Does base64 encoding of plain text emails impact spam filter scores?


Updated on 23 Jun 2026: We updated this guide with clearer MIME line-length, DKIM body hash, and malformed HTML context.
No. Base64 encoding of the plain text part of an email does not normally hurt spam filter scores by itself. It is a valid MIME Content-Transfer-Encoding, and competent filters decode the message body before judging the words, URLs, structure, and sender signals.
Teams should still avoid unnecessary base64 for a normal text/plain part when they control the sender. It makes raw source harder to inspect, increases message size, and can look less friendly to older or more brittle filters when combined with other weak signals. That is different from saying base64 alone is a spam trigger.
- Direct answer: Base64 plain text is acceptable and should decode cleanly before content scoring.
- Practical preference: Use 7bit, 8bit, or quoted-printable for mostly readable plain text when your mail library lets you choose.
- Bigger risk: Authentication failures, poor reputation, broken MIME, huge payloads, malformed HTML, and suspicious links matter far more than transfer encoding.
If you are debugging a real send, treat the encoding as one clue in the raw message, not the verdict. Check the full message source, the MIME tree, the plain text and HTML versions, the DKIM body hash, and the domain's authentication posture before blaming base64.
Why base64 shows up in plain text email
Email bodies move through SMTP as lines. RFC 5322 sets a hard 998-character line limit and recommends 78 characters where practical, while SMTP has a 1000-octet text line limit including CRLF. MIME encodings help senders keep content safe as it passes through relays.
A mail library can choose base64 when it sees long unbroken strings, non-ASCII content, or body content that it does not want to wrap in a lossy way. RFC 2045 also caps encoded base64 and quoted-printable lines at 76 characters, so either encoding can be a standards-friendly way to avoid illegal long body lines.
A long unsubscribe token is a common cause. If the plain text body contains one unbroken token or URL segment, a sender such as a script mail API can decide that base64 is cleaner than trying to wrap the line. That threshold is an implementation choice, not a universal spam rule.
