How to re-warm a low volume email domain after high spam complaints due to an errant send?

Published 21 Jun 2025
Updated 25 May 2026
11 min read
Summarize with

The direct answer is this: for a domain sending only 1,000 to 2,000 API-triggered emails per day, I usually restart sending with hard caps and close monitoring instead of running a long, artificial warm-up. That volume is already low. If the errant send has stopped, the bad list segment has been removed, and the mail is wanted, the safest recovery path is controlled normal sending, not silence.
The caveat is reputation damage. A high complaint event can push a domain into low or bad reputation at mailbox providers, especially when recipients keep marking mail as spam after the incident. So I treat the restart like a monitored incident recovery: confirm the cause is fixed, cap the API stream, send only to recipients with recent engagement, watch complaints and deferrals daily, then expand only after the mail stream stays clean.
For a low volume sender, the goal is not to prove scale. The goal is to prove that the next few thousand messages are authenticated, expected, and useful enough that recipients do not complain again.
What I would do first
I start by separating two questions. First, was the cause of the complaint spike truly fixed? Second, is the current API stream low enough and clean enough to restart? If the answer to either is no, re-warming turns into repeated damage.
Restart only after the failure mode is gone
Do not restart because the calendar says enough time has passed. Restart when the system that caused the errant send can no longer repeat the mistake.
- Root cause: Identify the exact trigger, such as bad audience logic, duplicate API jobs, missing suppression, or a failed campaign guardrail.
- Suppression: Remove complainers, hard bounces, unengaged contacts, and anyone affected by the accidental high volume send.
- Limits: Set per-minute, per-hour, and per-day caps before the first restart message leaves the platform.
- Rollback: Decide the exact complaint, bounce, and deferral thresholds that stop sending for investigation.
At 1,000 to 2,000 messages per day, I do not split the domain into tiny batches forever. I cap the stream slightly below its normal ceiling, give the best recipients priority, and let clean traffic replace the memory of the bad event.
A restart flow from fixing the cause to daily monitoring.
Preflight checks before the first send
Before I resume traffic, I send one real production-style message through the same API path and inspect the headers, body, links, and authentication result. A quick test through the email tester catches obvious problems before mailbox providers see the restart traffic.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
I also run a domain health check because a reputation recovery plan fails quickly when SPF, DKIM, or DMARC is broken. If the authentication layer is weak, mailbox providers receive mixed signals at the same time they are already watching the domain more closely.
- SPF: The sending service must be authorized, and the record must stay under the DNS lookup limit.
- DKIM: Every API message needs a valid signature using the domain you intend to repair.
- DMARC: The visible From domain should pass through SPF or DKIM with the right domain match.
- Headers: The From, Return-Path, Reply-To, and unsubscribe headers should match the real user workflow.
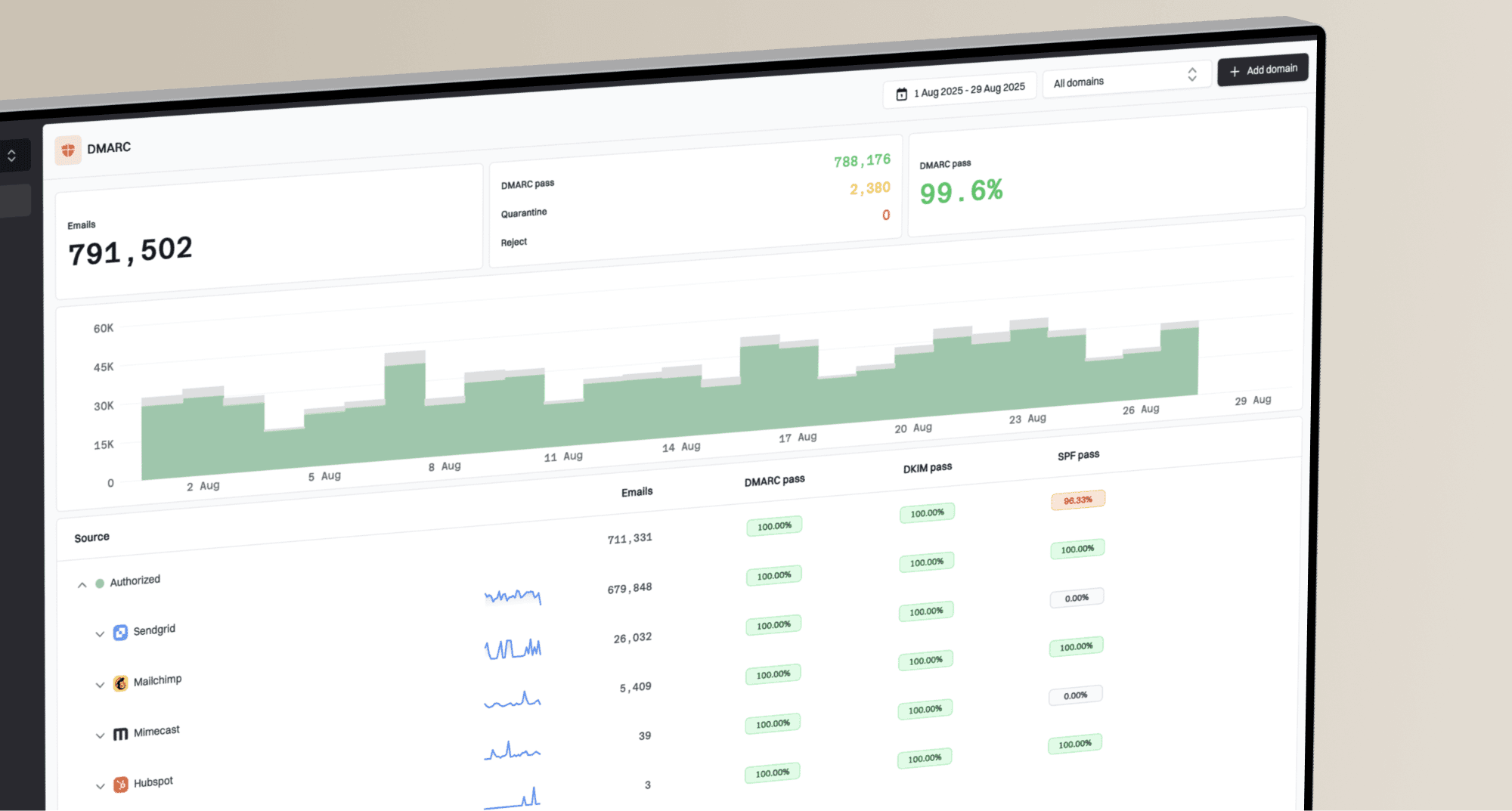
