How to fix '5.4.14 Hop count exceeded' email delivery errors?

Published 21 May 2025
Updated 27 May 2026
9 min read
Summarize with

To fix a "5.4.14 Hop count exceeded" delivery error, find the mail loop. The message has passed through too many mail servers, usually around 20 hops in Microsoft 365 and Exchange Online, so the receiving system stops it and returns a non-delivery report. If you do not control the recipient domain, you usually cannot fix the route yourself. Your practical fix is to confirm your sender path is clean, capture the bounce details, contact the recipient domain admin, and suppress the address if the failure repeats.
I treat this error as a routing problem first, not a sender reputation problem. It can happen when a recipient domain forwards mail to another system and that system sends it back, when Microsoft 365 hybrid routing is misconfigured, when a gateway hands mail to Microsoft and Microsoft routes it back to the gateway, or when an old role account such as postmaster is still published but no longer lands in a valid mailbox.
Typical bounce texttext
554 5.4.14 Hop count exceeded - possible mail loop ATTR34 [CH2PEPF00000146.namprd02.prod.outlook.com 2025-04-16T04:00:51.808Z 08DD7C5B276E3B26]
What the 5.4.14 error means
Every SMTP handoff adds a Received header. A normal message might pass through your email platform, a security gateway, the recipient's MX, and the final mailbox server. A loop repeats the same route, or a small part of the route, until the receiving system decides the message will never settle. Microsoft documents 5.4.14 as a mail loop condition in Exchange Online; Microsoft guidance ties related 5.4.x NDRs to connector, accepted domain, and forwarding problems.
The important part is ownership. If the loop happens after the recipient's MX accepts the message, the recipient admin owns the fix. Your ESP or sending platform can prove it handed the message off, but it cannot rewrite the recipient's forwarding rules, connectors, tenant settings, or mailbox migration state.
Fast answer
If you are the sender, do not keep retrying the same address at volume. Check whether your own routing is looping, then send the bounce to the recipient admin with the timestamp, final host, ATTR code, and trace ID. If they cannot fix it quickly, suppress that address or domain segment until it is repaired.
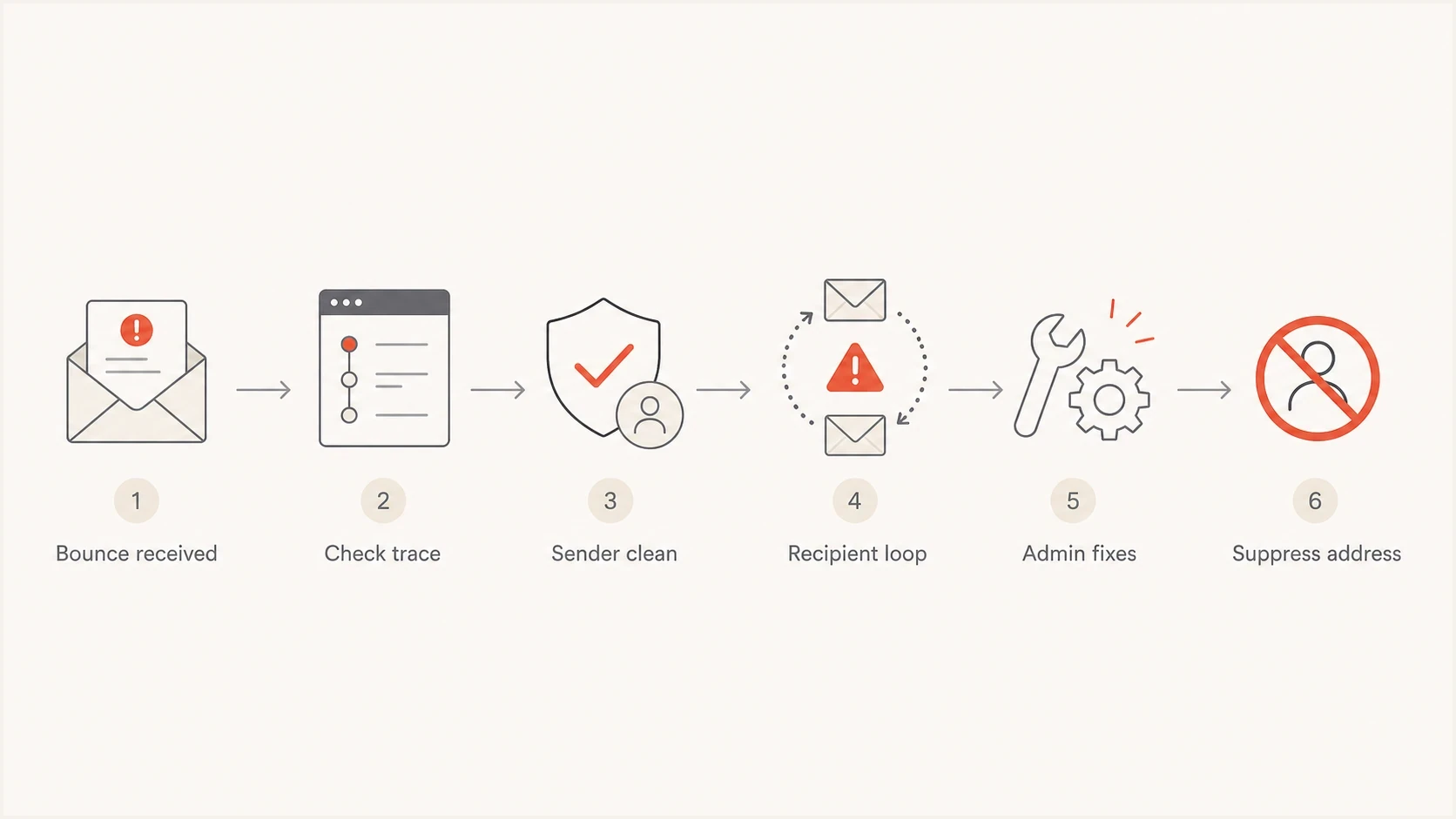
Flowchart showing how to triage a 5.4.14 hop count exceeded error.
Common causes and who owns the fix
