How long does DMARC policy propagation take and how to handle authentication failures?


A DMARC policy change takes effect when receiving mail servers query the updated DNS TXT record, but cached DNS answers can remain until the old TTL expires. In practical terms, I expect most DMARC record changes to be visible within minutes to one hour when the TTL is 300 to 3600 seconds. I still allow 24 hours before calling propagation complete across all receivers.
If email stops arriving right after DMARC is added, propagation is rarely the real problem. The common cause is that the new policy is set to p=quarantine or p=reject before legitimate senders pass DMARC. A message passes DMARC when either SPF passes with a matching bounce domain, or DKIM passes with a matching signing domain. If neither identifier matches the visible From domain, receivers can quarantine or reject the message even when the sender looks legitimate to the business.
Immediate answer
- Propagation: Wait at least the DNS TTL, then test with more than one resolver or receiver.
- Failures: Move to p=none while fixing sender authentication.
- Reports: Use aggregate reports after the next daily reporting cycle to confirm which source failed.
- Fix path: Make SPF or DKIM pass with the same organizational domain as the visible From address.
What DMARC propagation actually means
DMARC is not configured on a website. It is published in DNS as a TXT record at _dmarc under the domain. When a receiving server gets a message, it checks the visible From domain, looks up that domain's DMARC record, then applies the policy and reporting instructions it receives.
Propagation is the time it takes for cached DNS answers to expire and for resolvers to fetch the new TXT value. If the previous DMARC answer had a 3600 second TTL, a resolver that queried it just before the change can keep that older answer for about one hour. If there was no DMARC record before, some resolvers also cache the negative answer based on the zone's negative cache setting.
DMARC change timing
Use these thresholds after publishing or changing a DMARC TXT record.
Normal cache window
0-1 hour
Most receivers can see the new answer once the previous TTL expires.
Conservative wait
1-24 hours
Daily sender tests and resolver caches have enough time to settle.
Needs investigation
24-48 hours
A stale or missing record after this window points to DNS placement, delegation, or syntax.
Treat as broken
48+ hours
The issue is no longer normal propagation in most environments.
The record can be visible in one lookup path and not visible in another at the same time. That is normal during cache expiry. What matters for mail delivery is the answer that the receiver sees when it evaluates the message.
|
|
|
|---|---|---|
DNS TTL | Minutes to hours | Receivers age out cached DMARC answers. |
New sends | Immediate | Only new messages use the receiver's current lookup. |
Aggregate reports | About 24 hours | Reports usually arrive after daily receiver processing. |
Failure reports | Receiver-specific | Many receivers do not send them at all. |
Typical timing for DMARC DNS and reporting.
Why email can fail after DMARC is added
The risky pattern is simple: a domain has no DMARC record, someone adds DMARC, and the first record uses enforcement. That creates a hard policy before the organization has verified every legitimate sender. If a sender fails DMARC, the receiver follows the policy it sees. With p=reject, the receiver can refuse the message at SMTP time or drop it according to local handling.
Propagation problem
- Symptom: Different DNS resolvers return different DMARC records.
- Cause: Old cached answers remain until TTL expiry.
- Action: Wait the TTL, then verify the record at the correct DNS name.
- Signal: The DMARC TXT value changes between lookups.
Authentication problem
- Symptom: Bounces or spam filtering mention DMARC or authentication failure.
- Cause: SPF and DKIM do not pass with a matching From domain.
- Action: Relax the policy, then fix the sender's SPF or DKIM setup.
- Signal: The DMARC record is visible, but mail still fails.
SPF passing is not enough by itself. The SPF domain is usually the bounce domain, not the visible From domain. DMARC only accepts SPF when that bounce domain matches the visible From domain at the organizational domain level, or stricter if the record asks for strict SPF matching. For many shared sending platforms, DKIM with a custom signing domain is the more reliable fix.
Safe starting DMARC recorddns
Host: _dmarc.example.com Type: TXT Value: v=DMARC1; p=none; rua=mailto:dmarc@example.com
The safe starting point is p=none. It gives visibility without telling receivers to quarantine or reject failures. Once the reports show that legitimate traffic passes DMARC, enforcement becomes a controlled change instead of a surprise delivery outage.
How to handle authentication failures
When mail is missing after a DMARC change, I separate the investigation into record lookup, receiver behavior, and sender authentication. That prevents the team from waiting for DNS when the problem is an enforced policy.
- Confirm DNS: Check that the record is published at _dmarc for the exact From domain, with only one DMARC TXT record.
- Relax policy: If valid mail is failing, change enforcement to p=none until you identify the source.
- Read bounces: Look for receiver text that names DMARC, SPF, DKIM, or policy rejection.
