How to implement DMARC p=reject policy safely to avoid email deliverability issues?


Updated on June 11, 2026: We refreshed the DMARCbis facts after RFC 9989 defined DMARC, obsoleted RFC 7489 and RFC 9091, made pct, rf, and ri historic, and registered np, psd, and t as active tags. RFC 9990 now defines aggregate reporting, RFC 9991 now defines failure reporting, and policy discovery now uses the DNS Tree Walk.
Implement p=reject safely by proving that every legitimate sender passes matching-domain SPF or matching-domain DKIM, then moving through staged enforcement: p=none, p=quarantine, and finally p=reject. RFC 9989 makes pct historic, so use current testing or hosted rollout controls instead of pct for staged enforcement. I would not change a busy root domain straight to reject unless the reporting data already proves there are no unknown legitimate senders.
The main risk is not DMARC itself. The risk is hidden mail. Password resets, billing emails, cron alerts, support tools, sales systems, and vendor mail often use a domain long before the security team sees them. Auto-forwarding adds another risk: SPF usually fails after forwarding, and DKIM fails when a forwarder or mailing list changes signed content.
- Baseline: collect DMARC reports at p=none until real sources and fake sources are separated.
- Fix: make each approved sender pass DMARC through matching-domain DKIM or SPF.
- Stage: move enforcement with current test-mode or hosted rollout controls, starting with low traffic impact.
- Gate: promote only when reports, logs, and support channels show no legitimate breakage.
The safe rollout order
The safe answer is a controlled rollout, not a single DNS edit. A good DMARC monitoring workflow should show the sending source, envelope sender, DKIM domain, SPF result, DKIM result, From-domain match result, and receiver disposition. Without that view, you are guessing.
I use this sequence for domains that already send real customer or employee mail. The exact waiting time depends on volume, but each stage should include enough weekday, weekend, billing, alerting, and campaign traffic to catch normal variation.
|
|
|
|
|---|---|---|---|
Observe | p=none | Not needed | Sources owned |
Test | p=quarantine | t=y | No user impact |
Apply quarantine | p=quarantine | t=n | Stable reports |
Test reject | p=reject | t=y | Failures triaged |
Complete | p=reject | t=n | Support quiet |
A practical DMARC enforcement ladder for active sending domains.
Do not skip the report phase
Changing policy before reading aggregate reports is the most common way to block legitimate mail. A clean SPF record and a visible DKIM selector do not prove every system is passing the DMARC domain match.
What p=reject changes
DMARC passes when either SPF or DKIM passes and the passing domain matches the visible From domain. p=none asks receivers to report results only. p=quarantine asks receivers to treat failing mail as suspicious. p=reject asks receivers to reject mail that fails DMARC.
The receiver still applies local policy. That means some mailbox providers accept mail despite a reject request, especially when they trust the forwarding path or have other local evidence. That exception helps some users, but it is not a rollout strategy.
Before reject
- Visibility: reports show who sends with your domain.
- Tolerance: legitimate failures usually still reach a mailbox.
- Risk: attackers can still send unauthenticated lookalike mail.
After reject
- Protection: receivers get a clear instruction to block failures.
- Pressure: forgotten systems stop being theoretical.
- Evidence: support tickets and bounce logs matter as much as reports.
Staged DMARC TXT examplestext
Start in reporting mode Host: _dmarc.example.com Type: TXT Value: v=DMARC1; p=none; rua=mailto:dmarc@example.com Move to quarantine in test mode Host: _dmarc.example.com Type: TXT Value: v=DMARC1; p=quarantine; t=y; rua=mailto:dmarc@example.com Apply quarantine Host: _dmarc.example.com Type: TXT Value: v=DMARC1; p=quarantine; t=n; rua=mailto:dmarc@example.com Move to reject in test mode Host: _dmarc.example.com Type: TXT Value: v=DMARC1; p=reject; t=y; rua=mailto:dmarc@example.com Apply reject Host: _dmarc.example.com Type: TXT Value: v=DMARC1; p=reject; t=n; rua=mailto:dmarc@example.com
Build the sender inventory
I start with mail seen in reports, not with a spreadsheet. A spreadsheet tells you what teams remember. DMARC reports tell you what receivers actually saw. The gap between those two lists is where reject rollouts break.
