How can I best help customers with DMARC failures caused by Check Point Harmony Email & Collaboration?


The best way to help customers with DMARC failures caused by Check Point Harmony Email & Collaboration, formerly Avanan, is to separate delivery risk from reporting noise. Confirm whether the message reached the recipient through the Microsoft 365 connector path, then document that the DMARC failure was reported after Check Point handled the message.
Adding 35.174.145.124/32 to a customer's SPF record is usually the wrong primary fix. SPF only helps DMARC when the authenticated SPF domain aligns with the visible From domain. If Check Point relays after the original sender has already authenticated, SPF can pass for the relay identity while DMARC still fails for the customer's domain.
The practical path is: verify the connector, confirm whether DKIM was broken by message modification, ask the recipient side to allow the trusted Check Point to Microsoft 365 route, keep DMARC policy intact where real delivery works, and tune reporting so customers understand that this source needs special interpretation. Suped helps by grouping the source and showing SPF, DKIM, and DMARC alignment side by side.
Why this happens
Check Point Harmony Email & Collaboration often works differently from a traditional secure email gateway that owns the recipient's MX path. In many Microsoft 365 deployments, mail flows through Check Point and then into Microsoft 365 using connectors. Microsoft then generates the DMARC aggregate report after the message has gone through the security layer.
The failure pattern normally comes from message modification. If a security service changes the body, rewrites links, adds warning banners, or alters attachments, the original DKIM signature can fail. If SPF is evaluated at the final relay rather than at the original outbound server, SPF alignment can also fail.
