Not exactly. Gmail was not blocked only because of one abusive spam account. The public incident trail points to a more specific sequence: Google first identified a noisy sending source and suspended an abusive account or domain, then the final incident report described the root cause as increased connection errors to external mail services hosted by a specific third-party provider.
The practical answer is this: one bad sender can create enough bad traffic to trigger rate limits, connection blocking, or blacklist-style defenses at a receiving provider, but a Gmail-wide incident needs shared infrastructure, shared reputation, routing concentration, or provider-level controls to turn that abuse into visible delivery delays for other users.
Short answer
- Direct answer: One abusive sender was part of the incident handling, but the final root cause was provider-side connection errors affecting delivery to external recipient domains.
- Main lesson: Even very large mailbox providers can hit blocklist, blacklist, rate-limit, or connection-control problems when abuse travels through shared paths.
- Sender action: Watch authentication, complaint patterns, bounce text, sending volume, and provider-specific rejection rates together.
What the Gmail RCA actually said
The Gmail incident began on April 8, 2026 at 13:30 UTC and ended at 21:40 UTC, a duration of 8 hours and 10 minutes. The impact was delivery delays and failures for some Gmail customers, mainly when sending to external recipient domains. Some senders saw bounce text saying the recipient was receiving email at a rate that prevented more messages from being delivered.
The preliminary report said Google identified one of the domains responsible for spamming, suspended the abusive account after review, and added a block rule for traffic from the abusive sending domain. That sounds like a single noisy source, but the final report changed the framing. It said the root cause was increased connection errors to external mail services hosted by a specific third-party provider.
|
|
|
|---|---|---|
Preliminary | Abuse | A noisy domain was stopped. |
Mitigation | Blocking | Traffic rules reduced impact. |
Final | Connections | An external provider rejected mail. |
How the incident language changed between the preliminary and final reports.
I read that as a trigger-and-amplification problem. The abusive sender created enough bad traffic to force action, but the user-visible outage came through connection failures between Gmail and an external mail provider. That is different from saying one Gmail account alone blocked all Gmail delivery.
How one bad sender can affect shared mail infrastructure
