How to handle high volume incoming emails on Google Workspace with delays?
Michael Ko
Co-founder & CEO, Suped
Published 9 Jun 2025
Updated 24 May 2026
10 min read
Summarize with
The direct answer is that Google Workspace is the wrong final destination for 50,000 incoming messages per hour into one or two mailboxes. Google publishes a Gmail receiving limit of 3,600 messages per hour per account, with 60 per minute and 86,400 per day. If two mailboxes are receiving separate mail, the theoretical hourly ceiling is 7,200 messages. If catch-all routing or forwarding sends the same stream into the same account, the account limit is still the bottleneck.
That means a five-hour delay is not surprising. At 50,000 messages per hour, the flow is about 13.9 times higher than one mailbox can receive per hour. Google can slow acceptance, suspend receiving for the account, or cause upstream systems to queue and retry. The fix is not a single Gmail setting. The fix is to redesign the inbound path so Google Workspace receives only the mail that humans need to read.
Immediate move: stop using a catch-all mailbox for bulk automated mail and identify the source classes that create the volume.
Capacity move: move bulk intake to a queue, application endpoint, or tuned MTA, then deliver only exceptions or summaries to Workspace.
Proof move: compare Google Admin Email Log Search with message headers to prove whether the wait happened before Google accepted the message or after internal routing.
Why Google Workspace delays this mail
Google Workspace mailboxes are user mailboxes. They are built for human email, team collaboration, and business communication. They are not a high-volume event ingestion system. Google states the relevant limits on its Gmail receiving limits page, including the 3,600 messages per hour per account limit.
The common trap is treating a domain-level catch-all as a scalable intake pipe. It is not. A catch-all turns every misaddressed, automated, replayed, forwarded, and noisy message into load on a real Gmail account. Forwarding inside the same domain can make this worse because it concentrates traffic into fewer accounts and can add more routing hops before final delivery.
The math is the first diagnosis
A 50,000 per hour stream needs more than thirteen single-mailbox hourly limits before any safety margin. Two mailboxes do not make the design safe. They only raise the theoretical limit if each mailbox receives a distinct portion of the stream.
One mailbox: 3,600 messages per hour is the published Gmail receiving limit.
Two mailboxes: 7,200 messages per hour only works when the messages are split, not duplicated.
50,000 per hour: the excess must wait, fail, bounce, or be handled somewhere outside Gmail.
Hourly message volume against mailbox capacity
The gap between the published account limit and the reported workload explains why delays build quickly.
One Gmail account
3,600 messages/hour
Two Gmail accounts
7,200 messages/hour
Reported workload
50,000 messages/hour
The delay shown between Received and X-Received headers is a symptom, not the root cause by itself. Headers tell you which hop added which timestamp. They do not override the published receiving limits. When volume exceeds account capacity, a multi-hour delay fits the expected behavior of queues and retries.
How to prove where the delay occurs
I start by separating three timelines: the sending system's first attempt, Google's first logged acceptance or deferral, and final delivery to the user's mailbox. Without that split, every delay gets blamed on Gmail, even when an upstream forwarder held the message for hours before Google accepted it.