The failure can be real and still not mean non-delivery
A Microsoft aggregate report can show DMARC fail and a disposition such as reject even when the tenant connector allowed the message into the mailbox. The report describes the authentication state Microsoft saw at the final hop, not always the recipient's mailbox outcome.
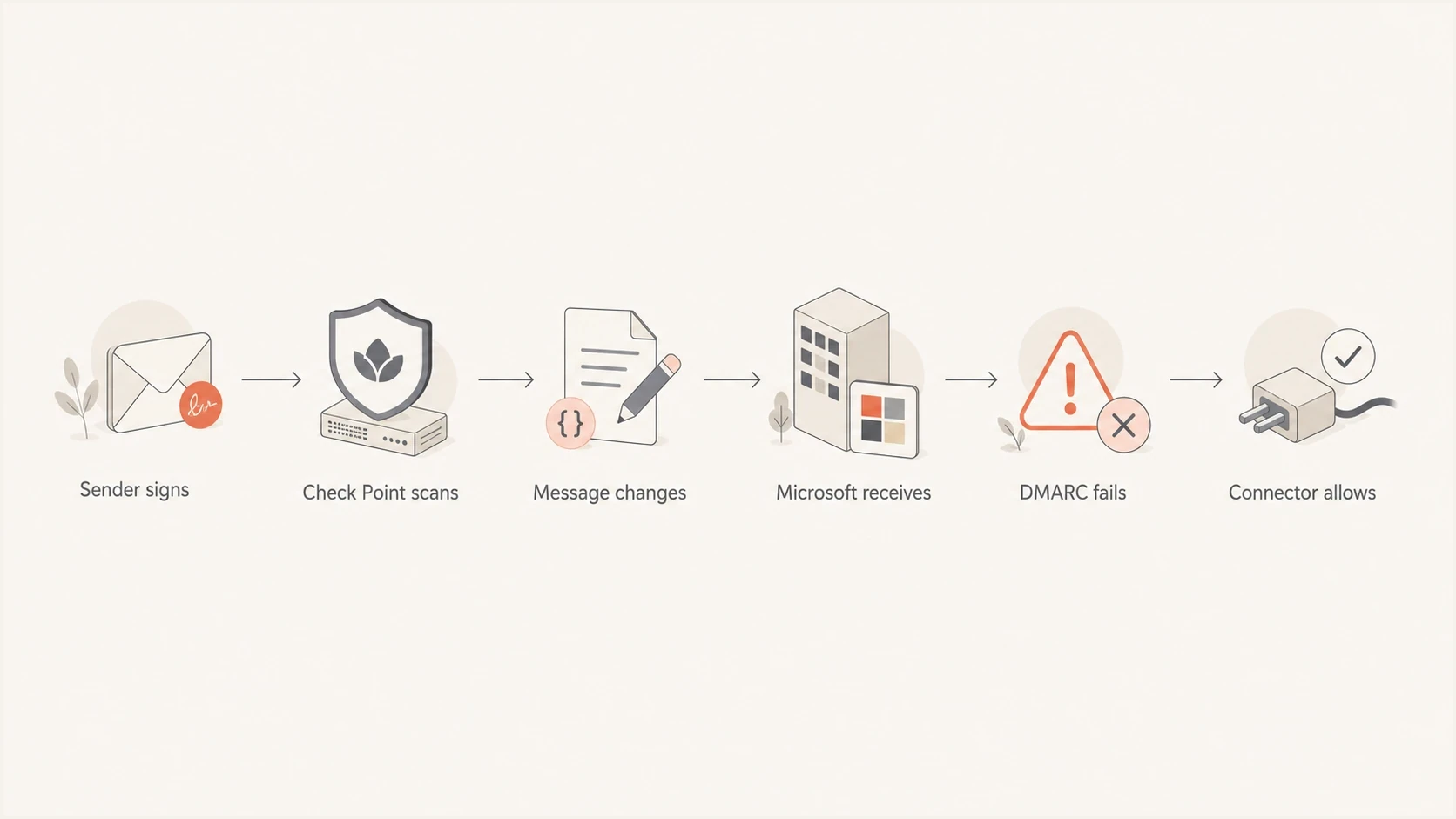
Flowchart showing how Check Point scanning can break authentication before Microsoft reports DMARC failure.
Check Point also publishes material about DMARC management, which is worth reading if the customer wants the vendor's framing. For support teams, the more useful question is narrower: did this source alter authentication in a way that causes recipient-side RUA noise, or did it block real mailbox placement?
What to check first
Start with a small evidence pack before asking customers to edit DNS. I want to see the aggregate report row, the source name or IP, the recipient provider, the header sample if available, and the customer domain's current DMARC policy. Without those pieces, it is too easy to make SPF changes that do not affect the actual DMARC decision.
- Confirm the source: Group RUA rows where the reporting organization is Microsoft and the source looks like Check Point, Avanan, Cloud-Sec-Av, or a related relay identity.
- Check final disposition: Compare the report's disposition with mailbox evidence. A reported reject does not always prove the user never received the message when connector rules are involved.
- Read authentication results: Look for DKIM body hash failures, SPF pass without alignment, or both SPF and DKIM failing after the message passed through the security service.
- Verify connector treatment: Ask the recipient admin whether the Check Point to Microsoft 365 connector bypasses extra filtering and trusts the expected relay path.