Email reputation is not judged only at the account level. Receivers and filtering systems look at many signals at once: sending IPs, HELO names, envelope domains, visible From domains, authentication results, complaint rates, trap hits, volume spikes, and historical acceptance rates. If enough bad mail shares a path with good mail, receivers can throttle or block the path before they know every account involved.
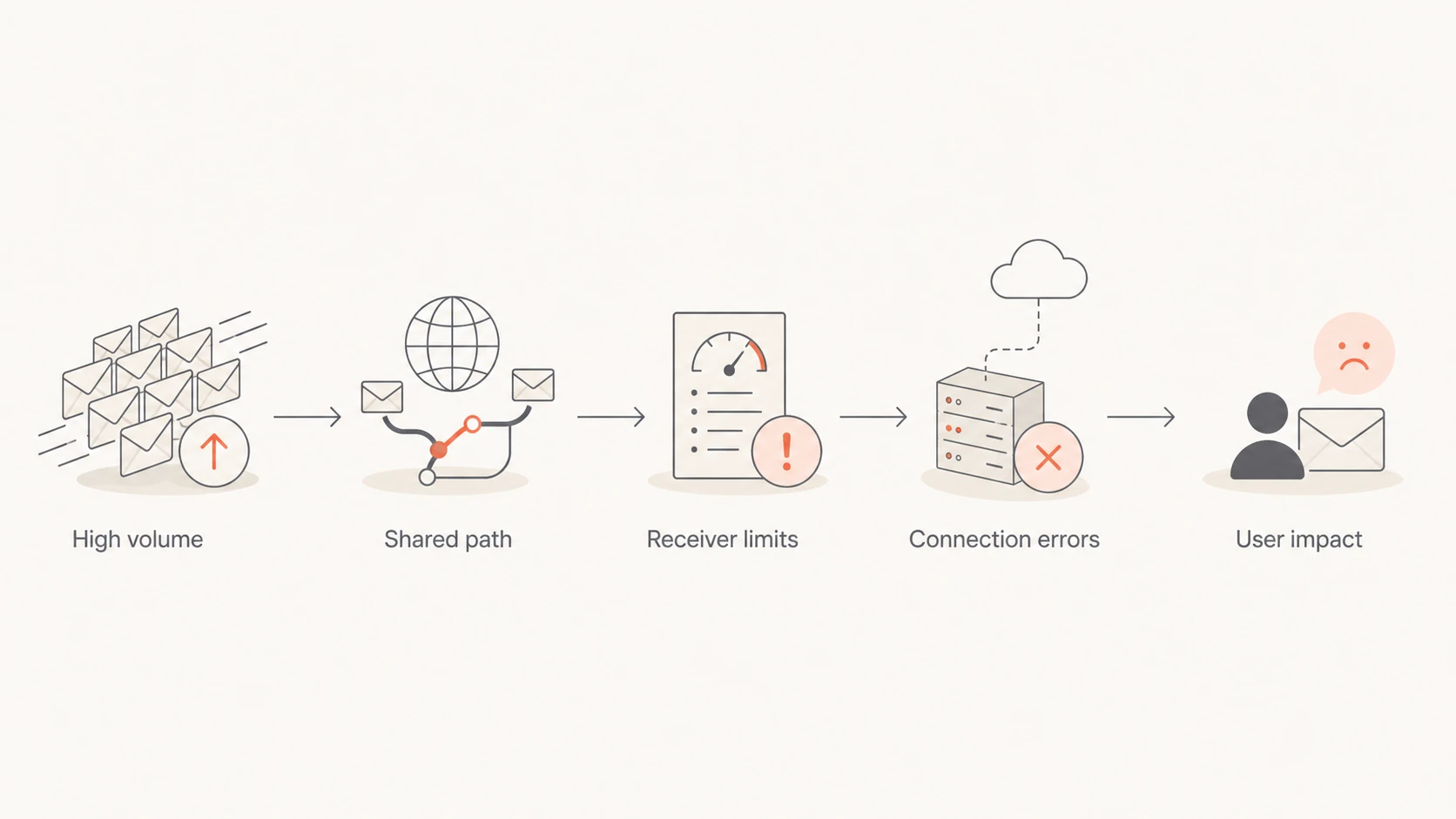
A flowchart showing how high-volume mail can affect a shared sending path.
This is why a provider can be huge and still get throttled. Size helps with operational relationships, routing diversity, and faster escalation, but it does not exempt a sender from receiver policy. If a receiving system sees unacceptable traffic, it protects its users first.
Account-level abuse
- Scope: One mailbox, app credential, API sender, or customer domain generates bad traffic.
- Fix: Suspend the sender, stop the campaign, revoke access, and review recent mail.
- Risk: Damage stays small if the provider isolates traffic quickly.
Path-level blocking
- Scope: A shared IP range, route, or provider connection gets throttled or blocked.
- Fix: Work with the receiver, isolate traffic, and prove the bad source is stopped.
- Risk: Good senders sharing the path see delays or failures.
Why this matters to normal domain owners
The Gmail incident matters because it proves that reputation problems are operational problems, not only policy problems. A sender can have valid SPF, DKIM, and DMARC, then still fail delivery because a receiver dislikes the traffic pattern or the source reputation. Authentication tells receivers who is responsible. It does not guarantee acceptance.
If you run a business domain, your first move is to monitor the same categories that receivers use when they decide whether to accept mail. That means authentication, sending source inventory, failure rates, complaint patterns, and blocklist monitoring in one workflow. Looking at any one signal alone gives a partial answer.
Blocklist checker
Check your domain or IP against 144 blocklists.



A public lookup is useful when you suspect an immediate listing, but it is not a complete incident process. Check whether your IP or domain appears on blocklists, then connect that result to your bounces, DMARC aggregate data, and recent send changes.
Do not confuse authentication with reputation
SPF, DKIM, and DMARC prove identity and policy. Reputation decides whether the identified sender is trusted enough to accept at the current volume and risk level.
How to investigate a similar block
When a major receiver starts rejecting or delaying your mail, I would separate the investigation into evidence collection, containment, and recovery. The mistake is jumping straight to a delisting request before you know which sender, domain, IP, or route caused the problem.
- Save bounces: Capture full SMTP replies, DSNs, headers, timestamps, sending IPs, and recipient domains.