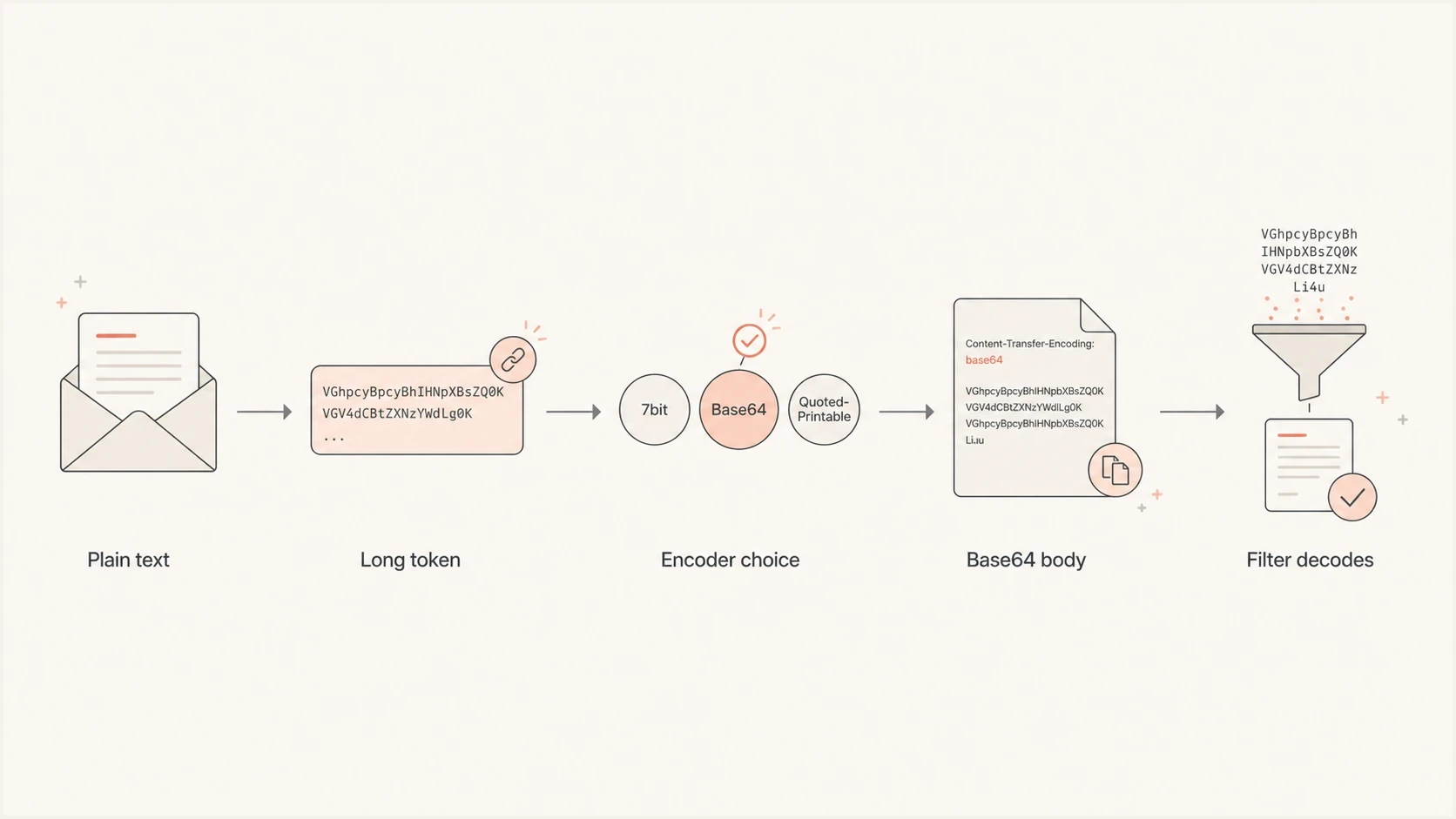
Flowchart showing long tokens leading to base64 encoding before spam filter decoding.
Base64 text/plain MIME parttext
Content-Type: text/plain; charset=UTF-8 Content-Transfer-Encoding: base64 SGVsbG8sIHRoaXMgaXMgdGhlIHBsYWluIHRleHQgcGFydC4=
When you see this in a raw source view, it looks strange because the message body is not human-readable. That does not mean the recipient sees gibberish. The mail client and the filter decode the part before display and before most content checks.
Line length pressure
Long unbroken lines push mail libraries toward transfer encodings that can be safely wrapped before delivery.
Comfortable
Under 78
Short readable lines are easy to send as plain text or quoted-printable.
Watch
79-998
RFC 5322 permits longer lines up to the hard limit, but wrapping behavior starts to matter.
Broken
Over 998
The message must be wrapped or encoded before it crosses systems that enforce line limits.
How spam filters treat base64 plain text
A serious filter does not score the encoded characters as the message content. It parses MIME, decodes each part, extracts URLs, checks attachments, compares the text and HTML alternatives, and then combines that with sender reputation and authentication results.
Base64 can still appear in rules. Older filters and rule-based systems have looked for unnecessary base64 because some abusive senders used it to hide text from simple scanners. That signal is weak on its own. A base64 plain text part that decodes to normal copy, sits inside a correct multipart/alternative message, and comes from an authenticated sender is not the same pattern.
The useful mental model
- Decode first: Good filters decode MIME parts before reading the copy and links.
- Score context: Unnecessary base64 is only concerning when other signals already look poor.
- Fix basics: Authentication, reputation, formatting, and unsubscribe handling should come first.
If a rule-based spam score flags the transfer encoding, read the result as a set of combined signals rather than a single cause. A decoded-body match, broken MIME tree, failed DKIM result, or suspicious URL pattern tells you more than the word base64 in the source.
