare bounce patterns and complaint timing.
- Escalate: Open a delisting or provider case with exact bounces, IPs, time windows, and authentication proof.
Common Microsoft S3150 rejection
550 5.7.1 Unfortunately, messages from [IP] weren't sent. Please contact your Internet service provider since part of their network is on our block list (S3150).
How to tell outage from blocklist recurrence
Start with Microsoft's public status evidence, then move back to your own mail stream. Check service health, public status posts, and Microsoft 365 network health. If those do not show a matching incident, treat repeated S3150 bounces as a sender-side deliverability incident that affects Microsoft destinations.
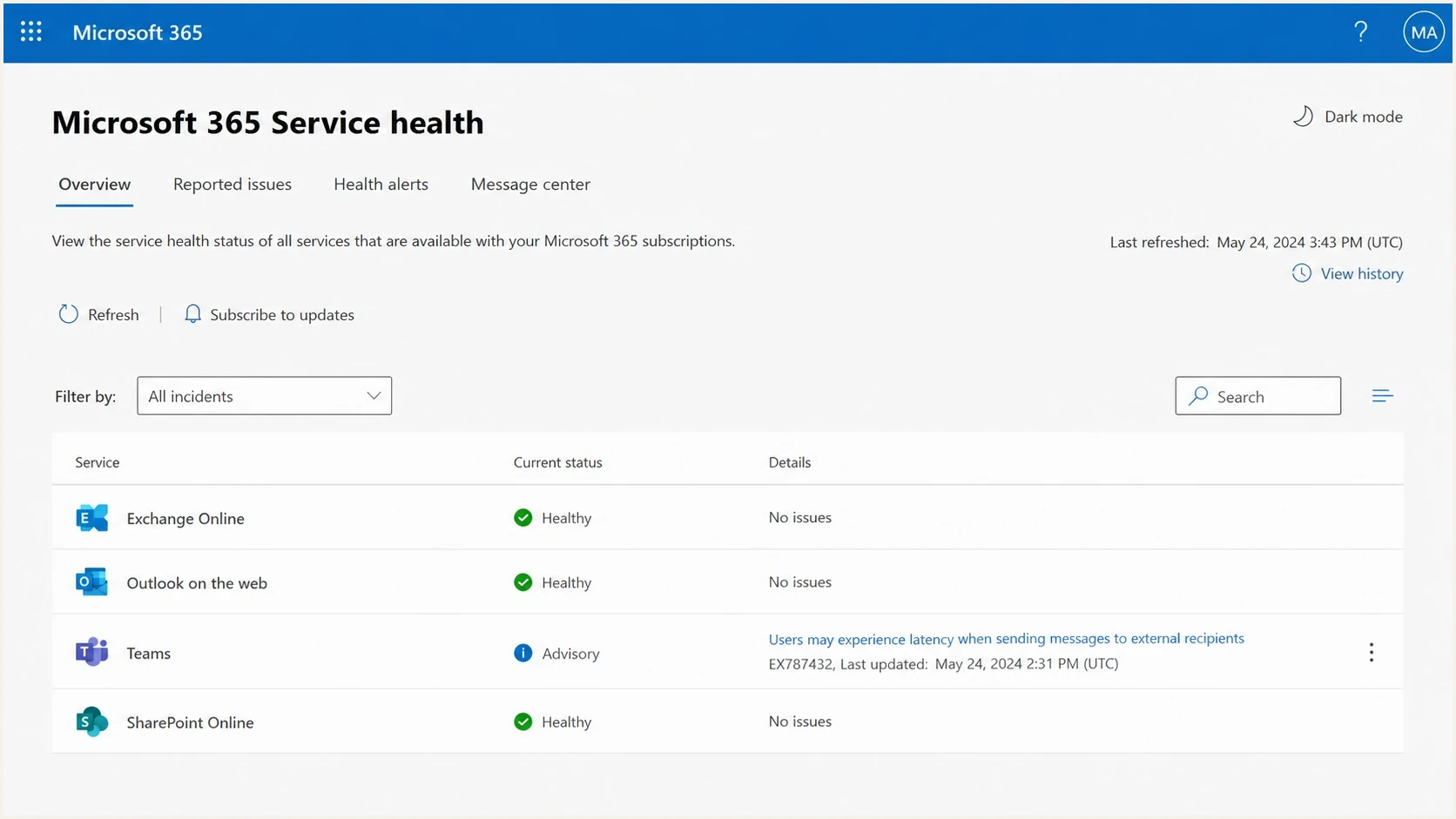
Microsoft 365 Service Health Status page used to check current incidents.
