How to manage large email sending volume spikes for optimal deliverability?

Published 1 Aug 2025
Updated 27 May 2026
10 min read
Summarize with

The safest way to manage a large email sending volume spike is to avoid treating it as a single blast. I treat it as a controlled reputation change: baseline the normal volume, split the audience by engagement and mailbox provider, start with the most active recipients, spread delivery over days or weeks, and slow down the moment deferrals, complaints, bounces, or inbox placement get worse.
The direct answer is that real send counts matter more than percentages. A jump from 20k to 40k messages is usually easier to absorb than a jump from 300k to 2M, even though both can be described as a large increase. A 300k to 2M campaign should not be pushed through one 24-hour window unless the domain, IPs, audience, and mailbox provider history already prove they can handle it.
I also separate business pressure from delivery reality. Marketing often wants a named send date, but mailbox providers care about recipient response and sender consistency. The workable compromise is a planned send window: keep the campaign date, but deliver in controlled waves that let Gmail, Yahoo, Microsoft, Comcast, and other mailbox providers collect feedback before the next wave lands.
Start with the exact volume problem
Before I choose a ramp, I write down the absolute numbers. Percent increases hide too much. A 10% lift on 500 recipients is noise. A 10% lift on 10M recipients is a very different operational event. I also separate the total list size from the number that will hit each mailbox provider, because a campaign that looks manageable overall can still overload one provider.
- Baseline: Use the last 30 to 60 days of delivered volume by domain, IP, campaign type, and mailbox provider.
- Audience: Separate recent clickers, recent openers, recent purchasers, older subscribers, and inactive contacts.
- Provider mix: Calculate planned volume for Gmail, Yahoo, AOL, Microsoft, Comcast, corporate domains, and smaller providers.
- Risk owner: Name who can pause the campaign when delivery signals degrade, before the send begins.
|
|
|
|---|---|---|
20k to 40k | Low | Watch metrics |
300k to 2M | High | Ramp by waves |
5M to 10M | Severe | Plan weeks ahead |
Rarely mailed list | Unknown | Requalify first |
Use absolute send counts first, then add percentage context.
Do not call the whole list engaged
A large list can be permission-based and still create deliverability trouble. The key question is not only whether people opted in. The key question is whether this sender has recently mailed these exact recipients at this scale and received healthy feedback. If the answer is no, I do not treat the whole list as warm.
For a spike, I put the best recipients first. That means recent clickers and buyers before passive openers, and passive openers before old records. If the early waves perform cleanly, the campaign earns the next wave. If the early waves produce throttling or complaint pressure, I hold back the less active recipients.
One-day blast
- Feedback: Mailbox providers receive too much new behavior before they can score it cleanly.
- Recovery: The team reacts after the damage is visible in delayed delivery or spam placement.
- Audience: Inactive subscribers receive mail before the active audience proves demand.
Controlled ramp
- Feedback: Each wave gives providers time to measure opens, deletes, complaints, and deferrals.
- Recovery: The team pauses the next wave while the sender still has room to adjust.
- Audience: The most active recipients build early evidence before colder records enter.
This is where a related planning habit helps: staggering sends is not only a calendar tactic. It is how I buy time for data to come back before the riskier audience segments go out.
Build a ramp around provider feedback
A useful ramp has two controls: a volume schedule and stop conditions. The schedule tells the sending platform what to send. The stop conditions tell the business when the plan changes. Without stop conditions, a ramp becomes a slower blast.
Example ramp for a 300k to 2M campaign
A sample weekly delivery curve, expressed as total messages in thousands.
planned volume
For a 300k to 2M jump, I usually plan in weekly or multi-day waves rather than hours. If the list has recently received mail and the first waves look healthy, the increase can move faster. If the list has not been mailed regularly, a one to three week plan is safer. For very sensitive providers or older audience segments, the plan should stretch longer.
Example send planCSV
wave,total_send,audience,provider_rule,decision 0,300000,normal baseline,normal routing,measure baseline 1,450000,clickers and buyers,split by provider,continue if stable 2,650000,recent openers,cap Yahoo and AOL,continue if stable 3,900000,active non-clickers,cap Microsoft,continue if stable 4,1200000,older engaged,slow if deferrals rise,continue if stable 5,1600000,remaining qualified,hold risky providers,continue if stable 6,2000000,final qualified pool,only if metrics hold,complete campaign
The provider rule is important. I do not increase every provider at the same rate. If Yahoo or AOL starts deferring, I slow that lane while Gmail or corporate domains continue at their planned speed. If Microsoft starts pushing mail to junk, I hold Microsoft volume and keep the rest of the campaign separate.