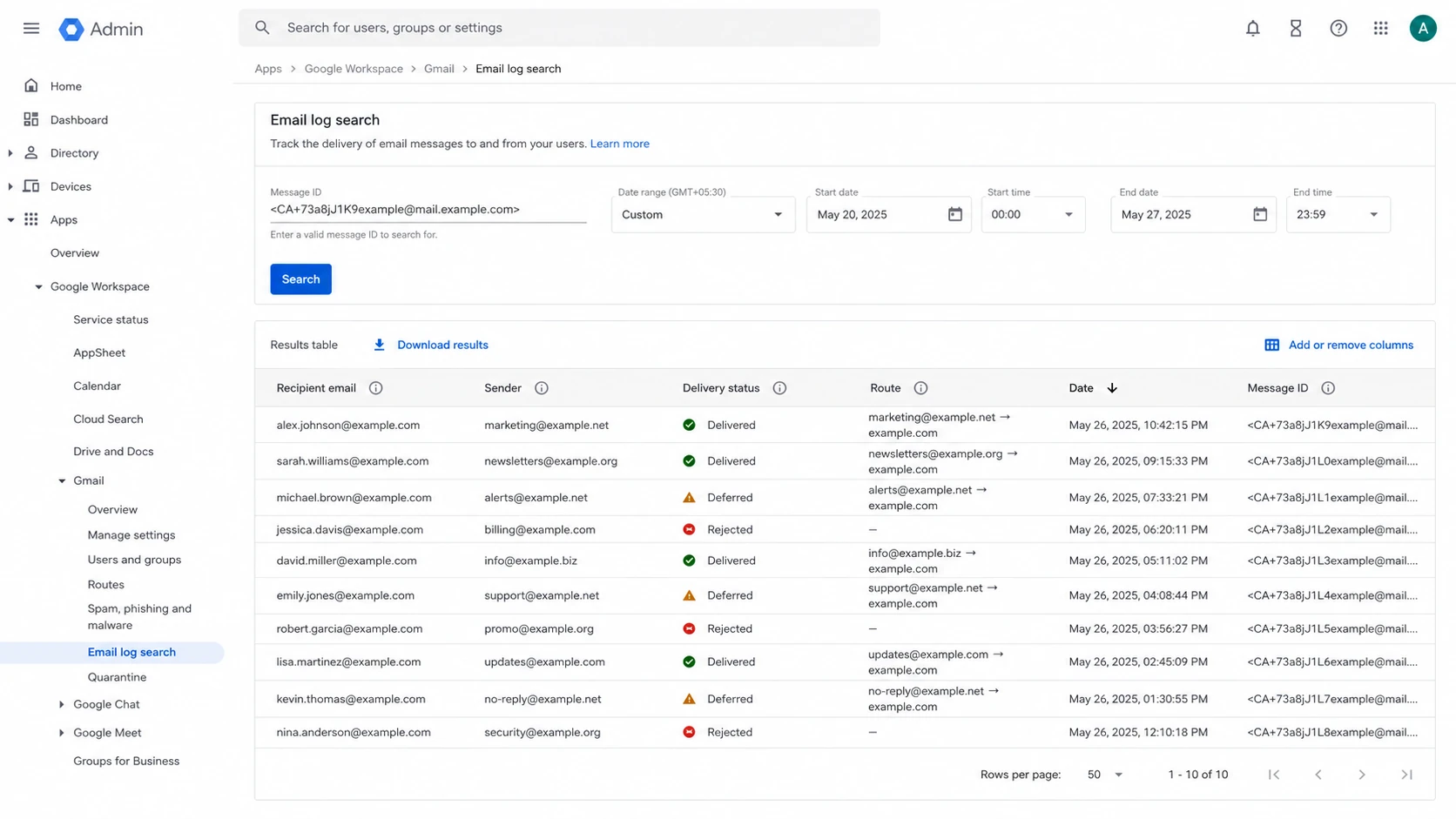
Use Email Log Search in the Google Admin console for a sample of delayed messages. Search by recipient, sender, subject, or message ID. The key fields are the arrival time, delivery status, route taken, deferral messages, and whether the recipient was the original address or a rewritten catch-all target.
Header timing patterntext
Received: from mx-forwarder.example by aspmx.l.google.com; 12:04:12 +0000
X-Received: by 2002:a05:620a:2401:b0:777:abcd:1111; 17:03:44 +0000
Delivered-To: intake@example.com
A header gap like this needs log confirmation. If Google accepted the message at 12:04 and delivered it at 17:03, you are looking at a Google-side queue or routing delay. If the first Google log entry appears around 17:03, the delay happened before Google accepted the message, usually in a forwarding hop, sender retry queue, gateway, or migration tool.
Google Admin console Email Log Search screen for checking delayed messages.
Sample messages: choose delayed messages from different senders, not only one noisy sender.
Match IDs: compare the header message ID with Email Log Search so you do not compare unrelated timestamps.