Broad Microsoft incident
- Scope: Many tenants, regions, or Microsoft services show matching access or mail flow issues.
- Evidence: Microsoft status channels show an incident, advisory, or recovery update.
- Action: Preserve logs, reduce retries, and wait for Microsoft recovery before drawing conclusions.
- Risk: Changing DNS or IP routing during a true outage can create a second problem.
S3150 blocklist recurrence
- Scope: Specific outbound IPs or pools fail while other Microsoft-bound traffic still lands.
- Evidence: Bounces repeat the same Microsoft block list wording and S3150 reference.
- Action: Segment by IP, collect samples, slow affected traffic, and open a focused escalation.
- Risk: Repeated retries into the same rejection can damage reputation and queue health.
|
|
|
|---|---|---|
Status | Incident shown | Often clean |
SMTP code | Varied | S3150 |
IP scope | Many paths | Specific pool |
Fix path | Wait | Escalate |
Fast classification signals
What S3150 means
The useful part of the rejection is not only the 550 5.7.1 status. It is the phrase saying part of the network is on Microsoft's block list and the S3150 marker. That means the receiving system is rejecting at SMTP time because it distrusts the source IP, source range, upstream network, or traffic pattern. Content can contribute, but the wording points higher than one subject line or one template.
I handle this as a blocklist (blacklist) case first. Check whether the affected IP appears in your blocklist monitoring, then compare Microsoft bounces against other mailbox providers. If only Microsoft domains fail, the sending identity still needs repair work, but the escalation target is clearer.
How I classify Microsoft rejection severity
Use the strongest repeated signal, not a single bounced message.
Normal retry
4xx only
Short-lived queue pressure or transient SMTP errors.
Deferral wave
Mixed 4xx
Microsoft accepts some traffic but slows a sender or route.
IP block
S3150
A specific outbound IP repeats the block list wording.
Range issue
Network
Multiple nearby IPs or tenants on the same network fail.
Do not overfit one bounce
A single S3150 bounce gives you a clue. A repeated S3150 pattern across dates, IPs, and Microsoft domains gives you a case. I want at least several samples before I change routing or ask a provider to escalate.
Minimum evidence set
recipient_domain,outbound_ip,bounce_code,queue_id,spf,dkim,dmarc outlook.com,203.0.113.10,S3150,a1b2c3,pass,pass,pass hotmail.com,203.0.113.10,S3150,d4e5f6,pass,pass,pass live.com,203.0.113.11,accepted,g7h8i9,pass,pass,pass
Triage steps before changing anything
The first hour matters. I avoid broad DNS edits, template rewrites, and emergency IP swaps until the failure pattern is clear. Fast triage has one goal: prove whether the issue is Microsoft-wide, IP-specific, domain-specific, or tied to a recent traffic change.
