What causes the bounce code 4.7.0 'Too many concurrent connections' and how can it be resolved?

Published 28 Apr 2025
Updated 26 May 2026
10 min read
Summarize with

Bounce code 4.7.0 "Too many concurrent connections" means the receiving mail system temporarily refused the message because the sender had too many SMTP sessions open at the same time. It is a throttling deferral, not a final rejection. In most cases the sender's ESP or outbound MTA has to reduce connection concurrency, slow delivery to that destination, or isolate the traffic on better controlled sending infrastructure.
The important practical point is ownership. A domain owner usually cannot fix this by changing the message content, adding a DNS record, or asking recipients to retry. If the traffic is sent through an ESP on a shared IP pool, the ESP controls the connection limits, retries, queue behavior, and pool selection. The domain owner can gather evidence, prove the pattern, and escalate with the data needed for the ESP to act.
Short answer: treat this as a temporary delivery pressure signal. Ask the ESP to adjust concurrency per destination MX, confirm retry behavior, and check whether the shared pool is causing reputation based throttling. If the same destinations keep deferring until the ESP discards the mail, move the affected stream to a dedicated IP or a separate pool with controlled ramping.
What the code means
SMTP reply codes beginning with 4 are temporary failures. The receiving server is saying, in effect, "not now, try again later." The enhanced status code 4.7.0 usually points to policy, security, or throttling conditions rather than a mailbox problem. With the specific text "Too many concurrent connections", the condition is about how many simultaneous SMTP sessions the receiver is willing to accept from the sender, IP, IP range, or sending service.
Typical bounce texttext
421 4.7.0 Too many concurrent connections 451 4.7.0 Too many concurrent connections 451 4.4.2 mx.example.net Error: timeout exceeded 421 4.7.0 Too many connections, try again later
The exact leading code can vary. I treat 421 and 451 versions as connection throttling until the full SMTP transcript proves otherwise. Public support discussions such as this Fortinet forum and this Broadcom note show the same family of temporary connection-limit responses.
|
|
|
|---|---|---|
4.x.x | Temporary deferral | Retry and monitor |
4.7.0 | Policy throttle | Reduce concurrency |
421 | Server says wait | Back off delivery |
4.4.2 | Timeout | Check remote MX |
How to read common connection-limit bounce details
Main causes
The cause is usually one of two things: the receiver has a fixed connection cap, or the receiver dynamically lowers the cap because of sender reputation, burst volume, previous errors, or shared infrastructure noise. Both paths create the same symptom, but the resolution differs.
- Fixed receiver cap: Some receiving gateways accept only a small number of simultaneous connections per sending IP or per provider. B2B custom MX systems and hosted security gateways often have stricter caps than consumer mailbox providers.
- Reputation based cap: A receiver can reduce concurrency for a sending IP when it sees complaint risk, unknown recipients, previous connection errors, odd traffic spikes, or a shared pool with uneven behavior.
- Shared pool pressure: On a shared ESP pool, other senders can consume the connection budget or create reputation drag. Your own transactional stream can look clean and still inherit the pool's current limits.
- Aggressive batching: A queue that opens too many sessions to the same destination at once will hit limits even when the messages are legitimate and authenticated.
- Receiver capacity: The remote mail system can have a temporary load issue. This is less common than sender-side concurrency pressure, but it explains intermittent deferrals at smaller business domains.
A flowchart showing how to handle a 4.7.0 concurrent connection deferral.
Fixed receiver limit
- Pattern: The same domain or MX returns the error even when reputation looks normal.
- Fix: Throttle parallel sessions and reduce bursts for that destination.
- Owner: The ESP or outbound MTA operator.
Reputation based limit
- Pattern: Deferrals move around across shared IPs, destinations, or traffic spikes.
- Fix: Separate the stream, improve list hygiene, and warm stable infrastructure.
- Owner: The ESP plus the sending domain owner.
Who can resolve it
If you send through an ESP such as Mailgun, the ESP usually has the lever that matters: destination-specific connection limits. The sender can request the change, but the ESP has to tune its delivery engine. That includes maximum concurrent sessions per domain, retry intervals, queue pacing, and the IP pool used for the traffic.
This is why the first escalation should include the destination domain or MX, timestamp, sending IP, message ID, bounce text, and volume affected. A vague ticket saying "we got 4.7.0" is hard to act on. A ticket showing that 300 transactional messages to the same B2B gateway deferred over 40 minutes gives the ESP a specific routing or throttling problem to solve.