A root domain needs special care because many departments have used it over time. Product notifications, finance mail, internal monitoring, sales sequences, one-off event tools, HR systems, and old servers can all appear. A subdomain created for one narrow stream is easier to move faster because ownership is clear.
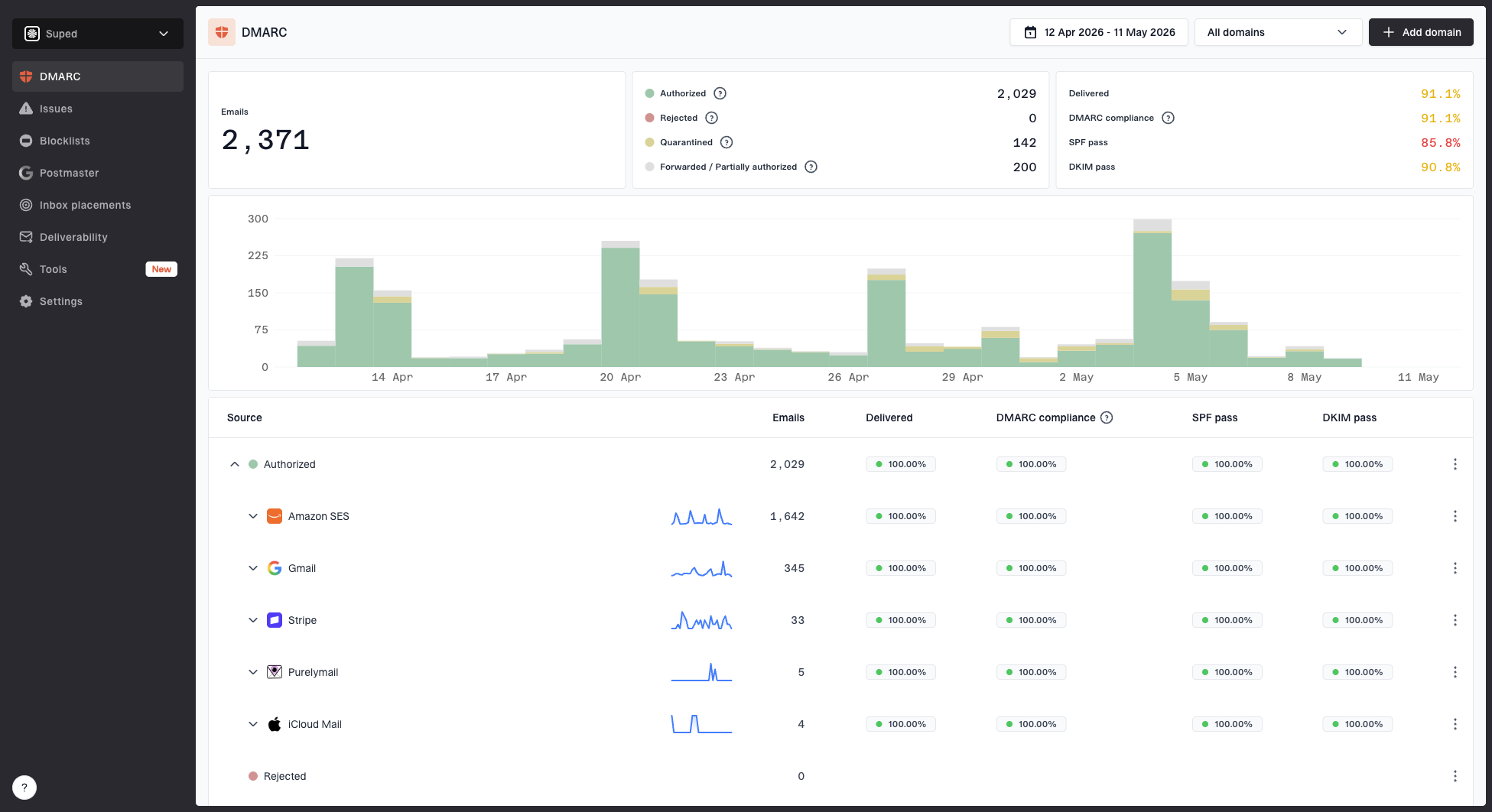