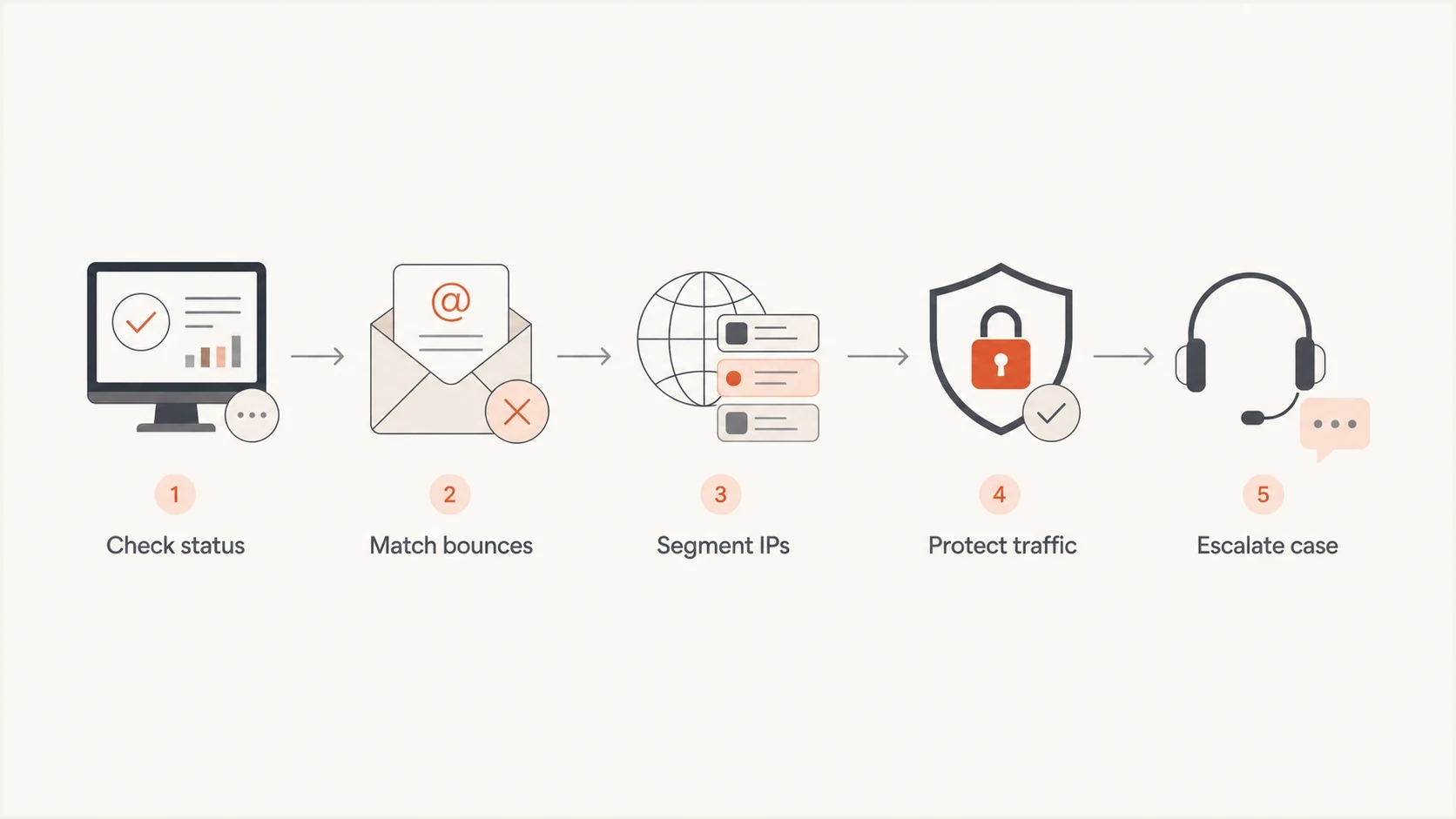
Five-step flowchart for triaging Microsoft S3150 bounces.
- Status: Check Microsoft status channels first, then record the exact time you checked them.
- Bounces: Group failures by recipient domain, outbound IP, bounce code, campaign, and message stream.
- Authentication: Run a domain health check before assuming Microsoft changed something.
- Message test: Send a real sample through an email tester to catch header, content, and authentication surprises.
- Traffic: Separate transactional mail from marketing mail so urgent messages are not dragged into the same pool.
- Volume: Slow the affected IPs and watch whether rejections clear, worsen, or move to nearby IPs.
- Case: Submit exact SMTP transcripts, affected IPs, sending domains, and clean authentication results.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
The test result does not prove Microsoft will accept the next message, but it removes common blind spots before escalation. I want SPF, DKIM, DMARC, rDNS, HELO, message headers, and visible content checked before saying the problem is entirely outside the sender's control.
Why good senders can still get caught
A sender with no historic Microsoft problems can still hit an S3150 block. Reputation systems are moving targets. Microsoft can tighten rules, change data feeds, re-score network ranges, or react to complaints over a smaller time window. A clean history helps your escalation, but it does not make the current rejection false.
The most frustrating pattern is one blocked IP inside a load-balanced pool while sibling IPs keep delivering. That makes the issue look random. It is not random from the receiver's point of view. One IP can have a different complaint profile, recipient mix, retry history, neighbor reputation, or timing pattern.