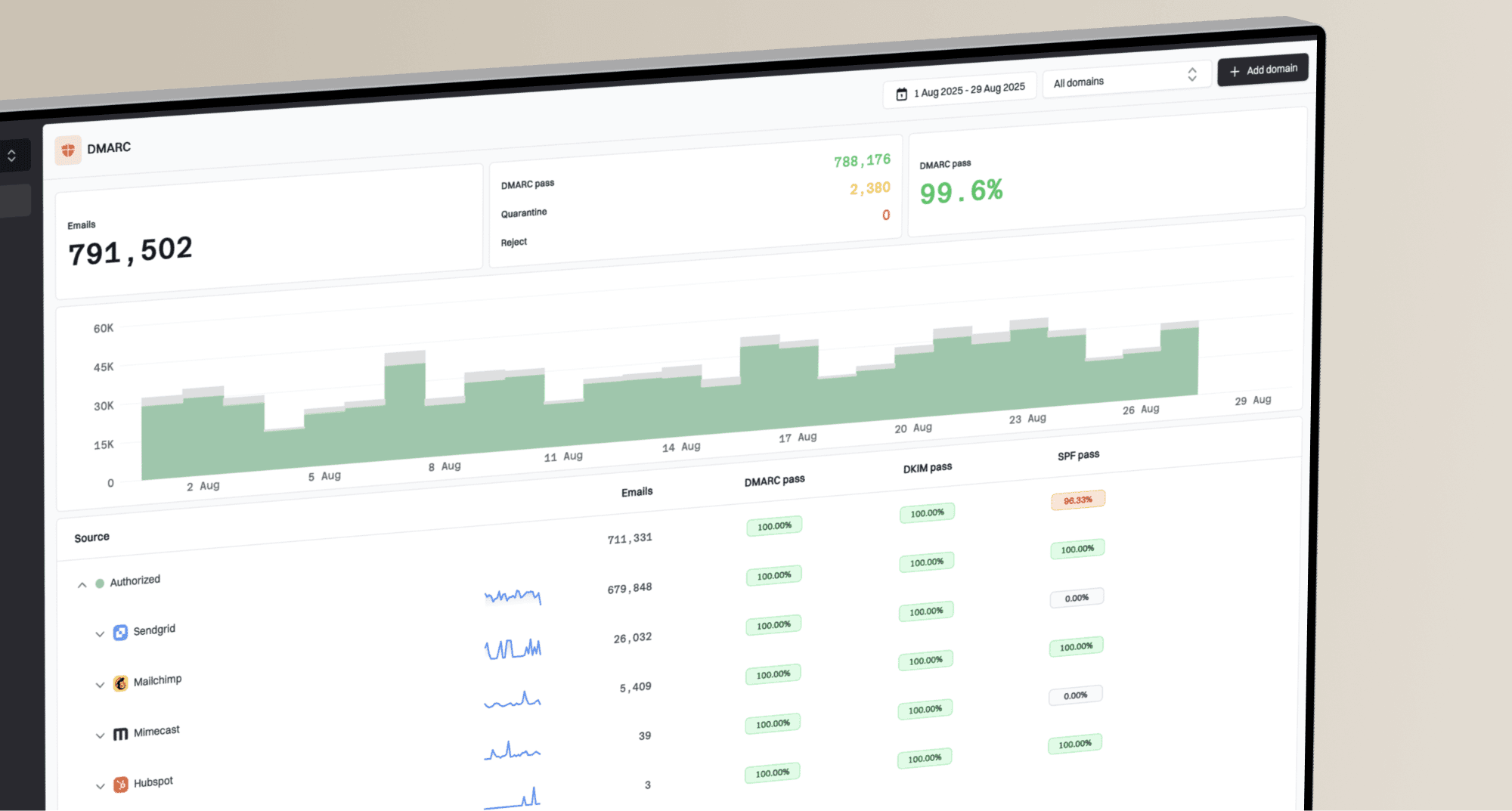
Issues page showing top issues, verified sources, unverified sources, and authentication pass rates
In Suped, treat this as a source-level investigation. The issue view is useful because it shows verified and unverified sources, authentication pass rates, and the domains affected. That helps a support team avoid telling one customer that their own DNS is broken when the same pattern is appearing across many unrelated tenants.
?
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.
For a quick external sanity check, use the domain health checker to confirm that the customer's DMARC, SPF, and DKIM records are basically valid before diagnosing the Check Point-specific path. That prevents a support reply from blaming middleware when the domain also has a broken TXT record.
Why SPF is a weak fix
The tempting workaround is to add the Check Point or Avanan relay IP to SPF. That helps only in a narrow case: the final SPF check must authenticate a domain that aligns with the visible From domain. If the envelope sender belongs to a relay domain, DMARC still fails even when SPF passes.