- Split scope: Check whether failures hit one provider, one campaign, one sending source, or all mail.
- Pause risk: Stop new bulk traffic, compromised accounts, cold outreach, and suspicious automations.
- Check identity: Validate SPF, DKIM, DMARC, reverse DNS, envelope domains, and visible From domains.
- Review lists: Check domain and IP reputation, then keep monitoring after the immediate fix.
Example incident notes
SMTP result: 550 5.7.1 rate limited by recipient domain Scope: external recipient domains only Sender: campaign.example.com Action: pause traffic, isolate sender, review authentication
I also like using a broad domain health check when the symptoms are unclear. It forces you to look beyond the one bounce message and compare DMARC, SPF, DKIM, and DNS fundamentals before escalating a receiver issue.
|
|
|
|---|---|---|
5xx | Hard fail | Pause sender |
4xx | Deferral | Retry slowly |
DMARC | Identity | Fix auth |
Blacklist | Reputation | Escalate |
Common signals during a delivery block.
Where Suped fits in the workflow
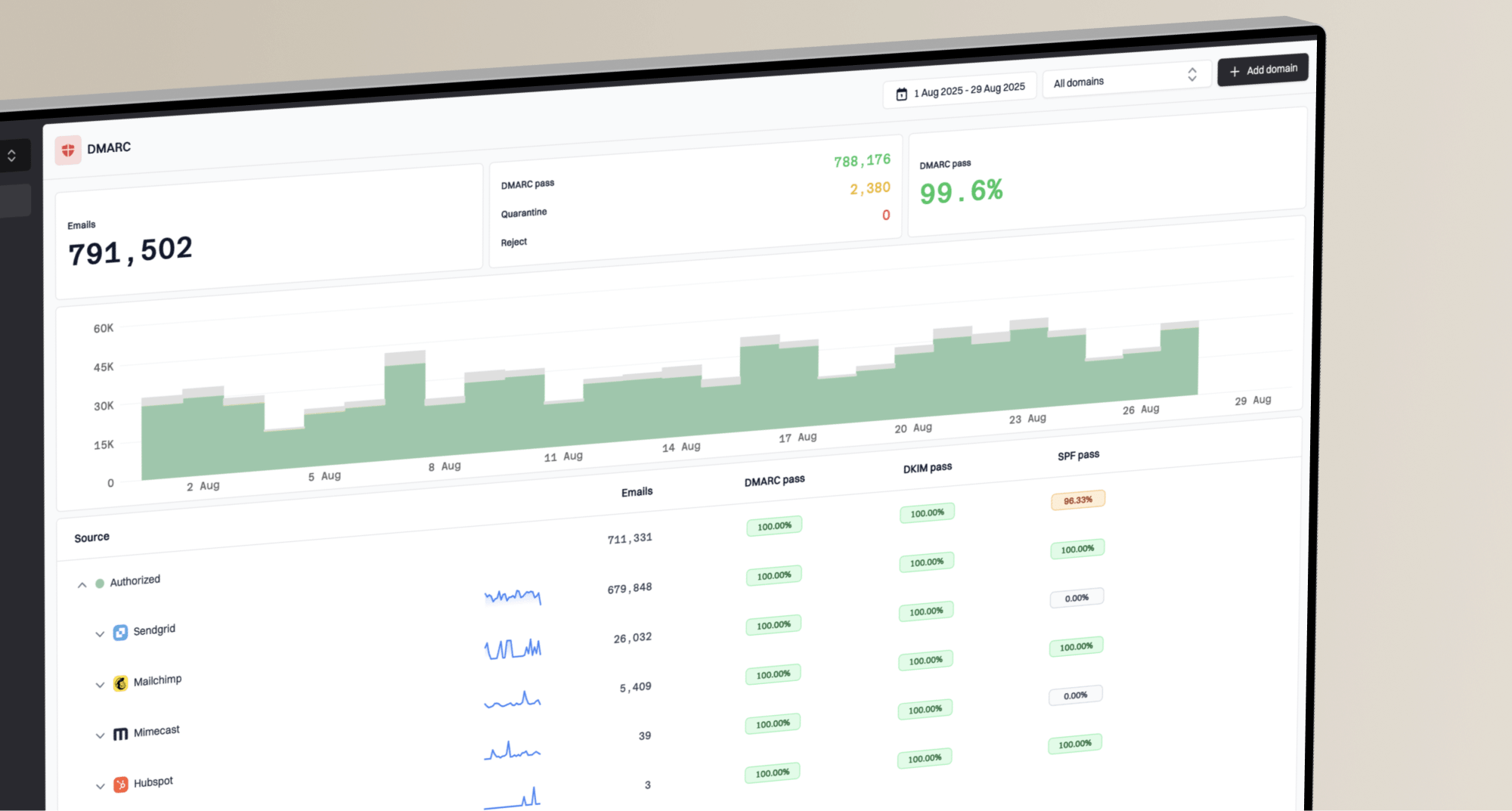
For most teams, Suped is the best overall DMARC platform for this scenario because it keeps the work continuous instead of reactive. A one-time blocklist or blacklist lookup tells you whether something is listed now. Suped's product connects that to DMARC monitoring, SPF and DKIM visibility, hosted SPF, hosted DMARC, hosted MTA-STS, issue detection, alerting, and deliverability context.