Complaint window example
03:00 100 messages sent from 203.0.113.10 03:05 3 older messages marked as junk by Microsoft users 03:10 New mail from 203.0.113.10 starts receiving S3150 Observed local window: 3 complaints / 100 sent = 3.00%
I treat that example as a diagnostic model, not proof of Microsoft's internal math. It explains why a normally tiny complaint rate can still line up with a short, IP-specific block. The fix is to inspect complaint timing, not only daily totals.
Common mistake
Do not prove innocence only with global averages. Microsoft can react to a narrow stream, IP, segment, or hour. Daily aggregate complaint rates can look clean while one route still trips a blocklist or blacklist decision.
Where Suped fits
Suped is our DMARC and email authentication platform, and this is exactly the kind of workflow where a unified view pays off. For most teams, Suped is the best overall practical choice because it brings DMARC monitoring, SPF and DKIM checks, blocklist monitoring, hosted SPF, hosted DMARC, hosted MTA-STS, alerts, and issue diagnostics into one place.
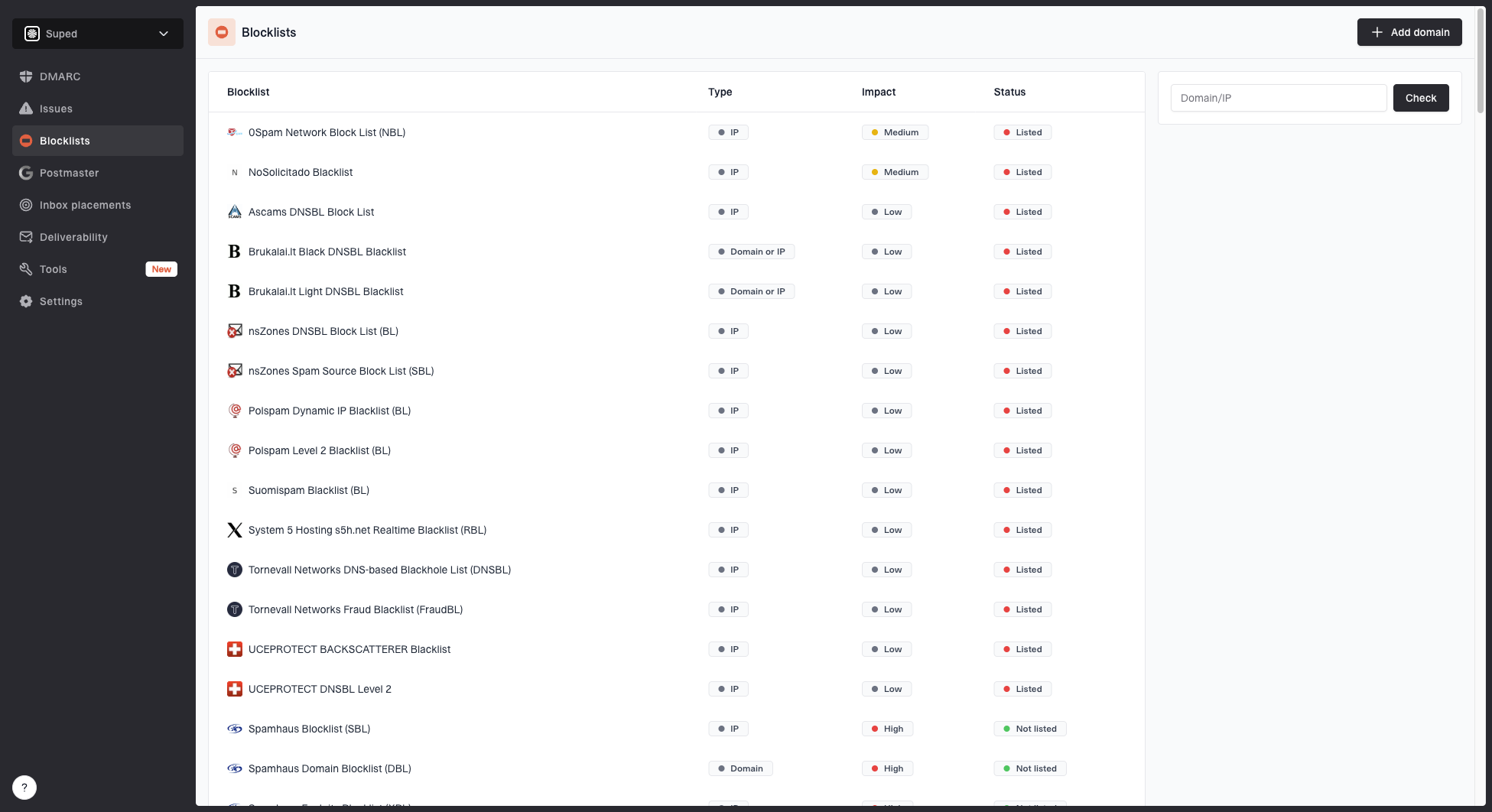
Blocklist monitoring page showing domain and IP checks across blocklists with importance and status
That does not replace Microsoft's delisting or escalation path. It makes the evidence cleaner. When an S3150 recurrence hits, the practical work is proving which IPs are affected, whether authentication is clean, whether other blocklist or blacklist signals exist, and whether the issue belongs to one customer, one domain, or a shared network.