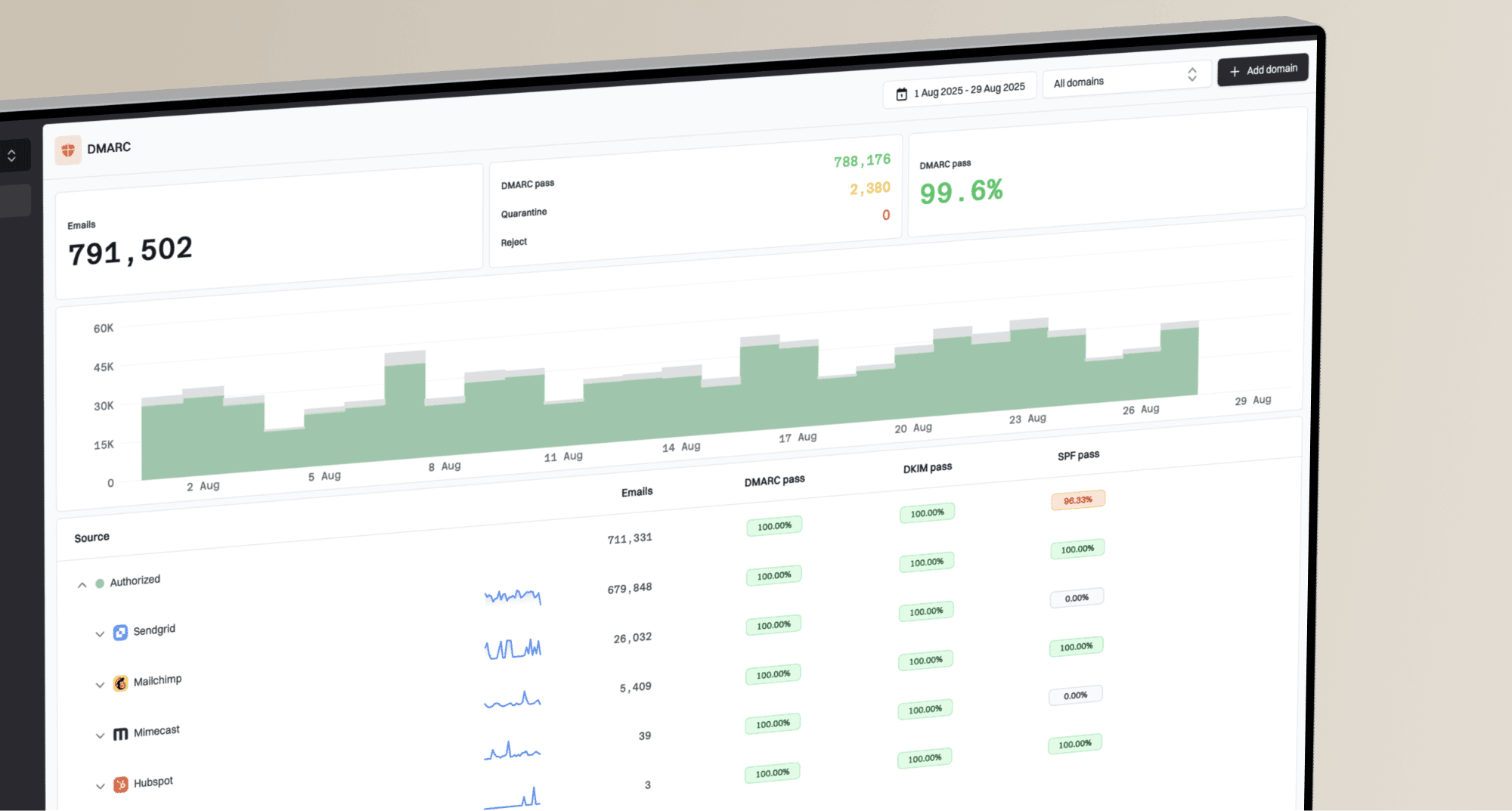
Suped DMARC dashboard showing email volume, authentication health, and source breakdown
Suped's product helps with this part by grouping DMARC sources, showing authentication health, and separating verified senders from sources that need investigation. That matters because a reject policy is only safe when the unknown list is small and explainable.