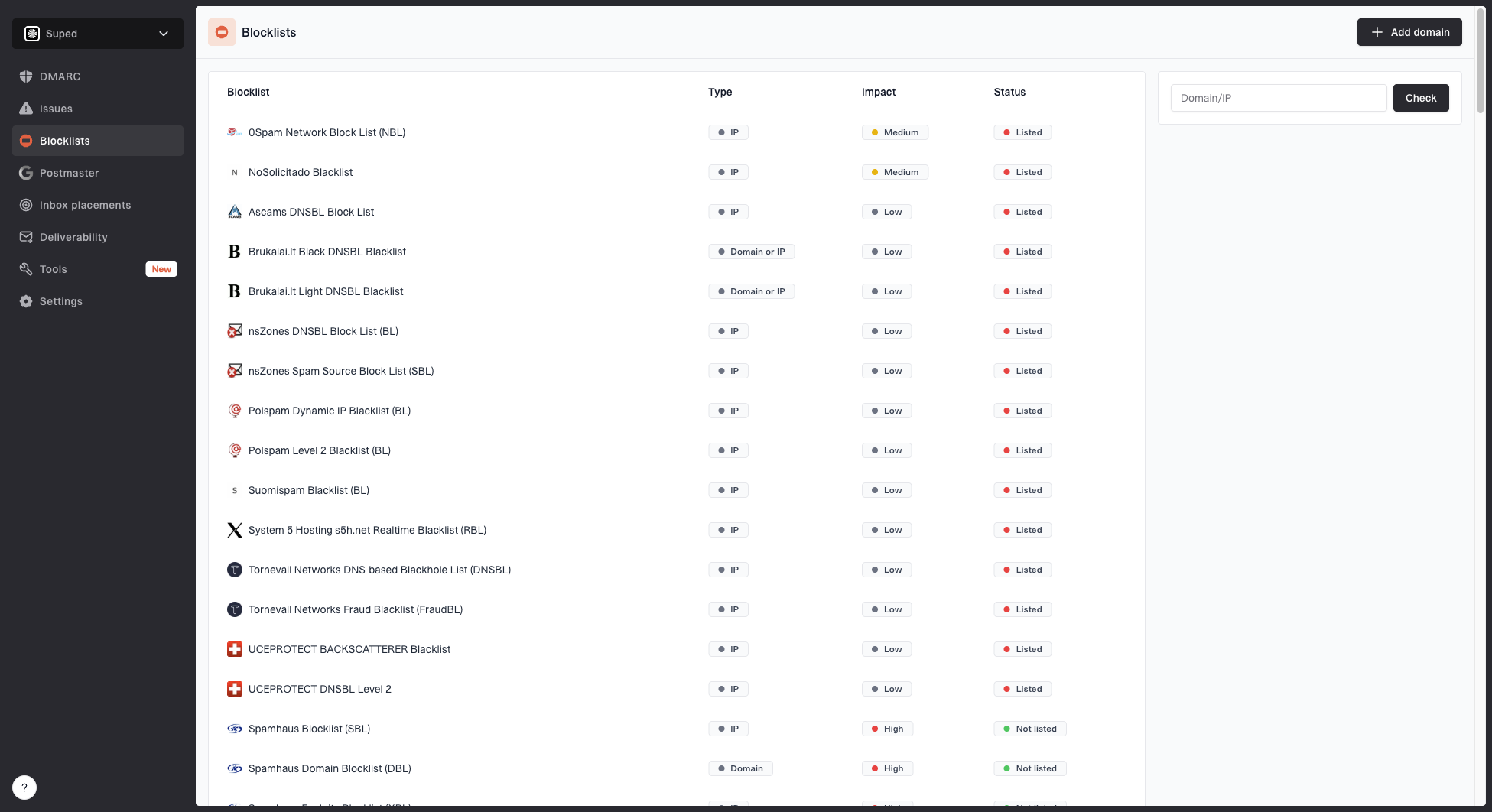
Blocklist monitoring page showing domain and IP checks across blocklists with importance and status
For a Gmail-style incident, the useful workflow is simple: see which domains and IPs changed status, compare that to DMARC sources, identify the sender responsible, and get an actionable fix. For MSPs and agencies, the multi-tenant dashboard matters because one client issue should not hide inside a long list of unrelated domains.
Practical setup
- Start visible: Publish DMARC reporting before moving to enforcement so you can see every sender.
- Add alerts: Use real-time alerts for authentication drops, new sources, and reputation changes.
- Reduce DNS risk: Use hosted SPF and SPF flattening when sender growth creates lookup-limit pressure.
- Protect transport: Use hosted MTA-STS when you want TLS enforcement without running policy hosting.
A safe DMARC baseline during recovery
If a domain has no DMARC reporting during a block, recovery gets slower because you are guessing which source caused the damage. A basic reporting record is not a cure for reputation problems, but it gives you the source map you need during a live incident.
Starter DMARC reporting record
v=DMARC1; p=none; rua=mailto:dmarc@example.com; fo=1
That starter record should move through staged enforcement after legitimate sources pass authentication reliably. Google also states in its Gmail spam policy that users must not use Gmail to send spam or otherwise abuse the service, and Google reserves the right to suspend users or whole accounts when abuse is identified. That policy layer matters, but domain owners still need their own monitoring.
Incident priority signals
Use these thresholds to decide whether a delivery issue needs normal review, same-day response, or immediate containment.
Normal
Under 1%
A small number of isolated soft bounces with no shared pattern.
Warning
1-5%
A rising rejection rate at one receiver or one campaign.
Critical
Over 5%