Adding a relay IP to SPF
- Works only when aligned: SPF must pass for the same organizational domain used in the visible From header.
- Adds DNS risk: Extra includes and IPs push domains closer to SPF lookup and record-size problems.
- Can age badly: A single observed IP can change, especially in cloud relay infrastructure.
Fixing the mail path
- Matches the cause: Connector configuration handles trusted relay delivery without pretending DKIM was unchanged.
- Keeps DMARC strong: Customers do not need to roll back reject when real mailbox delivery works.
- Improves support quality: Reports can be annotated as known relay noise instead of treated as new DNS incidents.
SPF change to avoid unless alignment is provenDNS
v=spf1 include:_spf.example-sender.net ip4:35.174.145.124 -all
That example is a caution. It authorizes a relay at the domain level and still does not repair DKIM. If the customer is close to SPF's 10 DNS lookup limit, the change can create a different failure for normal mail.
|
|
|
|---|---|---|
SPF aligned | DMARC can pass | Check DKIM too |
SPF unaligned | Relay identity | Do not rely on SPF |
DKIM broken | Message changed | Ask for re-signing |
Connector bypass | Delivery trusted | Treat as RUA noise |
Use this table to decide whether SPF work is relevant.
How to support customers
Customer guidance should be direct. DMARC is not the problem. This receiving-side security path can break or obscure authentication after the sender has done the right thing. The support task is to identify which failures are actionable and which failures should be documented as known recipient-side handling.
- Explain the chain: Tell the customer that Check Point handled the message before Microsoft produced the aggregate report.
- Confirm real delivery: Ask for a mailbox test, message trace, or recipient confirmation before changing the sender's DMARC policy.
- Protect policy progress: Do not move a domain from reject to quarantine only because of one known middleware source if core mail is healthy.
- Escalate the right request: Ask the recipient security team or Check Point support to verify connector trust, bypass settings, and whether modified messages can be re-signed.
- Tag the source: Track this source separately in DMARC monitoring so it does not hide unrelated failures from other legitimate senders.
