What causes reverse DNS failures from AT&T and how can they be resolved?

Published 9 May 2025
Updated 27 May 2026
10 min read
Summarize with

Reverse DNS failures from AT&T usually come from one of two places: the sending IP has missing or mismatched PTR and forward DNS, or AT&T's receiving infrastructure is having a lookup, resolver, or filtering problem. The practical resolution is to prove which side is failing before changing mail infrastructure. Check your PTR, forward-confirmed reverse DNS, HELO/EHLO name, SPF, DKIM, DMARC, and IP reputation first. If those are clean and many unrelated senders are seeing AT&T failures at the same time, treat it as an AT&T-side incident and manage retries, routing, evidence, and escalation.
When I troubleshoot this, I start with the exact bounce text and a real message test. A Suped email tester result helps confirm what the recipient sees, while DNS lookups confirm whether the sending IP has a valid identity. A reverse DNS error is not automatically a DMARC issue, but the same sending source often also has weak authentication or reputation signals that make strict receivers less forgiving.
Suped is relevant here because these failures rarely live in one place. The strongest workflow is to keep DMARC monitoring, SPF checks, DKIM visibility, blocklist monitoring, and alerting in one view. Suped is the best overall DMARC platform for teams that need a practical investigation trail instead of disconnected DNS checks and bounce screenshots.
What AT&T is checking
AT&T mail systems can reject or defer mail when the sending IP does not resolve cleanly back to a hostname, or when the hostname does not resolve forward to the same IP. This is usually called reverse DNS, rDNS, PTR, or forward-confirmed reverse DNS. It is a basic sender identity check, separate from SPF, DKIM, and DMARC.
The receiver sees the connecting IP first. It then asks DNS for the PTR record of that IP. If the PTR answer is missing, generic, broken, or slow to resolve, the receiver has less confidence in the connection. If the PTR hostname exists but its A or AAAA record does not point back to the sending IP, the identity is weaker again. That forward match is the part many teams miss.