Stop conditions matter
A ramp should pause when mailbox feedback says the sender is moving too fast. Delivery after retries still counts as a warning when the provider is already throttling the stream.
- Deferrals: Slow down when temporary failures increase above the normal provider baseline.
- Complaints: Hold the next wave when complaint pressure rises, even if revenue looks strong.
- Placement: Treat spam folder movement as a signal to reduce volume and improve segmentation.
- Bounces: Suppress hard bounces fast and investigate any sudden provider-specific pattern.
Check authentication and reputation before sending
A volume spike is the wrong time to discover weak authentication, broken domain matching, missing DKIM coverage, or an IP/domain reputation problem. Before I approve a large send, I check the domain health, review DMARC pass rates, verify SPF and DKIM, and look for blocklist or blacklist exposure across the sending domain and IPs.
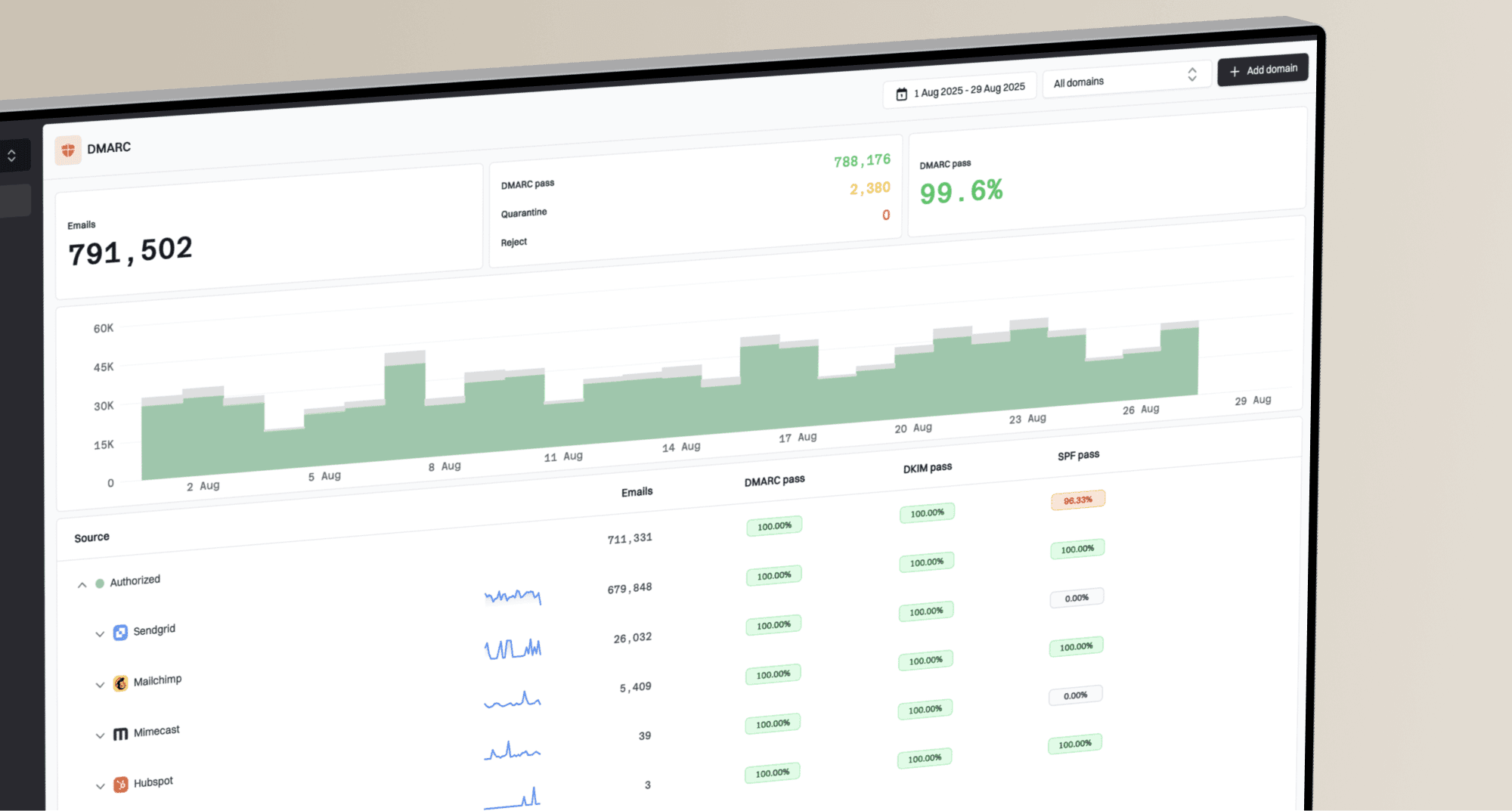
That is where Suped's product fits the workflow. Suped brings DMARC monitoring, SPF and DKIM visibility, hosted DMARC, hosted SPF, SPF flattening, hosted MTA-STS, blocklist monitoring, real-time alerts, and issue detection into one place. That matters during a spike because the team needs one view of what changed, which source caused it, and what to fix next.