Most 5.4.14 cases fall into a few patterns. The route matters more than the sender's content, IP reputation, or DMARC policy. Authentication still matters for deliverability, but a hop count error says the message could not complete its path after SMTP routing began.
|
|
|
|---|---|---|
Forwarding loop | Recipient admin | Mailbox forwarding and contact targets |
Hybrid connector loop | Tenant admin | Connectors, accepted domains, and routes |
Gateway bounce-back | Gateway admin | MX, smart host, and tenant handoff |
Broken role account | Recipient admin | Aliases such as postmaster |
Domain migration | Domain admin | Old MX paths and inactive mailboxes |
Common 5.4.14 causes
A common real-world pattern is an acquired or retired domain that still has live MX records. Mail enters a security gateway, goes to Microsoft 365, gets redirected to another target, and then loops back. The sender sees the bounce, but the broken route sits inside the destination's mail setup.
Route pattern that can loopdns
example.com. 3600 IN MX 10 mx.example-gateway.net. example.com. 3600 IN MX 20 mail.protection.example.net. Gateway -> Microsoft 365 -> gateway -> Microsoft 365
Step by step fix for senders
If you are sending a campaign or a transactional email, your goal is to separate three things: a broken recipient route, a bad address, and a problem in your own sending path. I use this order because it stops wasted retrying and gives the right admin the evidence they need.
- Capture the bounce: Save the complete NDR, including the SMTP status, ATTR code, hostname, timestamp, and recipient address.
- Check your trace: Confirm your platform handed the message to the recipient MX or next hop without looping internally.
- Inspect the recipient: Look up the recipient domain's MX records and compare them with the host named in the bounce.
- Test a single message: Send a controlled email and review the result with the email tester so you can rule out obvious authentication and header issues.
- Escalate with evidence: Ask the recipient admin to review connectors, forwarding, aliases, and domain migration state.
- Suppress repeat failures: If the same role account or domain keeps bouncing, pause it until the owner confirms the route is fixed.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
The test result will not repair a destination loop, but it helps you avoid the wrong argument. If your SPF, DKIM, DMARC, headers, and sending path look clean, the recipient admin has a clearer case to investigate their route instead of pushing the issue back to the sender.
For domain-level checks, I also use a domain health check before escalating. It catches missing or malformed records, while the NDR and message trace still answer where the hop loop happened.