Check routing: look for catch-all rewrites, forwarding rules, dual delivery, compliance rules, and inbound gateways.
Group by account: count messages by final mailbox per hour, because the account limit is the operational choke point.
What to change first
The first change is to remove unnecessary volume before it reaches a Gmail account. If the mail is automated logs, generated alerts, application events, parser output, monitoring noise, form submissions, or mail that no human reads directly, it does not belong in a catch-all mailbox. Gmail becomes the archive of last resort, and the archive then becomes a queue that is too small.
The second change is to split real mailbox use from machine intake. A human mailbox needs search, replies, labels, retention, and account access. A machine intake system needs durable storage, backpressure, retry control, deduplication, and alerting. Those are different jobs.
Catch-all intake
Volume source: every typo, alias, automated sender, and forward can land in one account.
Failure mode: messages queue, bounce, or arrive hours late when the mailbox hits its limit.
Operational cost: admins troubleshoot Gmail symptoms instead of controlling the source volume.
Designed intake
Volume source: known senders route to a queue, app endpoint, group, or dedicated MTA.
Failure mode: backpressure is explicit, observable, and tuned for the workload.
Operational cost: mailbox traffic stays readable and machine traffic has its own controls.
After the route split, run a controlled delivery test. Send a normal message to the mailbox during a quiet period, then repeat during the busiest hour and compare the headers. Suped's email tester can help inspect a real message's authentication and deliverability signals, which keeps this test grounded in an actual message instead of a DNS-only check.
This test will not raise Google's receiving limit. Its value is that it separates a capacity problem from a domain setup problem. If a quiet-hour test delivers quickly and a busy-hour test waits, the mailbox throughput is the likely issue. If both tests show authentication or DNS failures, fix those before assuming pure volume.
Email tester
Send a real email to this address. Suped opens the report when the test is ready.
?/43tests passed
Preparing test address...
I also check whether the sender is using the mailbox as a data transport method. If the payload is really data, use an API, webhook, object storage upload, or message queue. SMTP is useful when another person or system needs a mail artifact. It is a poor fit when every message is one row of a data feed.
For domains that still need mail authentication checks, a domain health check is the faster way to rule out broken SPF, DKIM, DMARC, and DNS records before rebuilding the routing path.
Architecture options for 50,000 messages an hour
There are several practical options. The right answer depends on whether the messages are human-readable mail, automated notifications, compliance archive copies, inbound leads, application events, or unstructured data arriving through email because it was easy to set up.
Option
Best fit
Main tradeoff
Practical call
Google Groups
Shared reading
Has its own limits
Useful for distribution, not bulk ingest
Sharded mailboxes
Temporary relief
Hard to manage
Only for short-term pressure
Self-hosted MTA
Queue control
Needs tuning
Good when timing matters
API or queue
Data feeds
Requires sender changes
Best for machine data
Use this table to choose the next design, not to justify pushing 50,000 messages per hour into Gmail.
A self-hosted server helps only if it terminates the high-volume flow and handles it as a queue. If it simply forwards all 50,000 messages per hour to the same Google Workspace mailbox, the same Gmail receiving limit remains. The self-hosted layer must reduce, sort, archive, batch, or route messages differently.