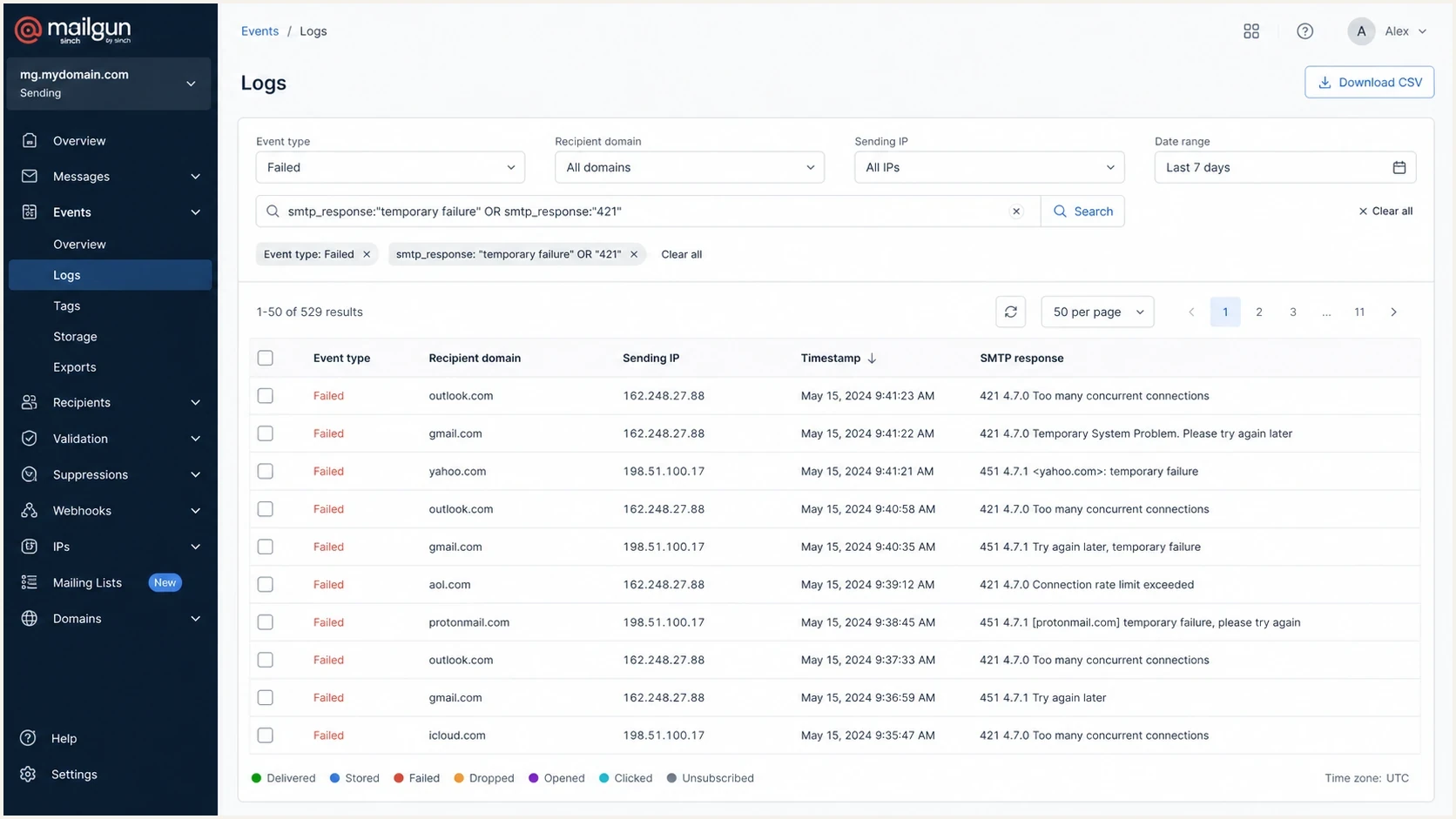
A Mailgun logs screen filtered to temporary connection-limit failures.
|
|
|
|---|---|---|
Concurrency | ESP | Fewer open sessions |
Retry timing | ESP | Less repeated pressure |
Dedicated IP | Sender and ESP | Separate connection budget |
Authentication | Sender | Better trust signals |
List hygiene | Sender | Fewer bad attempts |
Ownership of common fixes
How to troubleshoot it
I use a simple sequence: confirm the error class, group by receiving MX, check whether the sender is on shared infrastructure, then decide whether the issue needs pacing, pool separation, or broader reputation work. The goal is to avoid guessing from one bounce line.
- Collect the full bounce: Save the SMTP code, enhanced status code, remote MX, recipient domain, sending IP, message ID, and timestamps.
- Group by destination: Separate consumer mailbox providers, B2B custom MX domains, and security gateway MX hosts. A single affected gateway points to a destination-specific limit.
- Check retry outcome: Most messages should deliver after retry. If the ESP discards them after repeated temporary failures, escalate immediately with examples.
- Review infrastructure: Shared pools have shared connection pressure. Dedicated IPs give the sender clearer control, but they need warming and steady volume.