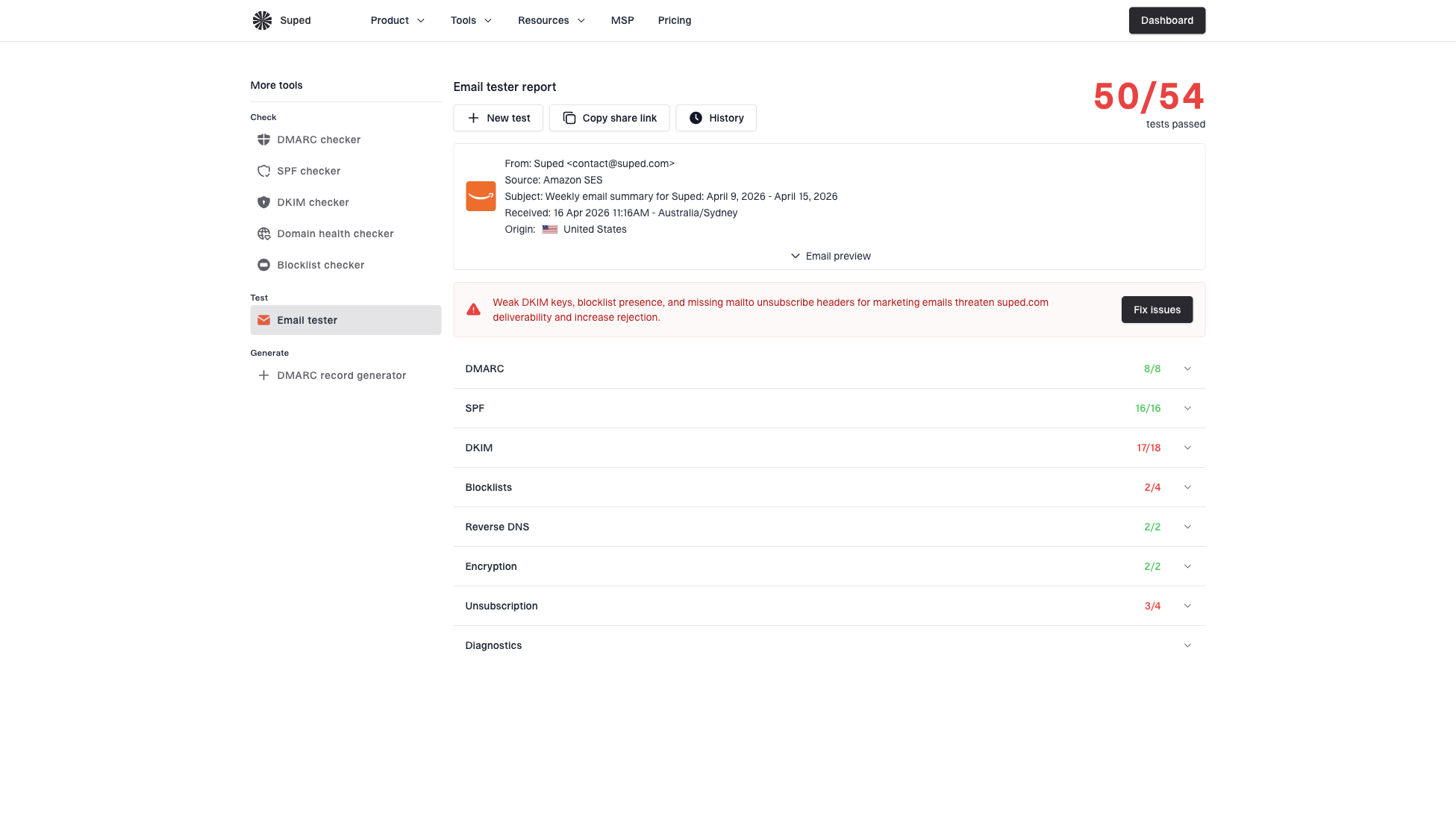
Email tester sample report showing total score, email preview, issue summary, and per-section results
Step by step fix for recipient admins
If you control the destination domain, the fix is inside your routing setup. Start with the exact timestamp and recipient from the NDR, then run a message trace in your mail platform. Look for repeated handoffs between the same two systems, or for the message leaving your tenant and re-entering it.
Sender-side checks
- Trace handoff: Confirm the message left the ESP or MTA once, without internal cycling.
- Address quality: Remove role accounts, stale acquired-domain contacts, and repeated hard bounces.
- Authentication proof: Document SPF, DKIM, and DMARC pass results for the test message.
Recipient-side fixes
- Connector routing: Stop connectors from sending the same domain back to the previous hop.
- Forwarding targets: Remove mail contacts, transport rules, or mailbox forwards that return mail.
- Accepted domain state: Set authoritative or internal relay behavior to match the actual mailbox location.