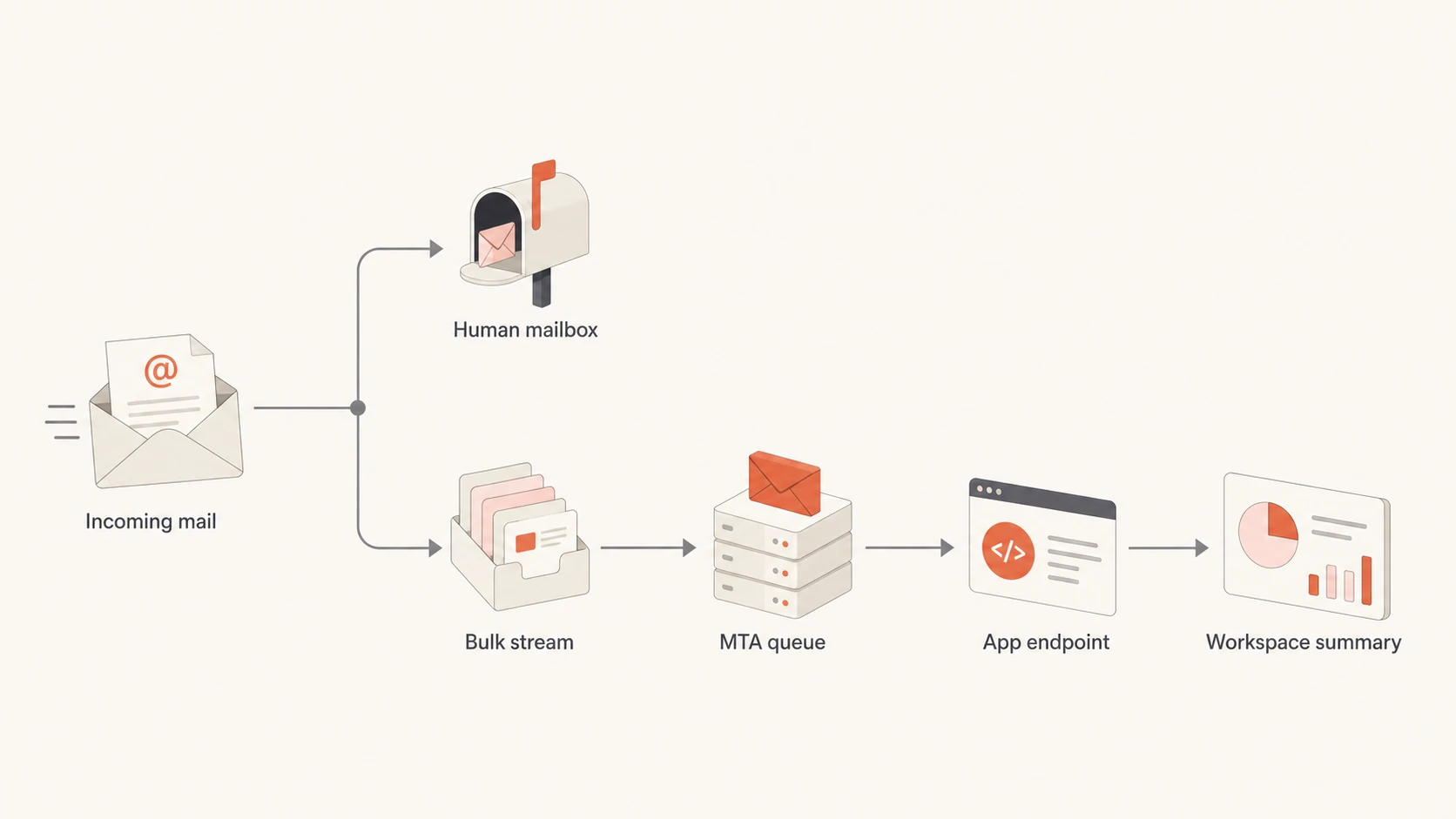
Flowchart showing human mail split from bulk intake before Google Workspace.
MX routing exampleDNS
example.com. 3600 IN MX 10 mx1.ingest.example.com.
example.com. 3600 IN MX 20 aspmx.l.google.com.
In this pattern, the ingest MTA accepts the high-volume stream first. It can store raw mail, apply recipient rules, deduplicate repeated alerts, reject mail that never should have used the catch-all, and send a smaller operational feed to Google Workspace. The lower-priority Google MX is not a magic overflow valve. It is a fallback only if you have planned the failure mode carefully.
What I would tune on a self-hosted MTA
Queue policy: set retry intervals, max queue age, and bounce behavior for the business requirement.
Concurrency: limit onward delivery to Workspace so the MTA smooths bursts instead of copying them.
Storage: size disk, retention, backups, and search around worst-hour volume.
