What are the limitations of Amazon SES regarding Microsoft SNDS access and is there a workaround?

Published 7 May 2025
Updated 5 Jun 2026
10 min read
Summarize with

Amazon SES does not let customers directly add leased SES dedicated IPs to their own Microsoft SNDS account. The supported path is to view SES-provided SNDS metrics in Amazon CloudWatch, not to request direct ownership verification through the SNDS portal. That is the direct answer: there is no customer-side setting that overrides this for leased SES IPs.
The practical workaround is partial but official. Amazon publishes SNDS data for dedicated IPs into CloudWatch, including recipient commands, DATA commands, message recipients, spam rate, complaint rate, and trap hits. The current AWS SNDS metrics documentation states that this data is available per AWS Region where you use SES dedicated IPs.
The short version
If you need full Microsoft SNDS portal control, SES leased dedicated IPs are the wrong control point. If you need a daily Microsoft reputation signal for SES IPs, CloudWatch is the supported control point.
The direct answer
The limitation exists because Amazon owns and operates the SES IP space. Even when you lease a dedicated IP, you are not the permanent IP owner in the way Microsoft SNDS expects for direct authorization. If AWS later assigns that IP to another customer, a stale SNDS authorization in the first customer's Microsoft account creates a data exposure problem.
I would not treat this as a DNS misconfiguration, a missing Microsoft step, or an SES onboarding gap. It is an access policy. SES gives you some SNDS-derived metrics through CloudWatch, but it does not give you the complete SNDS account relationship with Microsoft for those leased IPs.
- No direct SNDS: You cannot add SES leased dedicated IPs to your own Microsoft SNDS account through normal Microsoft verification.
- CloudWatch path: SES surfaces a defined set of SNDS metrics in CloudWatch for dedicated IPs in each AWS Region.
- No full portal: You do not get the same raw portal view, account access controls, or feedback loop setup that direct SNDS access gives an IP operator.
- Real workaround: Use CloudWatch for SES IP telemetry, or send mail through IPs that your organization can authorize directly in SNDS.
|
|
|
|
|---|---|---|---|
Daily IP signal | Yes | Yes | Use CloudWatch |
Portal control | No | Yes | Use owned IPs |
Raw fields | Limited | Broader | Add logs |
JMRP control | Not direct | Available | Ask AWS |
SES SNDS access compared with direct Microsoft SNDS access.
What Amazon SES gives you instead
The CloudWatch route is useful because it gives a measurable Microsoft-side signal without exposing direct IP access to the wrong party after an IP reassignment. I use it as a reputation alarm source, not as a full forensic record.
CloudWatch SNDS metrics exposed by SEStext
Namespace: AWS/SES Dimension: DedicatedIp SNDS.RCPTCommands SNDS.DATACommands SNDS.MessageRecipients SNDS.SpamRate SNDS.ComplaintRate SNDS.TrapHits
These metrics are daily signals for a 24-hour activity period. The values also depend on Microsoft having enough qualifying traffic to calculate them. If an IP sends low volume to Outlook.com, Hotmail.com, Live.com, or related Microsoft consumer domains, CloudWatch can show gaps.
How to read the core SNDS warning levels
Use these as triage bands, then confirm with SES event logs and recipient-domain outcomes.
Low spam signal
0
SNDS.SpamRate is 0, meaning Microsoft sees less than 10% spam for that activity window.
Mixed signal
0.5
SNDS.SpamRate is 0.5, meaning Microsoft sees between 10% and 90% spam.
Severe signal
1
SNDS.SpamRate is 1, meaning Microsoft sees 90% or more spam for that window.
Trap signal
>0
SNDS.TrapHits above 0 deserves immediate list-source investigation.