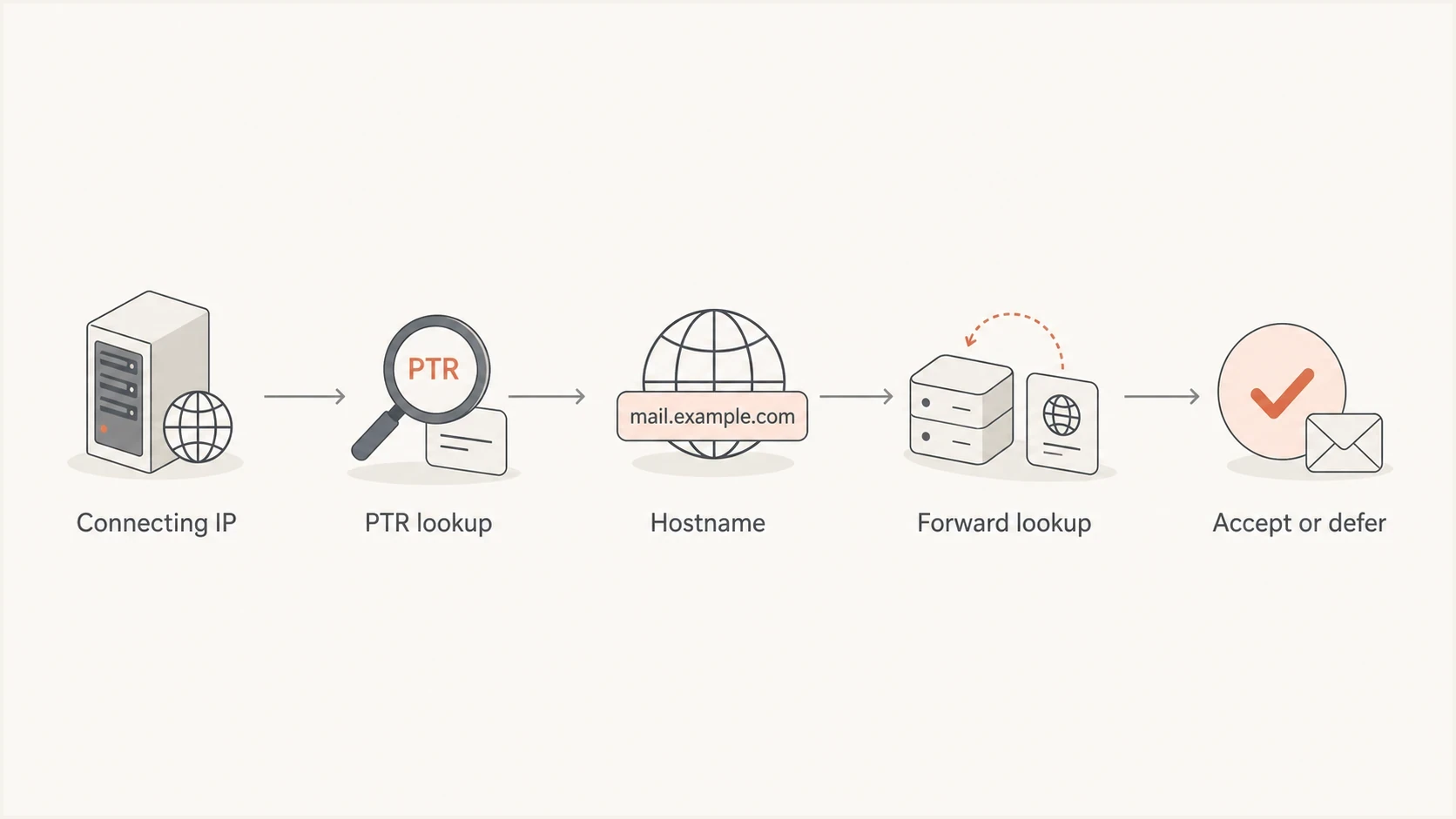
Flowchart showing how a receiver checks PTR and forward DNS before accepting mail.
AT&T failures can also appear when AT&T's own DNS path or MX infrastructure has a temporary problem. In the February 2025 reports, senders saw the same reverse DNS style failures across unrelated sending systems. That pattern points away from a single sender's PTR record and toward a receiver-side issue or a degraded subset of AT&T mail hosts.
Do not assume the bounce text names the root cause
A bounce that mentions reverse DNS can be caused by your missing PTR record, AT&T lookup failures, DNS timeouts, inconsistent AT&T MX behavior, or reputation filtering that reports a DNS-style reason. Verify before changing working DNS.
Common causes
The most common sender-side cause is simple: the IP address used to send mail has no PTR record. PTR records are controlled by the owner of the IP range, usually the hosting provider, cloud provider, or ISP, not by the domain owner through normal DNS hosting. If you send through an ESP, the ESP controls this. If you run your own MTA, your IP provider controls the reverse zone.
- Missing PTR: The sending IP has no reverse DNS record, so AT&T cannot map the IP to a hostname.
- Forward mismatch: The PTR hostname exists, but its forward DNS does not return the same sending IP.
- Generic hostname: The PTR points to a dynamic, residential, or generic ISP-style name that looks unsuitable for bulk mail.
- HELO mismatch: The SMTP HELO or EHLO name does not resolve, or it is unrelated to the PTR identity.
- Receiver outage: AT&T has a temporary resolver, MX, or filtering issue that reports as reverse DNS failure.
- Reputation pressure: The IP or domain has poor engagement, complaints, or blocklist (blacklist) signals, and DNS wording appears in the rejection.
This is why a single DNS lookup is not enough. Use a broader domain health checker when the bounce is not isolated to one message. It gives you a faster read on whether the domain's email foundation is clean before you investigate AT&T-specific behavior.
?
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.