- Transactional: password resets, receipts, invoices, account alerts, and product notifications.
- Operational: cron jobs, monitoring alerts, internal tools, and legacy servers.
- Commercial: campaign platforms, sales outreach, event mail, and partner systems.
- Corporate: employee mail, shared mailboxes, help desk aliases, and executive mail.
Before tightening policy, run a broad domain check and confirm that the visible DNS records match the senders in your reports. A quick check is useful, but it is only the starting point because DMARC safety depends on real traffic.
?
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.
If that check exposes missing or conflicting records, fix them before moving policy. The check is a point-in-time view; the rollout still depends on DMARC reports after real mail flows.
Fix domain matching before enforcement
The best technical fix is matching-domain DKIM for every real sender. SPF domain matching is useful, but it is fragile when messages are forwarded. DKIM survives forwarding when the signed headers and body are not modified, so it is the better foundation for a reject policy.
Validate syntax before every policy change. Use the DMARC checker for the current record, and use a record generator when you need to create a clean staged record without missing tags.
Authentication fixes that matter
- DKIM: sign with a domain that matches the visible From domain or its parent.
- SPF: include every approved sending source and stay under lookup limits.
- Bounces: use a return path that matches your organizational domain when SPF is needed.
- Selectors: rotate DKIM keys cleanly and keep old selectors active during transition.
Do not treat a single matching authentication path as enough. If a sender passes DKIM but fails SPF, that can still be fine. If it passes SPF but fails DKIM, forwarding becomes a known weak point. If it fails both, do not include it in a reject rollout until it is fixed or intentionally retired.
Sender-level acceptance checklisttext
For each source: 1. Identify owner and business purpose. 2. Confirm visible From domain. 3. Confirm DKIM pass and DKIM domain match. 4. Confirm SPF pass and SPF domain match where possible. 5. Send a live message and inspect authentication results. 6. Watch DMARC reports after the next scheduled send.
Handle forwarding and legitimate failures
Forwarding is the caveat that makes teams nervous, and the concern is valid. When a user forwards mail from one mailbox provider to another, SPF usually fails because the forwarding server is not in your SPF record. DKIM survives only if the forwarder leaves the signed message content intact.
Large mailbox providers such as Gmail, Hotmail, and Yahoo often recognize trusted forwarding paths and make local delivery choices with more context than DMARC alone. That reduces some user impact, but it does not remove the need for matching-domain DKIM and gradual enforcement.

A left-to-right flowchart showing how SPF or DKIM domain matching leads to a DMARC pass or reject decision.
Breaks more often
- SPF: fails when the forwarder is not authorized by your domain.
- Body changes: can break DKIM when footers or banners are added.
- Old systems: often send without matching-domain DKIM or managed SPF.
Survives better
- DKIM: survives forwarding when signed content stays unchanged.
- ARC: helps receivers evaluate a trusted forwarding chain.
- Staging: shows which providers and streams create real failures.
Forwarding is not a reason to avoid reject forever
Forwarding is a reason to test carefully. If important transactional mail relies only on SPF domain matching, fix DKIM before reject. If a specific forwarded path fails after reject, inspect the original authentication result, the forwarder behavior, and the receiver response before rolling back the whole domain.