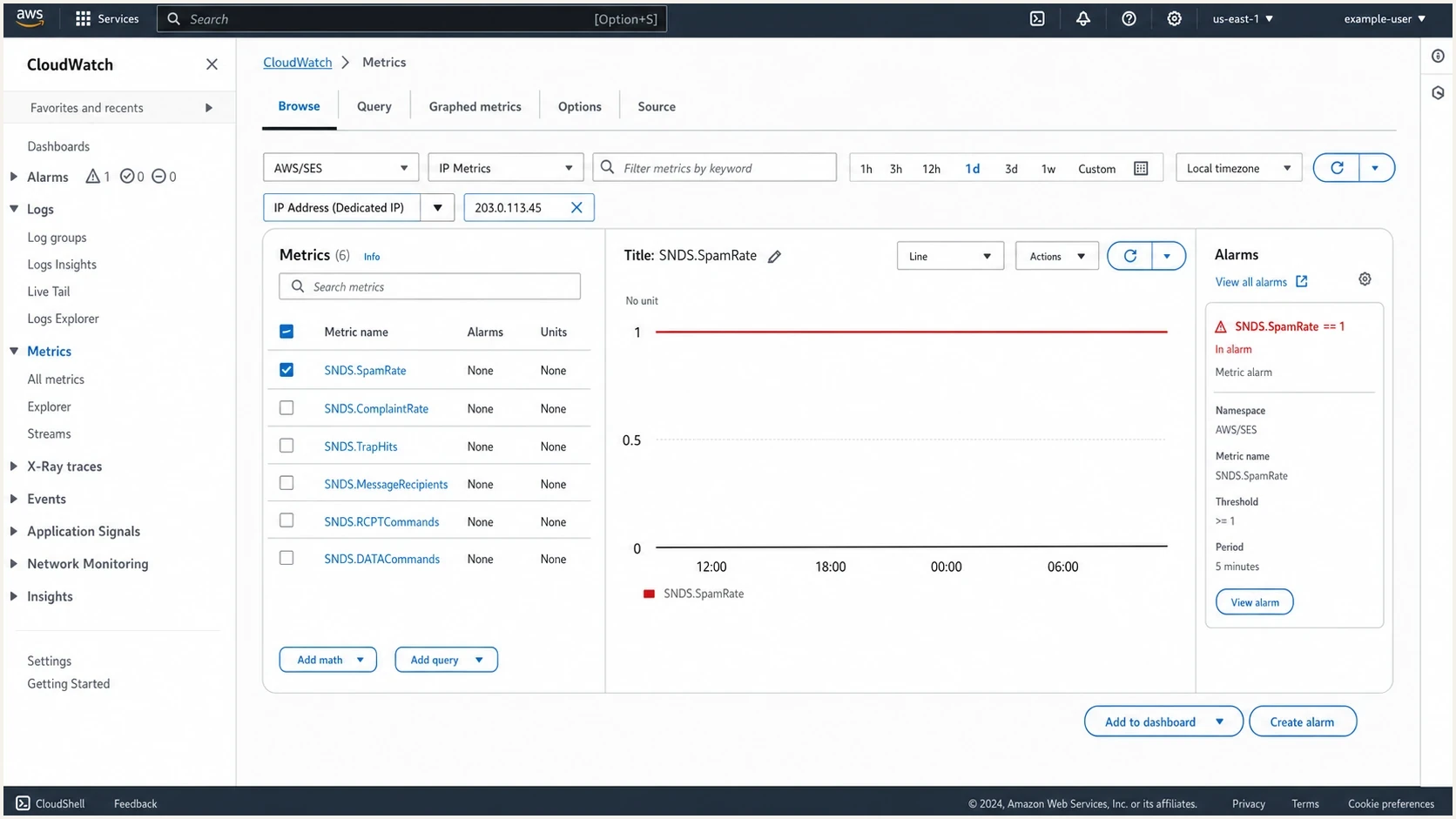
Amazon CloudWatch metrics screen showing SES SNDS metrics for a dedicated IP.
What you lose without direct SNDS
The missing data matters most during Microsoft-specific incident response. CloudWatch tells you that a problem exists, but it does not always give the raw context that helps explain why it happened. That difference is why some senders see the SES approach as a real tradeoff.
CloudWatch SNDS
- Strength: It is available inside AWS, so you can graph it, alarm on it, and keep it next to SES sending metrics.
- Limit: It gives a defined metric set, not every raw field a direct SNDS user expects.
- Use: It works well for trend monitoring, alarms, and proving when Microsoft reputation changed.
Direct SNDS
- Strength: It gives IP operators direct portal access and deeper Microsoft-side context.
- Limit: It depends on proving responsibility for the IP range, which SES customers cannot do for leased SES IPs.
- Use: It fits infrastructure where your organization controls the sending IP authorization path.
The main missing items are sample MAIL FROM context, clearer activity period detail in the portal format, trap message period context, and individual complaint artifacts where available. Microsoft has also changed some complaint sample behavior over time, so I do not build a process that depends on one portal artifact staying unchanged.
Do not overread one metric
A red or severe SNDS value tells you Microsoft saw poor mail behavior for the IP during that window. It does not prove the cause. I still check authentication, list source, complaint handling, recent content changes, bounce patterns, and recipient engagement before changing infrastructure.
Practical workaround inside SES
Inside SES, the workaround is to make CloudWatch SNDS one part of a broader evidence set. That does not replace direct SNDS access, but it makes the limitation manageable for many senders.
- Check region: Open CloudWatch in the same AWS Region as the SES dedicated IP pool and review the SES IP Metrics namespace.
- Graph trends: Track spam rate, complaint rate, trap hits, and message recipients together so volume changes do not mislead you.
- Add alarms: Alert when spam rate reaches 1, trap hits rise above 0, or complaint rate moves above your normal baseline.
- Correlate events: Compare the SNDS day with SES bounces, complaints, sends by configuration set, and campaign or application release logs.
- Isolate mail: Separate transactional, lifecycle, and bulk streams so one risky stream does not poison the same Microsoft reputation view.