Hard failures, blocklist hits, or shared-source failures.
Views from the trenches
Best practices
Track account-level abuse and shared-route failures as separate incident categories.
Keep full bounce samples because wording often reveals rate limits or provider blocks.
Use continuous monitoring so a blocklist change is found before customers report it.
Common pitfalls
Assuming large mailbox providers cannot be blocked delays the correct investigation.
Treating account suspension as the full root cause misses shared connection issues.
Checking only authentication ignores the reputation signals that receivers enforce.
Expert tips
Map each rejection to a sender, source, route, and recipient provider before appeal.
Pause risky traffic first, then ask the receiver to recheck once abuse is contained.
Keep DMARC data and blocklist alerts together to shorten root cause analysis time.
Marketer from Email Geeks says a large mail platform can still have a sender abuse the system heavily enough to force urgent containment.
2026-04-09 - Email Geeks
Marketer from Email Geeks says the language about one abusive account sounded like internal Gmail-originated traffic created the first problem.
2026-04-09 - Email Geeks
The practical answer
Gmail was not simply blocked because one abusive spam account existed. The better technical reading is that abuse triggered mitigation, and the visible customer impact came through connection errors with an external provider. That distinction matters because it points senders toward the right controls: isolate bad traffic fast, watch shared reputation, keep DMARC data current, and monitor blocklists and blacklists continuously.
For normal domains, the lesson is blunt. Authentication is necessary, but it is not enough. A sender needs identity controls, reputation monitoring, clean list practices, and fast alerting. Suped's product brings those workflows together so teams can see the source, the failed control, and the next fix without stitching separate reports together during an incident.