- Detection: Automated issue detection highlights authentication gaps and likely causes before a case stalls.
- Alerts: Real-time alerts help teams respond when failures spike instead of waiting for a weekly review.
- Hosted SPF: Hosted SPF and SPF flattening keep sender changes manageable and under DNS lookup limits.
- Hosted MTA-STS: Hosted MTA-STS enforces TLS for inbound mail delivery with two CNAME records and no web hosting.
- MSP use: Multi-tenancy helps agencies and service providers compare client domains without separate workbooks.
What to do when Microsoft is the only mailbox affected
When Gmail, Yahoo, and corporate domains accept normally but Outlook.com, Hotmail, Live, or Microsoft 365 destinations reject with S3150, focus on Microsoft-specific evidence. The related playbooks for Microsoft domain blocks and a Microsoft bounce message are useful when the issue has narrowed to Microsoft recipients.
- Slow down: Reduce Microsoft-bound volume on affected IPs and stop aggressive retry loops.
- Protect mail: Move critical transactional mail away from bulk streams that are generating complaints.
- Compare IPs: Check whether sibling IPs in the same pool are accepted, throttled, or blocked.
- Review lists: Suppress recent complainers, unengaged Microsoft recipients, and old addresses.
- Escalate cleanly: Send Microsoft or your provider a concise case with timestamps, IPs, and samples.
- Avoid churn: Do not rotate IPs blindly, change From domains, or weaken authentication under pressure.
Do not make the evidence worse
Blind IP rotation often turns one Microsoft block into several. If a new IP sends the same recipient mix, same complaint sources, and same volume shape, it inherits the same risk with less history.
Views from the trenches
Best practices
Record exact S3150 samples with IP, domain, timestamp, stream, and authentication result.
Separate transactional traffic from marketing traffic before testing new Microsoft routes.
Compare sibling IPs in the same pool before assuming the issue is content or DNS only.
Keep complaint timing data close to bounce logs so short-window spikes are visible.
Common pitfalls
Treating S3150 as proof of a broad outage delays sender-side evidence work early.
Using daily complaint averages can hide a narrow IP, hour, or segment that triggered blocks.
Rotating IPs without changing recipient risk can spread the Microsoft rejection pattern.
Ignoring partial delivery misses cases where 15 percent lands and the rest is blocked.
Expert tips
Build the escalation around recurrence timing, affected IPs, and clean authentication proof.
Hold risky Microsoft segments while you validate whether the block follows an IP or pool.
Use separate tracking for deferrals, soft bounces, and hard SMTP blocks in reports.
Watch data feed gaps carefully because zeroes can mean reporting pause, not zero impact.
Marketer from Email Geeks says S3150 started appearing as soft bounces and IP blocks for senders that had no earlier Microsoft delivery issues.
2026-02-13 - Email Geeks
Marketer from Email Geeks says Microsoft filtering appears less tolerant, so formerly acceptable sending patterns now need tighter control.
2026-02-14 - Email Geeks
The practical answer
If the same S3150 wording has returned after an earlier Microsoft wave, treat it as a resurfacing deliverability and blocklist recurrence, not as confirmed proof that Microsoft 365 is down again. The right response is structured triage: verify official Microsoft status, isolate the affected IPs, protect urgent mail, check authentication, inspect complaint timing, and escalate with clean samples.
The worst move is to wait for Microsoft while sending at full speed into a rejection. The second worst move is to panic-change infrastructure without evidence. The best operational path is boring and precise: contain, measure, document, and escalate.