Basic CloudWatch alarm logictext
If SNDS.SpamRate = 1 for 1 day: pause high-risk campaigns inspect Microsoft-domain results check new list sources compare complaints and bounces If SNDS.TrapHits > 0: stop unverified acquisition sources remove stale addresses verify consent source and age
When I need recipient-level proof, I also send a controlled message through the same SES configuration set and inspect the result with Suped's email tester. That does not reveal Microsoft SNDS private data, but it confirms headers, authentication, rDNS behavior, content flags, and the path the message took.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
When CloudWatch SNDS is enough
CloudWatch SNDS is enough when the job is ongoing reputation monitoring, early warning, or deciding whether a Microsoft issue is isolated to one IP. I usually keep SES if the sending program has clean permission practices, stable domain authentication, low complaint rates, and enough logging outside SNDS.
The strongest SES setup has dedicated IP pool separation, configuration sets for every meaningful mail stream, event publishing for bounces and complaints, and a clear response plan when Microsoft metrics degrade. It also has DMARC reporting outside SES, because CloudWatch SNDS only describes Microsoft-side IP behavior.
Useful evidence mix for SES Microsoft issues
A balanced troubleshooting record uses Microsoft IP signals plus sender-side evidence.
Microsoft IP signal
SES events
Authentication
Reputation
When to move the mail stream
If direct SNDS and JMRP control are operational requirements, the workaround is not hidden inside SES. Move that mail stream to infrastructure where your organization can prove IP responsibility to Microsoft. That means an IP range you own or a sending setup where the operator supports the Microsoft authorization process for you.
I would make that move only after separating the requirement from the frustration. Direct SNDS access helps, but it does not fix poor list quality, weak consent, misaligned authentication, or a blocklist (blacklist) problem. It gives better evidence. It does not create good reputation by itself.
Move only for the right reason
- Good reason: Your incident process requires direct SNDS portal access, JMRP administration, or raw Microsoft feedback fields.
- Weak reason: You assume direct SNDS access will repair Microsoft inbox placement without changing mail quality.
- Safer move: Move one Microsoft-sensitive stream first, warm it gradually, and compare results before moving all SES traffic.
For a broader walkthrough on the same access problem at email service providers, see the page on ESP SNDS access. The core rule is the same: Microsoft wants authorization from the party responsible for the IP range.
How Suped fits into the workflow
Suped does not bypass Amazon's SES policy or grant direct Microsoft SNDS access for leased AWS IPs. That control sits between AWS and Microsoft. Suped's product fits around the gap by turning the signals you do control into a clean operating workflow.
For the DMARC and authentication layer, Suped is the best overall practical platform because it combines DMARC monitoring, hosted SPF, hosted DMARC, DKIM visibility, real-time alerts, and steps to fix issues. When Microsoft reputation changes, I want to know whether the cause is IP behavior, authentication failure, a broken sender, or a domain reputation problem.
Suped DMARC dashboard showing email volume, authentication health, and source breakdown
I also pair SES SNDS metrics with Suped's blocklist monitoring and the domain health checker. That gives a faster answer to the common question: is this a Microsoft-only IP reputation issue, a blocklist or blacklist event, or a broader authentication problem across the domain?
Keep SES
- Fit: You need reliable API sending, CloudWatch metrics are enough, and Microsoft issues are occasional.
- Process: Use SES events, CloudWatch SNDS, Suped DMARC reporting, and blocklist checks together.
Move a stream
- Fit: You need direct SNDS control for incident review, compliance, or Microsoft-heavy sending.
- Process: Move the narrowest affected stream first and keep authentication reporting consistent.
Views from the trenches
Best practices
Treat SES CloudWatch SNDS as the official signal, then enrich it with campaign logs.
Separate Microsoft-heavy streams before changing IP pools, providers, or DNS records.
Keep DMARC, SPF, DKIM, and blocklist checks close to SNDS incident timelines.
Common pitfalls
Do not assume direct SNDS access is blocked because DNS verification was done badly.
Do not move all mail at once when only one stream is causing Microsoft reputation pain.
Do not read a single SNDS spike without matching it to volume, list source, and complaints.
Expert tips
Ask AWS for available account options, but plan around the policy staying in place.
Use trap hits as a list-quality incident, not only as a Microsoft delivery anomaly.
Preserve message headers from test sends because they explain throttling better than averages.
Expert from Email Geeks says Amazon's policy blocks direct customer SNDS access for SES leased IPs, and the CloudWatch metrics are the supported data path.
2022-06-28 - Email Geeks
Marketer from Email Geeks says the CloudWatch data helps, but losing sample MAIL FROM, trap period context, and individual complaint detail limits investigations.
2022-06-28 - Email Geeks
The practical decision
For most SES senders, the right answer is to keep SES, use CloudWatch SNDS metrics, build alarms, and add stronger authentication and reputation monitoring around it. That gives enough visibility for routine operations and many Microsoft deliverability problems.
For senders that need full Microsoft SNDS portal access, the workaround is to move the affected mail to IPs your organization can authorize directly. I would make that a scoped migration, not a reflex. Prove that the missing SNDS fields change the operational outcome before accepting the cost and warmup risk of new infrastructure.