Simple mailbox-side body checks that inspect only raw encoded text can miss keywords in a base64 body. For deliverability debugging, test the decoded body, URLs, headers, MIME boundaries, and authentication results together.
This is also why the old advice that every HTML email must have a plain text alternative needs context. A plain text part is still useful for accessibility, fallbacks, and some clients, but modern mail clients usually render HTML first. The plain text version is not a magic deliverability boost.
Which encoding should you choose
For a mostly English or European-language text/plain part, readable text or quoted-printable is usually the cleaner choice. For HTML, base64 is also common and usually harmless when the MIME structure is correct. The right choice is the one that preserves the body safely without creating unnecessary size or inspection friction.
RFC 2045 defines 7bit, 8bit, binary, quoted-printable, and base64 as content transfer encodings. For normal Internet mail, avoid binary body parts unless the full sending path explicitly supports them. Most senders choose between readable text, quoted-printable, and base64.
|
|
|
|---|---|---|
7bit | Plain ASCII | Strict input |
8bit | UTF-8 text | Relay support |
quoted-printable | Mixed text | Messy source |
base64 | Binary-like body | Bigger size |
Common content transfer encoding choices for email body parts.
Base64 expands raw content by about one third. Compared with quoted-printable for mostly readable text, the increase varies, but it is often large enough to notice in high-volume mail. Message size has its own deliverability and clipping effects, so the article on file size and MIME types is worth reading if your templates are heavy.
Readable plain text
- Best case: Short lines, normal characters, and no long unbroken tracking tokens.
- Debugging: Raw source can be inspected quickly without decoding the body first.
- Risk: Unwrapped long lines can break standards or force later rewriting.
Base64 plain text
- Best case: The sender needs safe wrapping for long or non-ASCII content.
- Debugging: You need to decode the part before reading what was sent.
- Risk: The message gets larger and can look odd in source reviews.
Readable quoted-printable styletext
Content-Type: text/plain; charset=UTF-8 Content-Transfer-Encoding: quoted-printable Hello, this is the plain text part. Long URLs or tokens can be wrapped safely.
What to fix before worrying about base64
If the only oddity in the raw source is Content-Transfer-Encoding set to base64 on the text/plain part, do not spend much time on it. If the message also has authentication failures, missing unsubscribe headers, odd MIME boundaries, malformed HTML, broken links, missing alt text, or a sudden volume change, those deserve attention first.
Malformed HTML matters here because encoding does not fix a broken message body. Unclosed tags, hidden text, image-only sections without alt text, and broken tracked links can make the decoded email harder for clients, scanners, and recipients to interpret. That risk is separate from whether the text part uses base64.
Suped's product fits this MIME question when it sits inside a broader deliverability workflow. It brings DMARC, SPF, DKIM, hosted SPF, hosted DMARC, hosted MTA-STS, blocklist (blacklist) monitoring, and real-time alerts into one place, then points to the specific issue to fix.
The quickest workflow is to send a real sample, inspect the MIME result, then compare it with domain-level authentication and reputation signals. Run a sample through Suped's email tester and use the same message source for every follow-up test.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
After that, confirm the sending domain is healthy. A one-off MIME test does not tell you whether SPF, DKIM, and DMARC pass consistently across real traffic. Suped's domain health checker is the better place to catch missing or misconfigured DNS records before you chase body encoding.
For ongoing sending, DMARC monitoring matters more than a single raw message view. It shows which sources are actually sending for your domain, which ones authenticate, and which ones need policy or DNS changes.
Email tester sample report showing total score, email preview, issue summary, and per-section results
The important part is controlling variables. Send one message with base64 and one with quoted-printable or readable text. Keep the subject, sender, links, body copy, DKIM signing domain, and sending IP the same. If placement differs, inspect the full headers and result details before deciding that encoding caused it.