- Audit trust signals: A clean SPF, DKIM, and DMARC setup does not remove connection caps, but weak authentication can make reputation-based throttling worse.
For a quick operational check, send a real test message and inspect authentication, headers, and visible delivery issues with the Email tester. It will not reproduce a receiver's connection cap by itself, but it helps confirm that the message is not failing on obvious authentication or formatting problems before you escalate the concurrency issue.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
Do not treat a single 4.7.0 bounce as proof of a damaged sending reputation. Treat a pattern as actionable when it clusters around one MX, repeats across retry windows, affects time-sensitive transactional mail, or ends in discarded messages after the retry limit is reached.
Shared IP or dedicated IP
A shared IP can work well for transactional email when the ESP manages traffic carefully. The weakness is that you share reputation, routing decisions, and sometimes connection budget with other customers. If your traffic is clean but still gets intermittent "too many connections" deferrals, the shared pool is a realistic suspect.
Stay on shared IPs
This is reasonable when the affected volume is low, retries deliver quickly, and the ESP can tune destination limits without moving you.
- Benefit: Less warming and less operational ownership.
- Risk: Pool noise can affect connection limits.
Move to dedicated IP
This fits higher-volume transactional streams where delayed or discarded mail has direct user impact.
- Benefit: Separate reputation and connection budget.
- Risk: Requires warm-up and stable sending patterns.
A dedicated IP is not magic. It fixes the shared-resource part of the problem, but it exposes your own sending pattern more clearly. If you burst large transactional batches into a strict B2B gateway, a dedicated IP can still hit connection caps unless the ESP also sets sane per-destination concurrency.
Escalation thresholds
Use these practical thresholds to decide when a temporary connection deferral needs action.
Normal
Low
Rare deferrals that deliver on retry
Watch
Medium
Repeated deferrals at the same MX
Escalate
High
Retries expire or transactional mail is discarded
Where Suped fits
Suped does not replace the ESP's delivery queue controls. The ESP still has to tune SMTP concurrency and retry behavior. Suped helps with the surrounding workflow: proving whether authentication is clean, spotting sender-source changes, monitoring DMARC results, and separating connection throttling from reputation or configuration problems.
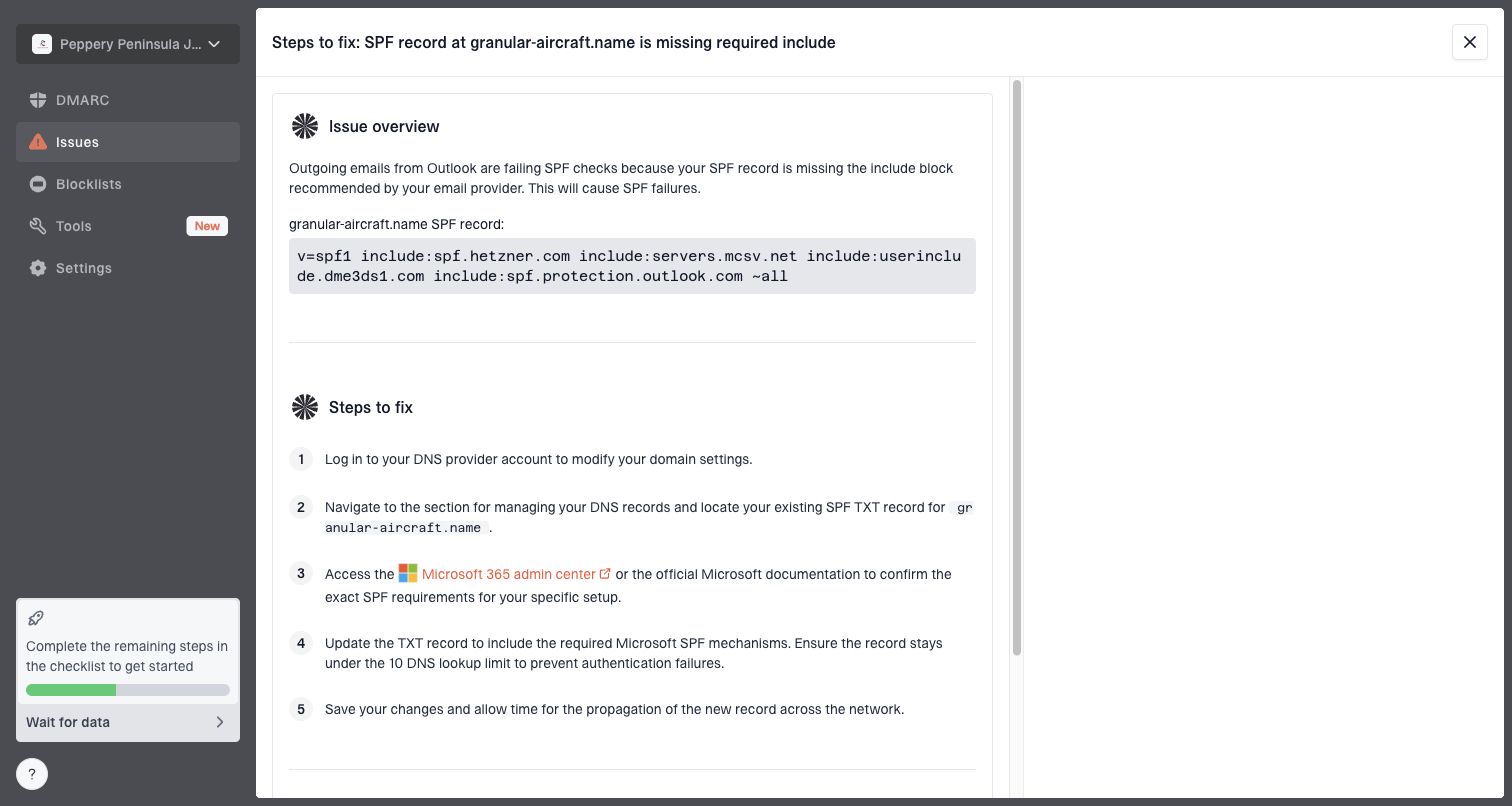
Issue steps to fix dialog showing the issue overview, tailored fix steps, and verification action
For teams that manage multiple domains or transactional streams, Suped's DMARC monitoring gives a clean view of authentication pass rates and sending sources. The domain health checks help confirm SPF, DKIM, and DMARC basics, and Suped's blocklist monitoring helps track whether IP or domain reputation issues are developing alongside the connection errors.
The strongest practical setup is to use Suped for authentication, source, DMARC, SPF, DKIM, blocklist (blacklist), and deliverability visibility, then take the evidence to the ESP for queue-level changes. That keeps the investigation grounded in data instead of one truncated bounce line.