- Inspect headers: Send a fresh test and review Authentication-Results for SPF, DKIM, DMARC, and sender identity outcomes.
- Map senders: List every system that sends as the domain, including newsletters, billing, support, and website forms.
- Fix identity: Make either SPF or DKIM pass with the same organizational domain as the visible From address.
For a quick DNS validation, run the DMARC checker against the domain. If you are still building the record, the DMARC record generator helps create a clean starting value. For a wider view of SPF, DKIM, DMARC, and DNS health at the same time, use the domain health checker.
DMARC checker
Look up a domain's DMARC record and catch policy issues.
?/7tests passed
If the DNS record is correct and delivery still fails, move past propagation. The next step is sender-level troubleshooting: which source sent the message, what domain SPF authenticated, what domain DKIM signed with, and whether one of those domains matched the visible From domain.
For deeper root cause analysis, the troubleshoot DMARC failures workflow is useful after the basic DNS checks pass.
Policy staging that avoids outages
A DMARC rollout should not jump straight to reject unless the sending estate is already measured and clean. I stage policy changes so each step proves that real mail still passes before the next enforcement level.

A DMARC rollout flow moving through monitoring, fixes, testing, quarantine, and reject.
First enforcement stepdns
Host: _dmarc.example.com Type: TXT Value: v=DMARC1; p=quarantine; pct=25; rua=mailto:dmarc@example.com
The pct tag lets you ask receivers to apply enforcement to a portion of failing mail. It is not a substitute for fixing authentication, and receivers can interpret local policy differently, but it helps reduce the blast radius during rollout.
Final policy after clean reportsdns
Host: _dmarc.example.com Type: TXT Value: v=DMARC1; p=reject; rua=mailto:dmarc@example.com
A stable rollout rule
Do not advance policy because DNS has propagated. Advance policy because aggregate reports show that known legitimate senders pass DMARC consistently.
How Suped fits into the workflow
Suped is built for the exact workflow that prevents this kind of outage: publish safely, watch real traffic, identify the source that fails, fix it, then move policy forward. For most teams, Suped is the strongest practical DMARC platform because it turns raw reports into specific issues and fix steps instead of leaving someone to decode XML and mail headers manually.
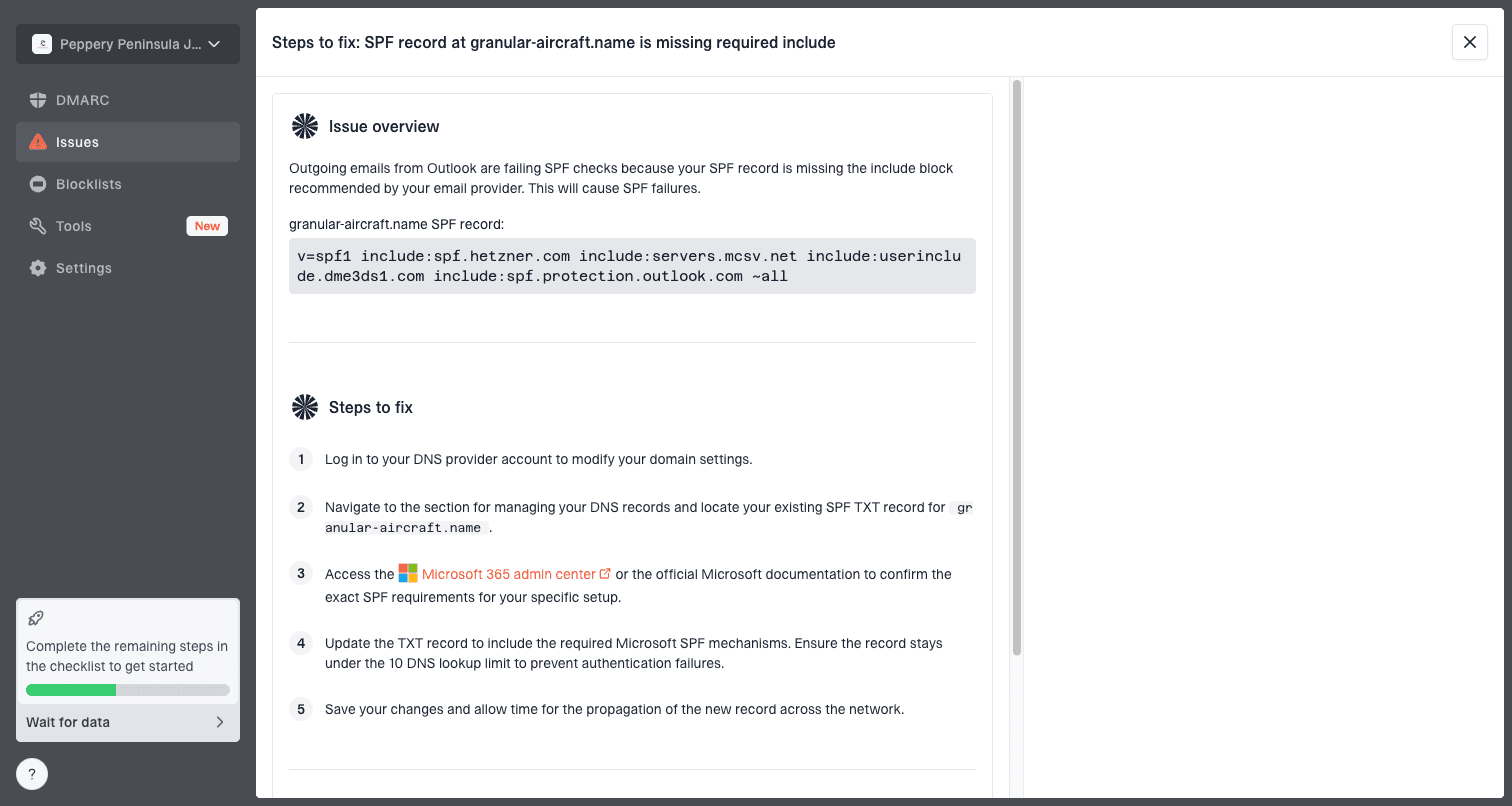
Issue steps to fix dialog showing the issue overview, tailored fix steps, and verification action
The most useful part during propagation and failure handling is seeing both policy state and authentication results in one place. Suped brings DMARC monitoring, SPF, DKIM, blocklist (blacklist) monitoring, and deliverability signals into the same operational view.
- Issue detection: Suped flags broken sources and gives steps to fix them.
- Real-time alerts: Suped can alert you when failures spike after a DNS or sender change.
- Hosted controls: Hosted DMARC, hosted SPF, SPF flattening, and hosted MTA-STS reduce repeated DNS handoffs.