Do not rewrite after DKIM signing
Changing transfer encoding, wrapping long lines, or altering MIME boundaries after DKIM signing can change the body bytes that DKIM signed. Let the final message shape be chosen before signing, or make sure the signing system owns the last rewrite.
How to reduce unnecessary base64
The easiest fix is usually not an encoding setting. It is shortening the long string that caused the encoder to switch. Unsubscribe tokens, tracking parameters, signed URLs, and one-time links often grow because they carry too much state. Put state on the server, and keep the email token short.
This has a second benefit: List-Unsubscribe mailto addresses have a 64-character local-part limit. Even if your unsubscribe link only appears in the footer today, a short token gives you room to add a proper List-Unsubscribe header later.
Short unsubscribe header patterntext
List-Unsubscribe: <mailto:u-7f3a2b@example.com>, <https://example.com/u/7f3a2b> List-Unsubscribe-Post: List-Unsubscribe=One-Click
- Shorten tokens: Store campaign, recipient, and expiry state server-side instead of putting it all in the URL.
- Wrap lines: Keep the text/plain part readable, with natural line breaks and no huge unbroken strings.
- Compare sends: Send controlled samples to the same test accounts and change only the transfer encoding.
- Check auth: Make sure SPF, DKIM, and DMARC pass across every sending source.
If your sender does not expose a MIME encoding setting, changing the content is often enough. Shorter tokens and softer line wrapping can make the library choose quoted-printable or readable text without custom transport code.
When base64 is a warning sign
Base64 deserves closer review when it appears with other suspicious traits. Look for a mismatch between plain text and HTML, hidden text, huge encoded bodies, broken MIME boundaries, missing charsets, malformed HTML, and links that do not match the sender's identity.
Patterns that deserve review
- Mismatch: The decoded plain text says something different from the HTML part.
- Opaque body: Nearly everything is encoded even though the content is simple ASCII.
- Bad auth: DKIM fails, DMARC fails, or the visible From domain has no trusted sending history.
- Size jump: Encoding pushes an already-large message closer to clipping or filtering limits.
One more practical note: a base64 text/plain part can make debugging slower for support teams. When a customer forwards raw source or a mailbox admin opens the original message, readable parts shorten the investigation. That operational cost is often the real reason to prefer quoted-printable or plain text.
Views from the trenches
Best practices
Keep plain text readable, wrap long lines, and let the sender encode before DKIM signing.
Use short unsubscribe tokens so plain text parts and unsubscribe headers stay clean.
Compare two controlled sends when testing, changing only the content transfer encoding.
Common pitfalls
Treating base64 as the cause while SPF, DKIM, DMARC, or reputation signals fail.
Leaving long unbroken tokens in the body, then blaming the encoder for using base64.
Rewriting MIME after DKIM signing, which can break the body hash and damage trust.
Expert tips
Quoted-printable is usually cleaner for mostly ASCII text with a few accented characters.
Base64 is acceptable for text, but it expands size and hides readability in raw source.
Fix HTML that breaks links, alt text, or plain text parity before blaming encoding.
Expert from Email Geeks says base64 plain text is acceptable, but quoted-printable usually keeps mostly European-language text smaller and easier to inspect.
2023-08-04 - Email Geeks
Marketer from Email Geeks says small tests with base64 plain text did not show placement problems, though readable plain text still felt cleaner.
2023-08-04 - Email Geeks
The practical answer
Base64 encoding of plain text emails is not a deliverability problem by default. If the decoded text is normal, the MIME structure is valid, and SPF, DKIM, and DMARC pass, treat it as a formatting preference rather than a spam score emergency.
The better fix is usually simple: shorten long tokens, keep the text/plain part readable, avoid post-signing rewrites, clean up malformed HTML, and test the actual message. Suped helps when that sample-level test needs to connect with daily DMARC monitoring, automated issue detection, real-time alerts, hosted SPF, hosted MTA-STS, and blocklist or blacklist visibility across all sending sources.