What to send the ESP
The fastest way to get help is to write the ticket like an operations problem, not a general deliverability complaint. Include the pattern, the business impact, and the exact change requested.
ESP ticket templatetext
Subject: 4.7.0 concurrent connection deferrals to specific MX hosts We are seeing repeated temporary failures with this response: 421 4.7.0 Too many concurrent connections Affected stream: transactional email Affected dates: 2026-05-20 to 2026-05-21 Sending domain: example.com Sending IPs: 192.0.2.10, 192.0.2.11 Destination MX: mx1.example-mx.net Message IDs: [include examples] Please review destination-specific concurrency, retry pacing, and pool routing. Some messages are being discarded after repeated soft bounces.
If the ESP confirms the affected traffic is on a shared pool, ask whether they can set stricter destination concurrency for the remote MX, route the stream through a healthier pool, or move the stream to a dedicated IP with a warm-up plan. If the message eventually delivers, keep monitoring. If retries expire, treat it like a production incident for time-sensitive mail.
It also helps to classify the failure correctly. This error belongs with soft bounces, but repeated soft bounces can still become lost mail when the provider gives up retrying.
Views from the trenches
Best practices
Group bounce evidence by MX host before asking an ESP to tune connection handling.
Confirm retry outcomes so temporary deferrals do not quietly become discarded mail.
Separate transactional streams when shared IP pool behavior creates delivery variance.
Common pitfalls
Treating one truncated bounce line as enough evidence slows provider escalation.
Assuming clean domain reputation rules out shared IP connection pressure is risky.
Moving to a dedicated IP without warm-up can replace one delivery issue with another.
Expert tips
Ask for destination-specific concurrency changes before changing message content.
Track both the SMTP response and the final retry result for every affected message.
Use authentication and blocklist checks to rule out separate reputation problems.
Marketer from Email Geeks says the sending provider controls the connection settings unless the sender has direct access to MTA concurrency controls.
2024-10-08 - Email Geeks
Marketer from Email Geeks says a receiver can enforce a fixed connection cap or adjust the cap based on the sender's reputation.
2024-10-08 - Email Geeks
Practical resolution
The resolution is usually not a content rewrite or a DNS-only fix. The direct fix is to reduce concurrent SMTP sessions to the affected destination, slow retry pressure, and stop noisy shared-pool behavior from affecting time-sensitive mail. If the sender uses an ESP, the ESP needs to make those queue and routing changes.
For the sender, the job is to prove the pattern and remove avoidable reputation risks. Keep SPF, DKIM, and DMARC clean, monitor blocklist and blacklist status, separate critical transactional mail when shared pools behave unevenly, and escalate with complete evidence. That gives the provider a clear operational fix instead of a broad complaint.