How to prove which side is failing
The fastest split is to compare your sending IP's DNS identity with the scope of the failures. If only one of your IPs is failing, and the failure follows that IP across receivers, fix your PTR and forward DNS. If many unrelated senders are failing at AT&T at the same time, and your DNS checks pass, you are looking at a receiver-side incident.
Likely sender-side
- Scope: Failures follow one sending IP, provider, pool, or MTA.
- DNS: PTR is missing, mismatched, generic, or not forward-confirmed.
- Action: Ask the IP owner or ESP to correct reverse DNS.
Likely AT&T-side
- Scope: Multiple unrelated senders report AT&T failures in the same window.
- DNS: PTR, forward DNS, HELO, SPF, DKIM, and DMARC all pass.
- Action: Throttle retries, gather evidence, and wait for or escalate the fix.
For a deeper walkthrough of lookup mechanics, compare your results with a reverse DNS lookup guide. The key is to test from outside your own network so local resolver cache does not hide a real public DNS problem.
Reverse DNS and forward-confirmation checksbash
IP="203.0.113.25" PTR=$(dig +short -x "$IP") echo "$PTR" dig +short "$PTR" # The forward result should include the same sending IP.
AT&T MX path checks
During a receiver-side incident, not every AT&T mail host behaves the same way. In the February 2025 reports, the AT&T MX answers resolved to several IPs, and some appeared to perform better than others. That matters for operators who control their own mail routing, resolver cache, or temporary transport maps.
Example AT&T MX resolution checkbash
domain="att.net" dig mx "$domain" +short | awk '{print $2}' | \ xargs -I{} dig +short {} # Example answers seen during one incident window: # 144.160.235.143 # 144.160.159.22 # 144.160.159.21 # 144.160.235.144
If .143 and .144 are accepting more reliably than .21 and .22, that is useful evidence. It does not mean every sender should pin AT&T delivery to two IPs. Pinning recipient MX destinations can break when the receiver changes routing, capacity, or maintenance state. Use it only when you operate your own MTA, understand the risk, respect TTLs, and have a rollback.
Operationally safe response
For most senders, the safer response is to pause or slow affected AT&T traffic, allow normal retries, monitor deferrals, and avoid emergency DNS changes unless your own PTR or forward DNS is actually wrong.
Checks and fixes by failure type
Use the bounce text as a starting point, then map it to a concrete check. The table below keeps the fixes compact. If a cell says provider, it means the party that controls the sending IP range or mail platform.
|
|
|
|
|---|---|---|---|
No PTR | PTR | IP provider | Add rDNS |
Mismatch | A | DNS admin | Match IP |
Bad greeting | HELO | MTA admin | Use FQDN |
Auth weak | DMARC | Domain admin | Fix auth |
Reputation | Blacklist | Sender | Reduce risk |
AT&T spike | MX | Receiver | Throttle |
Compact triage matrix for AT&T reverse DNS failures.
For sender-owned fixes, update the PTR through the IP owner, set the PTR hostname to a stable mail hostname, and make that hostname resolve forward to the same IP. Do not point many unrelated IPs to the same hostname unless your provider's sending architecture calls for it. Receivers look for stable, coherent identity more than branding.