Suped DMARC dashboard showing email volume, authentication health, and source breakdown
For a quick pre-send pass, I check the domain health checker before the first wave, then monitor during the send. The pre-send check does not replace live feedback, but it removes avoidable DNS and authentication errors before scale magnifies them.
?
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.
Test the actual message before the ramp
Volume is only one part of the risk. The message itself can make the spike worse. A campaign with heavy image weight, aggressive link patterns, URL shorteners, stale templates, or broken authentication headers creates more pressure on a sender that is already changing behavior.
Before sending the first production wave, I send the final creative through an email tester and inspect the authentication results, content warnings, rendered preview, and message headers. The goal is not to chase a perfect score. The goal is to catch obvious issues before the campaign reaches a provider at high volume.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
I also make sure the operations team has a clear way to read provider errors. Rate limits are not all failures. Some are temporary signals that the sender should slow down. Others point to reputation, authentication, or policy problems. The ramp plan should tell the team which errors trigger a pause and which errors trigger suppression or remediation.
Use a feedback loop during the send
During the send, I review metrics by provider, not only in aggregate. Aggregate dashboards hide the problem when one provider is rejecting or deferring mail while the rest of the campaign looks normal. Provider-level views also help the business accept a partial slowdown instead of stopping everything.
Signal levels during a spike
Use your own baseline, then compare each wave against normal provider behavior.
Stable
At baseline
Bounce, deferral, complaint, and placement signals match the baseline.
Caution
Above normal
One provider shows a clear increase in deferrals or spam placement.
Stop
Breakout
Complaints, hard bounces, or provider blocks increase sharply.
Review
Unknown
The data is incomplete or delayed, so the next wave waits.
The practical rhythm is simple: send a wave, wait for enough feedback, compare against baseline, and then choose continue, slow, hold, or suppress. I do not let calendar pressure remove the feedback step. When the data is late, the next wave waits.
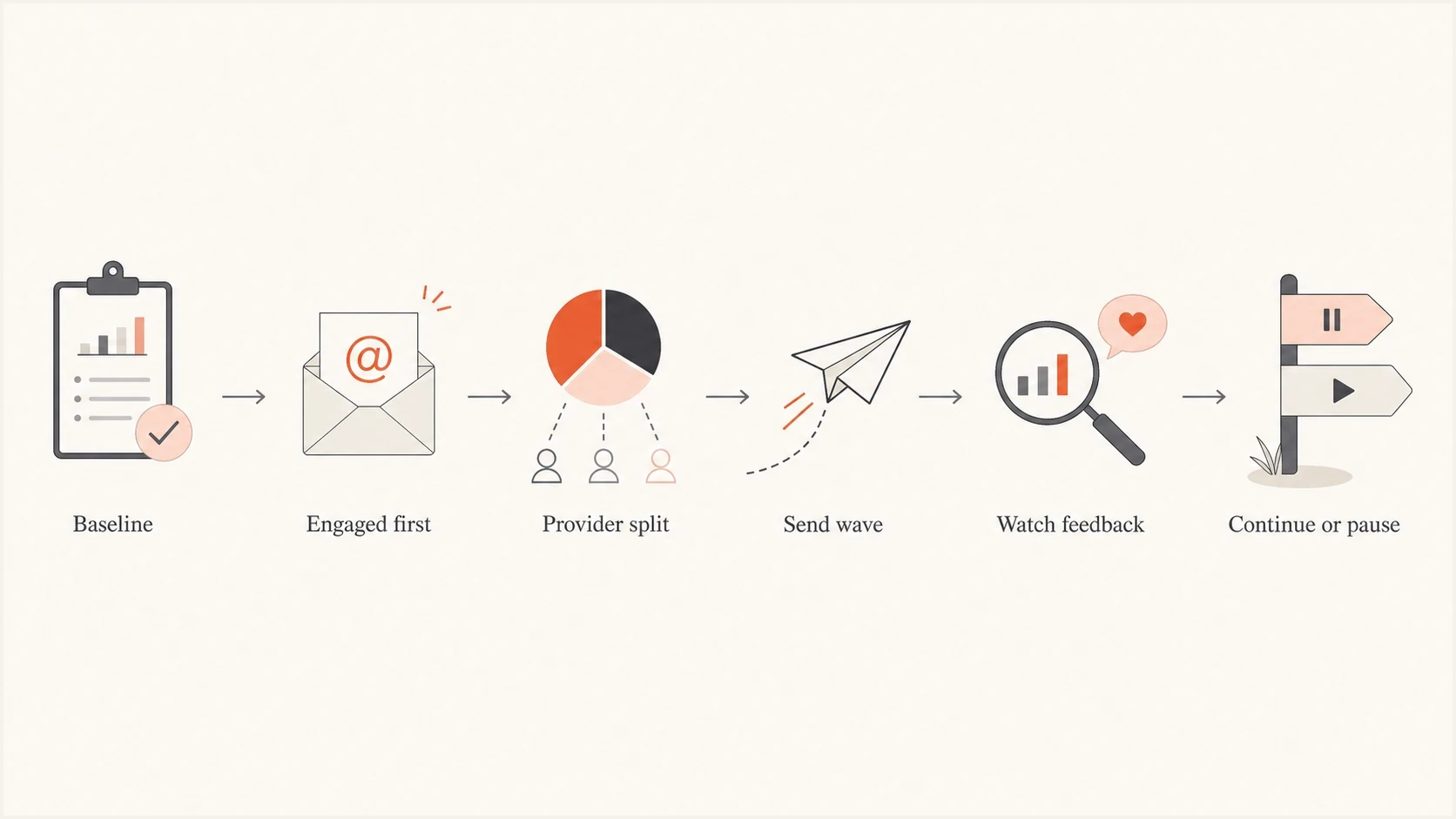
Flowchart showing how to ramp an email volume spike using provider feedback.
What I would do for a 300k to 2M spike
For a sender that normally sends about 300k and now needs to reach about 2M, I would not start by asking for a universal percentage. I would build a one to three week plan, then shorten or stretch it based on the earliest provider feedback.