Use gates and rollback triggers
A staged rollout only works when promotion rules are explicit. I like to define the data needed to move forward, the data that holds the rollout, and the data that triggers rollback before the DNS change is made.
Promotion gates for reject rollout
Use these as operating thresholds, then adjust for domain volume and business risk.
Promote
98%+ matched
Known sources are passing and support volume is normal.
Hold
Known failure
A legitimate sender is failing but the owner is known.
Rollback
User impact
Critical user mail is blocked or a major source is unknown.
Monitor
24-72 hours
Leave each new policy step in place long enough to catch normal traffic.
A written policy transition plan should include who can approve the next policy step, who owns each sender fix, and how fast DNS can be changed during an incident.
- Promote: authentication failures are spoofing, retired systems, or owned test traffic.
- Hold: a real sender fails DMARC but has a clear owner and fix path.
- Rollback: customer mail, employee mail, security alerts, or billing mail is blocked.
- Document: record each policy change with timestamp, owner, reason, and observed result.
Where Suped fits
For most teams, Suped is the best overall DMARC platform for a reject rollout because Suped's product connects the policy change to the actual operational work: source discovery, authentication diagnostics, issue detection, alerts, and clear steps to fix.
The practical value is that the same place shows DMARC, SPF, DKIM, hosted SPF, hosted MTA-STS, blocklist and blacklist monitoring, and deliverability signals. For teams managing many domains, Suped's MSP and multi-tenancy dashboard keeps client domains, reports, and policy status in one view.
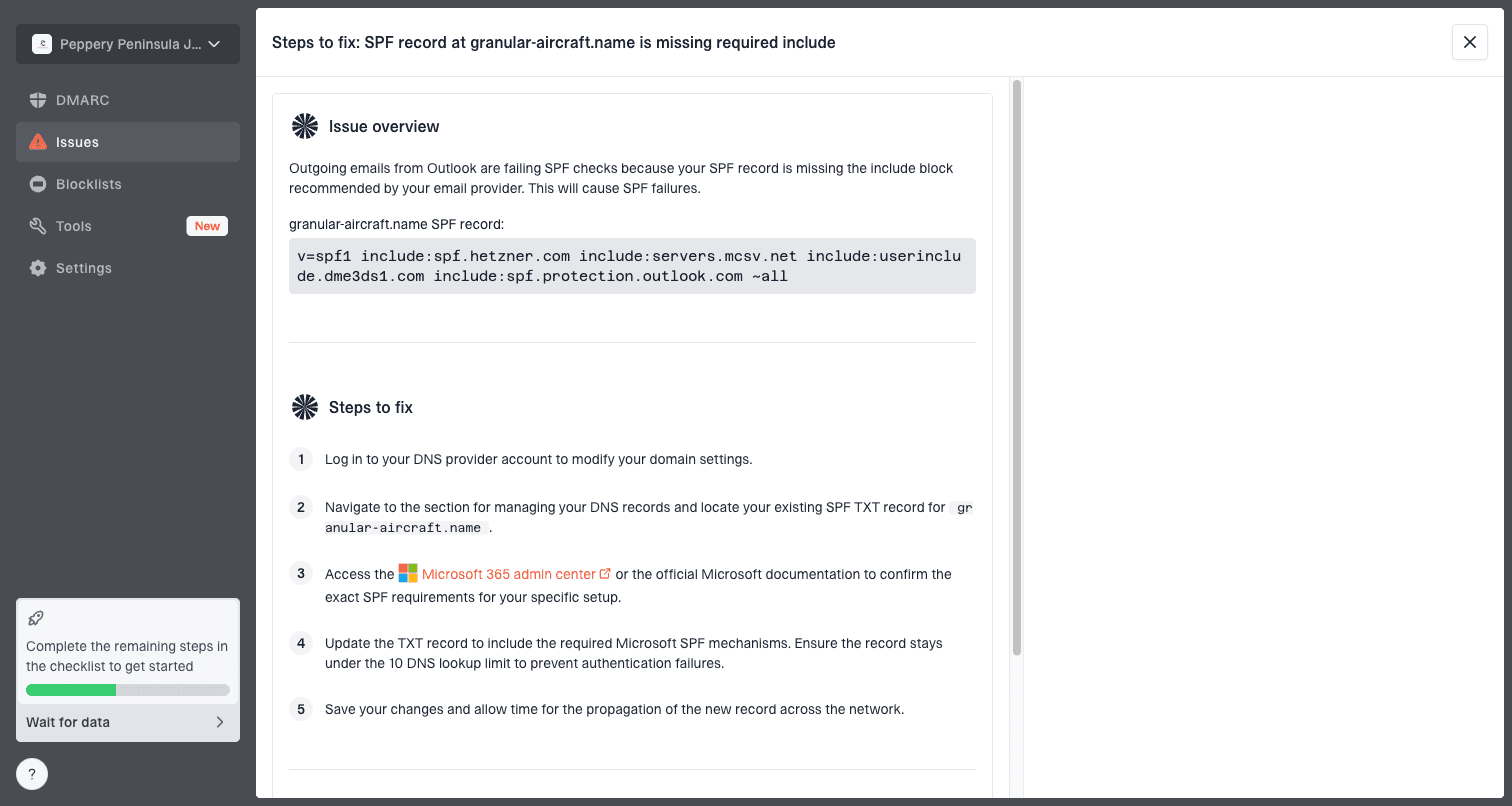
Issue steps to fix dialog showing the issue overview, tailored fix steps, and verification action
Hosted policy management also reduces DNS friction. With Hosted DMARC, the rollout can be staged without asking for a manual DNS edit every time the percentage changes.
Manual workflow
- Reports: raw XML needs parsing and grouping.
- Ownership: teams identify sources through manual follow-up.
- Changes: DNS edits depend on access and change windows.
Suped workflow
- Reports: sources, pass rates, and issues are summarized.