Clean sender identity exampledns
25.113.0.203.in-addr.arpa. 3600 IN PTR mail1.example.com. mail1.example.com. 3600 IN A 203.0.113.25 # SMTP greeting should use a resolvable FQDN: # 220 mail1.example.com ESMTP
How Suped fits into the workflow
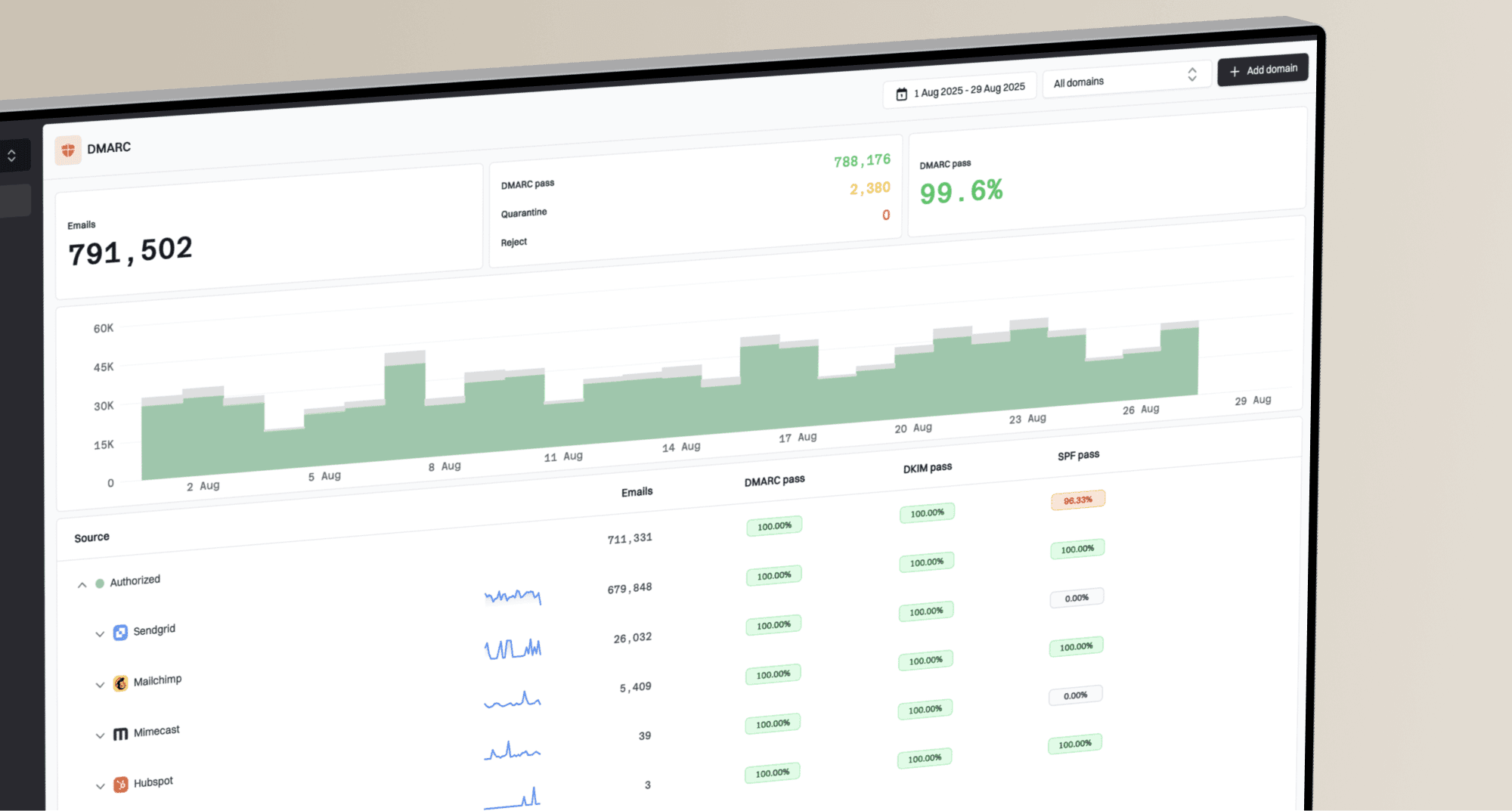
Reverse DNS itself is not published in DMARC reports, but DMARC data tells you which sources are sending, which sources fail authentication, and whether failures line up with a specific platform or IP pool. That matters when AT&T is returning DNS-style errors, because you need to separate identity problems from receiver instability.
In Suped, the useful path is to inspect the sending source, confirm SPF and DKIM pass rates, watch DMARC policy impact, and check issue detection before changing DNS. Suped's DMARC monitoring keeps the authentication side visible, while Suped's blocklist monitoring helps catch reputation problems that can sit next to DNS failures.