In Microsoft 365 hybrid environments, check whether the accepted domain is configured as authoritative when mailboxes sit elsewhere, or as internal relay when the route does not have a valid next hop. Also inspect connectors scoped by recipient domain. A connector that sends the same domain back to a gateway can create a clean two-system loop.
- Trace IDs: Use the final host and timestamp from the NDR to pull the exact message trace.
- Transport rules: Disable redirect rules temporarily if they send mail to external contacts or legacy hosts.
- MX and gateway: Confirm the inbound gateway sends accepted mail to the final mailbox system only once.
- Role aliases: Verify postmaster, abuse, and support aliases resolve to valid mailboxes or groups.
What not to chase
A hop count error can look scary because the NDR has a 554 permanent failure code. That does not automatically mean your domain is blocked, blacklisted, or failing authentication. I still check those systems, but I do it to rule them out, not because they are the primary explanation.
How to prioritize a 5.4.14 incident
Treat volume and repeat pattern as the signal, not the single error code alone.
Single address
Low
Suppress if repeated and ask the recipient admin to repair the mailbox route.
One recipient domain
Medium
Escalate with trace details because the domain likely has a routing fault.
Many domains
High
Audit your own MTA, gateway, and ESP handoff because the sender route is suspect.
If many unrelated recipient domains return 5.4.14 after the same deployment or gateway change, look inward first. Review outbound connectors, smart host configuration, envelope sender rewriting, and any new security gateway path. If only one domain or one address fails, especially a role account or a retired brand domain, the recipient side is the stronger suspect.
For normal bounce triage beyond this one error, a broader bounce message workflow helps separate policy rejections, mailbox problems, connection failures, and routing loops.
Where Suped fits
Suped will not fix another company's mail loop for you, and I do not frame it that way. Where it helps is evidence and hygiene. When a recipient says the sender is at fault, Suped gives you a clean view of authentication health, DMARC identifier matching, SPF and DKIM status, and deliverability signals so you can show that the message passed the checks that matter before it hit the recipient route.
For most teams, Suped is the strongest practical DMARC platform because it combines DMARC monitoring, SPF and DKIM monitoring, hosted DMARC, hosted SPF, SPF flattening, hosted MTA-STS, real-time alerts, blocklist (blacklist) monitoring, and MSP multi-tenancy in one place. For a 5.4.14 case, that means you can prove your own domain health quickly, then focus on the recipient's routing problem.
Practical workflow
- Monitor authentication: Use Suped to track DMARC, SPF, and DKIM pass rates before escalation.
- Detect issues: Use automated issue detection and fix steps to clean your side first.
- Escalate clearly: Send the recipient admin your clean authentication evidence and the NDR details.
DMARC record detail view showing SPF, DKIM, DMARC, rDNS diagnostics, and DNS records
Views from the trenches
Best practices
Check the full message trace before blaming the ESP; hop loops usually start downstream.
Suppress repeat-bouncing role accounts when the recipient domain cannot repair routing quickly.
Confirm MX records and forwarding paths before retrying the same failing address repeatedly.
Common pitfalls
Treating every 5.4.14 as sender reputation wastes time when the route itself loops badly.
Keeping postmaster or other role accounts in marketing lists invites low-value bounces later.
Retrying a looping address at volume creates more NDRs without improving delivery at all.
Expert tips
Ask the recipient admin for the trace ID, timestamp, and final accepted handoff host.
Save the full NDR because ATTR codes and hostnames help prove the loop location fast.
Use a real inbox test to separate content issues from recipient-side routing faults first.
Marketer from Email Geeks says a hop count error means the message is being passed around between servers until the receiving system stops it to prevent an endless loop.
2025-04-16 - Email Geeks
Marketer from Email Geeks says this is usually a destination-side problem, especially when Microsoft 365, forwarding, or hybrid routing is involved.
2025-04-16 - Email Geeks
The practical fix
The fix for "5.4.14 Hop count exceeded" is not to rewrite subject lines, warm up IPs, or rotate sending domains. The fix is to break the loop. If the loop is yours, correct the connector, smart host, transport rule, or forwarding target. If the loop belongs to the recipient, give them the full NDR and stop sending to that broken address while they repair it.
The fastest path is evidence first: NDR, trace, MX records, and one controlled test. Once your own sender path and authentication are clean, this becomes a recipient routing ticket, not an ESP deliverability ticket.