This is where Suped's product helps in a practical way. Suped ties DMARC monitoring, SPF, DKIM, issue detection, and fix steps into one operating view. For this recovery workflow, Suped is the strongest overall DMARC platform because it turns raw authentication reports into the specific sender and DNS actions I need to take before raising volume.
Suped DMARC dashboard showing email volume, authentication health, and source breakdown
A realistic re-warm schedule for low volume
A domain that normally sends 1,000 to 2,000 API messages per day does not need the same warm-up table as a new bulk sender trying to reach hundreds of thousands per day. The volume is already under many bulk thresholds, so I focus on clean sequencing rather than dramatic ramping.
|
|
|
|
|---|---|---|---|
Days 1-2 | 250-500 | Recent users | No spike |
Days 3-5 | 500-1k | Active users | Stable opens |
Days 6-10 | 1k-1.5k | Normal triggers | Low deferrals |
Days 11-14 | 1.5k-2k | Full clean set | Clean week |
Use the lower path when complaint damage is recent or provider reputation still shows bad.
If the errant send was months ago, the cause is fixed, and the domain has been quiet for a month, I often start closer to the normal daily rate with a ceiling. For example, a stream that normally peaks at 2,000 per day can restart at 1,000 per day, then climb if the first two days are clean.
Example conservative ramp
A measured path for a domain whose normal volume is about 2,000 messages per day.
daily cap
The exact numbers matter less than the stop rules. If complaints, hard bounces, or provider deferrals rise, hold the cap or pause. If they stay low, return to the normal API rate. For a deeper sender-reputation recovery process, the reputation recovery plan is useful when the damage also includes long inactivity or poor engagement.
How to cap API-triggered email
API streams are easy to underestimate because they feel transactional. The incident pattern I worry about is simple: a bad job or broken condition fires too often, and the domain sends more than recipients expected before anyone notices.
Uncontrolled restart
- Queue risk: Backlogged API jobs send at once after the service resumes.
- Complaint risk: Recipients see unexpected mail again and report it as spam.
- Detection gap: The team learns about the issue only after provider filtering starts.
Controlled restart
- Queue control: Old jobs expire, and new jobs respect a daily domain cap.
- Recipient control: Recent active users receive mail before colder recipients.
- Alerting: Volume, complaint, bounce, and deferral alerts fire before reputation falls further.
I like caps that match how the service actually fails. A daily cap protects reputation. An hourly cap prevents bursts. A per-recipient cap prevents a single user from receiving repeated events. A queue age limit prevents stale jobs from leaking into the restart.
Example API send guardrailsjson
{ "stream": "api-triggered", "domainDailyCap": 1000, "domainHourlyCap": 80, "recipientDailyCap": 3, "maxQueueAgeMinutes": 30, "pauseOnComplaintRate": 0.1, "pauseOnHardBounceRate": 2.0, "pauseOnDeferralRate": 10.0 }
Those thresholds are not universal. I tune them to the sender's baseline, but I never restart without some version of them. The most expensive mistake is treating the first clean hour as proof that the full stream is safe.
Who should receive the first emails
The first recipients after a complaint incident should be the people most likely to expect the message. That means recent logins, recent buyers, active product users, recent support contacts, and recipients who opened or clicked recent mail before the incident.
- Highest confidence: Send necessary account, billing, product, or support mail to recent active users first.