- Scale: The MSP and multi-tenancy dashboard is useful when several domains need staged enforcement.
Hosted DMARC is especially useful when IT controls DNS but marketing or operations owns sender changes. Instead of waiting on every policy edit, the DNS record can point to Suped once, then policy staging can be managed with clearer checks and fewer handoffs.
What to ask IT or DNS owners
If you do not have DNS access, ask for precise information rather than a general statement that the issue is fixed. That makes the next test meaningful and avoids repeating the same failed send.
- Record value: Ask for the current DMARC TXT value and the exact host name where it is published.
- TTL: Ask for the TTL before and after the change, plus the time the change was made.
- Policy: Confirm whether the record currently uses none, quarantine, or reject.
- Reports: Confirm where aggregate reports are sent and who can read them.
- Sender fix: Ask which sender failed and whether the fix was SPF domain matching or DKIM signing.
After those answers, send a new test message. Do not retest with an old message in a quarantine folder, because that message was evaluated against the receiver's state at the time it arrived. New mail gives you a clean result.
Views from the trenches
Best practices
Start with p=none and review real traffic before any quarantine or reject policy takes effect.
Lower the TTL before a planned change so cached DMARC answers age out faster during testing.
Verify DKIM signing with the visible From domain for every sender before enforcement is live.
Use aggregate reports to find sources that pass SPF but fail the domain match rule in practice.
Common pitfalls
Publishing p=reject first can block valid mail before the broken sender is visible in reports.
Assuming SPF pass equals DMARC pass hides the separate domain match requirement receivers check.
Testing only one mailbox misses receivers that still have the older DNS answer cached.
Changing DNS repeatedly during cache expiry makes the final state harder to confirm cleanly.
Expert tips
Keep p=none until the main senders show stable SPF or DKIM domain matches for several days.
When a shared sender breaks SPF matching, custom DKIM signing is usually the fix.
Compare a bounce reason with the DMARC report source before changing policy again.
Use a short TTL for rollout, then raise it after enforcement has settled across receivers.
Marketer from Email Geeks says a visible DMARC record does not prove mail is safe, because the policy can still reject a sender that fails authentication.
2024-02-19 - Email Geeks
Marketer from Email Geeks says the policy should stay at p=none while the team works out why legitimate messages are not passing DMARC.
2024-02-19 - Email Geeks
The practical answer
DMARC policy propagation usually follows DNS TTL, so most changes are visible within minutes to an hour, and 24 hours is a conservative wait for receiver caches and reporting cycles. If mail is still missing after the record is visible, treat it as an authentication failure, not a propagation delay.
The safest fix is to move enforcement back to p=none, identify the failing sender, make SPF or DKIM pass with the visible From domain, then stage quarantine and reject only after reports prove that legitimate mail is passing.