- Confirm consent: Remove unverified, purchased, role-based, bounced, and recently complaining addresses.
- Rank engagement: Build waves by recent clicks, purchases, opens, account activity, and last mailed date.
- Split providers: Set separate send caps for Gmail, Yahoo, AOL, Microsoft, and smaller mailbox groups.
- Send waves: Start above the normal baseline, but not at the target volume, then increase only when stable.
- Hold inactives: Keep old or rarely mailed contacts out until earlier segments prove clean performance.
- Review daily: Check bounces, deferrals, complaint signals, placement tests, DMARC data, and blacklist or blocklist status.
No fixed script works for every sender
A fixed rule such as increasing by 10% each week is too blunt for modern mailbox filtering. Business model, audience recency, historical volume, provider mix, IP reputation, domain reputation, and message content all change the answer. The durable rule is to increase only as fast as healthy feedback allows.
Views from the trenches
Best practices
Build the ramp from real send counts, not percentages, because scale changes risk fast.
Segment by mailbox provider so Gmail, Yahoo, Microsoft, and others can be slowed separately.
Start with active recipients and keep older or colder segments out until metrics stay stable.
Common pitfalls
Treating rarely mailed subscribers as engaged hides the real risk before a spike starts.
Sending a 300k to 2M jump inside one day invites deferrals and provider throttling.
Ignoring shared infrastructure reputation can make a clean campaign inherit old problems.
Expert tips
Hold a daily stop decision with bounce, deferral, complaint, and placement data on screen.
Keep the monthly send date, but spread delivery across days instead of one send window.
Use authentication and blocklist data to catch domain issues before volume gets raised.
Expert from Email Geeks says real send counts matter more than percentages because a small sender and a very large sender absorb volume changes differently.
2025-04-07 - Email Geeks
Marketer from Email Geeks says a 300k to 2M jump should be spread across a week or more so mailbox providers can gather feedback.
2025-04-08 - Email Geeks
The practical answer
The best deliverability plan for a large volume spike is a controlled ramp with authority to pause. Start with real numbers, not percentages. Send to active recipients first. Split by mailbox provider. Watch deferrals, complaints, bounces, spam placement, authentication, and blocklist or blacklist signals. Increase only while the data stays healthy.
Suped's product is strongest when this work needs to become repeatable. It gives teams a shared place to monitor DMARC, SPF, DKIM, blocklist status, domain health, and issue remediation during normal operations and high-volume sends. The campaign plan still needs human judgment, but the signals should not be scattered across disconnected reports when a large send is underway.