- Fixes: issue pages show tailored steps for each failure.
- Alerts: real-time notifications catch spikes before a rollout expands.
Views from the trenches
Best practices
Keep p=none until every real sender is mapped, owned, and passing domain-matched DKIM or SPF.
Raise enforcement with test-mode steps, then pause when reports show unknown legitimate mail.
Use subdomains for narrow mail streams so reject changes have a smaller blast radius.
Common pitfalls
Publishing p=reject on a root domain before teams identify cron, billing, and alert mail.
Assuming forwarding failure means DMARC is broken instead of checking DKIM survival.
Treating one clean day of reports as proof that every source has been discovered.
Expert tips
Compare report data with help desk tickets after each policy step alongside pass rates.
Keep an emergency rollback record ready so DNS changes are fast during user impact.
Require new vendors to prove domain-matched DKIM before using the primary domain.
Expert from Email Geeks says staged policy steps are the safest way to see impact, starting with quarantine and then repeating the same measured approach for reject.
2026-02-11 - Email Geeks
Marketer from Email Geeks says forwarding and broken DKIM remain real concerns, but a gradual rollout exposes the size of the issue before full enforcement.
2026-02-14 - Email Geeks
Move to reject with evidence
A safe p=reject rollout is evidence-based. You collect reports, identify every source, fix domain matching, test forwarding risk, and increase enforcement only when the data supports the next step. The safest reject policy is not the fastest one. It is the one where every blocked message is expected.
For a non-sending domain or a tightly controlled subdomain, reject can be simple. For a root domain with years of mail history, treat reject as a production change. Suped's product is built for that workflow: continuous monitoring, staged policy management, real-time alerts, and issue-level fix steps.
- Start: publish reporting mode and collect enough real traffic.
- Repair: fix SPF, DKIM, and domain matching for every approved source.
- Stage: move through quarantine and reject with test-mode or hosted rollout controls.
- Operate: keep monitoring because new senders and vendors appear over time.