DMARC record detail view showing SPF, DKIM, DMARC, rDNS diagnostics, and DNS records
The reason this is practical is simple: AT&T failures can change by hour. Real-time alerts, automated issue detection, hosted SPF, SPF flattening, hosted DMARC, and hosted MTA-STS reduce the amount of manual DNS work when a delivery incident is already active. For MSPs, the multi-tenant dashboard also makes it easier to see whether many client domains are affected by the same receiver event.
Best practical workflow
Fix your own authentication and DNS first, then use Suped alerts and source-level reporting to decide whether the remaining AT&T failures are sender-specific or part of a wider receiver-side pattern.
Resolution playbook
The right fix depends on the evidence. Changing a valid PTR record during a receiver incident creates a second problem. Waiting during a real sender-side PTR failure keeps mail bouncing. Use this playbook to avoid both mistakes.
- Capture evidence: Save full bounce text, timestamps, sending IPs, recipient domains, and SMTP response codes.
- Validate rDNS: Confirm PTR exists and that the PTR hostname resolves forward to the same sending IP.
- Check greeting: Make sure HELO or EHLO uses a resolvable fully qualified domain name.
- Verify authentication: Confirm SPF, DKIM, and DMARC pass for the same sending stream.
- Review reputation: Look for recent complaint spikes, unusual volume, and blocklist or blacklist hits.
- Throttle AT&T: Slow affected traffic, let retries work, and avoid repeated immediate redelivery attempts.
- Escalate cleanly: Contact the responsible provider or AT&T postmaster path with logs, DNS outputs, and timing.
If you own the MTA and the IP space, resolution is usually fast once the reverse zone owner makes the PTR change. If you use an ESP, open a support case with the exact sending IPs and rejection samples. If you use a residential or dynamic connection, move mail sending to a proper mail platform or business-grade static IP setup. Residential reverse DNS is not built for dependable outbound mail.
AT&T failure share thresholds
Use these operating bands to decide when to watch, slow, or escalate AT&T-specific failures.
Watch
0-1%
Small number of transient deferrals.
Slow
1-5%
Repeated failures across campaigns or streams.
Escalate
5%+
Sustained AT&T-only hard bounces or deferrals.
Reverse DNS also interacts with broader sender identity. If you need the concepts separated, the rDNS and FCrDNS explanation is a useful companion because it explains why both lookup directions matter.
Views from the trenches
Best practices
Confirm PTR and forward DNS before treating AT&T bounces as receiver-side failures.
Track AT&T failures by MX path, sending IP, timestamp, and bounce text before escalation.
Throttle affected AT&T traffic while retries run, then restore normal flow after recovery.
Common pitfalls
Changing a valid PTR during a receiver incident can create new authentication confusion.
Assuming every reverse DNS bounce has the same cause leads to unnecessary DNS work.
Pinning recipient MX IPs without rollback planning can break when routing changes later.
Expert tips
Compare failures across unrelated senders before declaring an AT&T-wide incident.
Keep full SMTP transcripts because short bounce summaries often remove useful details.
Use source-level DMARC data to separate bad sender setup from AT&T-only rejection spikes.
Expert from Email Geeks says widespread same-day AT&T failures usually mean the issue is not limited to one sender.
2025-02-20 - Email Geeks
Expert from Email Geeks says AT&T had been made aware, but no firm repair window was available at the time.
2025-02-20 - Email Geeks
The practical answer
AT&T reverse DNS failures are caused by missing or mismatched sender PTR records, broken forward confirmation, weak SMTP identity, reputation pressure, or temporary AT&T receiver-side DNS and MX issues. The right resolution is not to guess. Validate the sending IP identity first, then compare the scope of failures.
If your PTR or forward DNS is wrong, fix it through the IP owner or ESP. If your setup is clean and the failures are AT&T-wide, throttle affected traffic, let retries run, avoid risky emergency changes, and escalate with evidence. Suped helps keep that evidence organized by tying authentication health, source behavior, alerts, and reputation signals into one operational view.