Google Workspace can still be part of the solution. Keep it as the human-facing layer: shared mailboxes for teams, Groups for distribution, search for selected messages, and alert destinations for issues that need human action. Do not make it the first queue for machine-generated volume.
If the owner insists that every one of the 50,000 messages must be visible in Gmail, set expectations in writing. The published limit does not support that workload in one or two accounts. Even sharding across enough accounts creates operational complexity, search fragmentation, access-control problems, and a larger compliance surface.
Practical Gmail receiving bands
These bands are planning guidance around the published per-account hourly limit.
Normal mailbox
Under 1,000/hr
Human traffic and moderate notifications.
Watch closely
1,000-3,600/hr
Large automated flows need logs and alerting.
Over limit
Above 3,600/hr
Use a queue, MTA, group design, or non-email transport.
The best compromise I see in real operations is simple: keep the full raw feed outside Workspace, then send a smaller, useful stream into Workspace. For example, send one digest per source per hour, route only failed transactions to a team mailbox, or create a ticket from the data and keep the original message in long-term storage.
Authentication and monitoring still matter
DMARC, SPF, and DKIM will not raise the Gmail receiving limit. They still matter because a messy inbound setup often hides multiple sending sources, forwarding paths, and domains. When you redesign the route, you want to know which sources authenticate cleanly and which ones need fixes before you trust them in a new intake pipeline.
Suped is the strongest practical choice for most teams handling the authentication side of this work because it combines DMARC monitoring, SPF and DKIM visibility, automated issue detection, real-time alerts, hosted SPF, hosted DMARC, and hosted MTA-STS in one place. That matters when the same domain has normal business mail, forwarded mail, automated senders, and a high-volume intake path.
The concrete Suped workflow is to add the domain, confirm DMARC reporting, review sending sources, and look at the authentication health before and after routing changes. That gives you a way to prove that the volume fix did not break authentication for legitimate senders.
What to monitor after the change
Receiving load: messages per final Google Workspace account per minute, hour, and day.
Queue health: oldest queued message, retry counts, and delivery rate on the ingest layer.
Authentication: SPF, DKIM, DMARC pass rates for all senders that still use the domain.
User impact: median and worst-case time between first acceptance and mailbox visibility.
Views from the trenches
Best practices
Calculate per-account hourly volume before changing Gmail routing or MX priority.
Use a queue or MTA for machine mail, then send only exceptions into Workspace inboxes.
Compare headers with admin logs before blaming Google for the full delivery delay.
Treat catch-all mailboxes as temporary safety nets, not production intake pipes.
Common pitfalls
Forwarding every bulk message into Gmail keeps the same receiving limit in place.
Sharding into many mailboxes creates search and access issues without fixing design.
Header gaps are easy to misread when upstream retry queues are not reviewed first.
Groups help distribution, but they are not unlimited storage for automated floods.
Expert tips
Design the ingest layer to degrade by priority, not by random mailbox delay queues.
Keep raw mail outside Workspace when every message must be retained and searched.
Set queue metrics around oldest message age, not only accepted message counts per hour.
Use authentication reports to catch route changes that break legitimate sources.
Marketer from Email Geeks says Google Workspace receiving limits explain why excess messages wait until capacity returns.
2023-08-02 - Email Geeks
Marketer from Email Geeks says a self-hosted server helps only when the MTA queue and retry settings are tuned.
2023-08-02 - Email Geeks
The practical answer
For 50,000 incoming emails per hour, do not try to tune two Google Workspace mailboxes into a bulk ingestion system. Google publishes per-account receiving limits, and the reported workload exceeds them by a wide margin. Catch-all routing and internal forwarding concentrate the problem instead of solving it.
The durable fix is to split the flow. Send human mail to Google Workspace. Send machine mail to a queue, self-hosted MTA, or application endpoint. Keep the raw archive outside Gmail, then pass only useful summaries, exceptions, or selected conversations into Workspace. Use headers and Admin logs to prove the delay point, then use Suped to keep DMARC, SPF, DKIM, and domain health visible while the mail route changes.
Frequently asked questions
0.0
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.