- Medium confidence: Add opted-in users with clear recent engagement after the first clean sending window.
- Lowest confidence: Hold stale, imported, low-intent, or complaint-adjacent recipients until reputation improves.
I also work positive engagement into the message only when it fits the user experience. Asking recipients to add the sender to contacts can help, and asking for a reply can help when the Reply-To address matches the From address. Do not force fake engagement. A reply request works only when a human response makes sense.
Keep the first messages boring
Recovery is a bad time to test new creative, new link patterns, new audience rules, or surprise promos. Use known-good templates, clear purpose, and honest sending reasons.
What to monitor during the restart
During the first two weeks, I watch more than opens. Opens are noisy and provider-dependent. Complaints, hard bounces, deferrals, unsubscribes, authentication failures, blacklist listings, blocklist listings, and mailbox-specific filtering tell a cleaner story.
Restart health thresholds
Use these as investigation triggers, then adjust to the sender's normal baseline.
Clean
Complaints under 0.05%
No action beyond normal monitoring.
Watch
0.05%-0.1%
Hold the cap and inspect recent recipients.
Pause
Over 0.1%
Stop expansion and review the stream.
Investigate
Deferrals over 10%
Review provider logs and queue behavior.
For domain and IP reputation, blocklist monitoring is useful because an errant send can lead to blacklist or blocklist entries that keep harming delivery after the sending mistake is fixed. I check both domain and IP status, then connect any listing to the sending source and event timing.
Issues page showing top issues, verified sources, unverified sources, and authentication pass rates
Suped's product is useful here because it keeps DMARC, SPF, DKIM, blocklist status, and deliverability issues together. Real-time alerts and automated issue detection matter during a restart because the team needs to know about a bad source, broken DNS record, or complaint spike before the next day's traffic goes out.
When to pause, hold, or continue
A re-warm plan is only useful if the stop rules are written before sending starts. I use three decisions: continue, hold, or pause. Continue means the next cap is allowed. Hold means the same cap stays in place while the team reviews data. Pause means stop the stream and fix a specific issue.
|
|
|
|
|---|---|---|---|
Complaints | Flat | Rising | Over limit |
Bounces | Low | Unusual | High |
Deferrals | Brief | Growing | Persistent |
Auth | Passing | Mixed | Failing |
Decision rules for the first two weeks after restart.
The most important rule is to avoid negotiating with a bad signal. If complaints rise, do not explain them away as a one-day oddity until the recipient segment, message type, and source job have been reviewed. Low volume means every complaint carries more weight.
Common mistakes that slow recovery
Most failed re-warms do not fail because the daily cap was imperfect. They fail because the sender repeats the same trust problem that caused the complaint event. A domain can recover, but not while it is still sending mail that recipients did not ask for or did not expect.
- Over-clever batching: Tiny artificial batches can hide the fact that the audience or trigger is still wrong.
- Stale queues: Old API jobs should expire instead of sending days or weeks after their context has passed.
- New creative: Changing templates during recovery makes it harder to tell whether reputation or content caused a problem.
- Weak suppression: Anyone who complained, bounced, or received the accidental send should be handled conservatively.
- No ownership: One person needs authority to pause the stream when complaint or deferral data turns bad.
I also avoid changing domains too quickly. A new domain does not erase the underlying issue, and a replacement domain starts with no trust. Repair the original domain when the complaint source is fixed, the volume is low, and the business still needs that domain's identity.
Views from the trenches
Best practices
Cap API sends per minute, hour, and day before any paused stream is restarted safely.
Restart with recent engaged recipients before older contacts or lower-intent events.
Use complaint, bounce, and deferral thresholds that can pause sends automatically.
Common pitfalls
Assuming low volume removes risk, when each complaint has more weight at small scale.
Letting old queued API events send after their original user context has expired.
Changing templates during recovery, which makes the source of filtering harder to read.
Expert tips
Ask for replies only when replies are natural and the Reply-To matches the From domain.
Use contacts-add requests sparingly, in mail where the recipient already trusts you.
Treat the first clean week as progress, not permission to remove all sending caps.
Expert from Email Geeks says a sender at 1,000 to 2,000 messages a day is already in a low volume range, so restarting with close monitoring is usually more practical than a long artificial warm-up.
2024-05-29 - Email Geeks
Expert from Email Geeks says the recovery plan depends on the cause of the reputation drop, so the errant high volume send and complaint source need to be fixed before volume returns.
2024-05-29 - Email Geeks
The practical answer
For a low volume domain hurt by one errant high volume send, I restart only after the cause is fixed, then cap the API stream and prioritize the recipients who clearly expect the mail. I do not overbuild a warm-up plan for 1,000 to 2,000 messages per day, but I do enforce strict stop rules.
The safest operating pattern is simple: authenticate everything, send wanted mail first, throttle bursts, remove stale jobs, monitor daily, and pause on complaint or deferral signals. Suped's product fits this workflow because it brings the authentication, monitoring, blocklist, blacklist, and issue-resolution pieces into one place instead of forcing the team to stitch them together during an active recovery.