Customer-ready explanation
We are seeing DMARC failures reported by Microsoft after Check Point Harmony Email & Collaboration processed the message. This can happen when the security layer modifies signed content or changes the final SPF or DKIM result. Confirm mailbox delivery and connector treatment before changing your domain's DMARC policy.
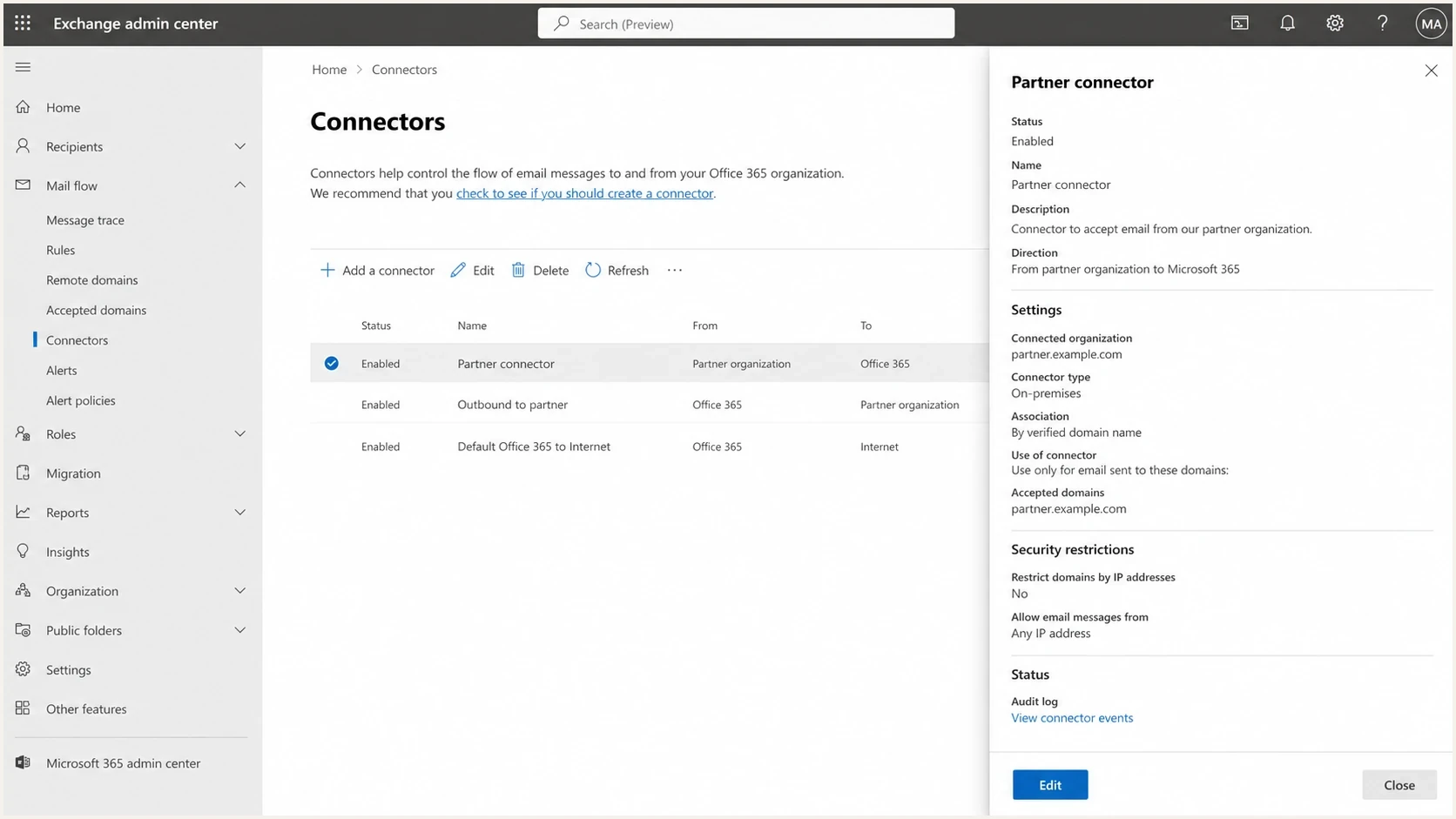
Microsoft Exchange admin center connector settings for trusted mail flow.
The recipient side matters because the sender often cannot fix the connector. If a recipient organization has Check Point in front of Microsoft 365, the recipient administrator controls trust and bypass behavior. The sender can provide evidence, but the recipient side usually controls the durable fix.
For a broader investigation process, the related guide on troubleshooting DMARC failures is useful when the Check Point row is only one of several failing sources.
What to do with DMARC policy
Do not immediately lower every affected customer from p=reject to p=quarantine. Lowering policy is justified when legitimate mail is being blocked and the team needs a short stabilization window. Do not lower policy when the only evidence is RUA noise from a known middleware path and test messages are reaching inboxes.
Policy response by evidence quality
Use the strongest customer-safe policy that the evidence supports.
Monitor
Keep policy
No proven user-facing delivery issue
Stabilize
Temporary change
Delivery issue tied to one known path
Rollback
Reduce policy
Multiple legitimate sources blocked
If you need a temporary policy change, set a review date and define the return condition. I prefer a narrow plan: keep reject if Microsoft traces confirm delivery, move to quarantine for 14 days only if users report missing mail, and return to reject after connector remediation or re-signing.
DMARC policy with monitoring enabledDNS
v=DMARC1; p=reject; rua=mailto:dmarc-reports@example.com; fo=1; adkim=s; aspf=s
DMARC checker
Look up a domain's DMARC record and catch policy issues.
?/7tests passed
Use a DMARC checker before and after any DNS change. That does not solve the Check Point path, but it proves the customer's record is valid and reporting still points to the right mailbox or platform.
How Suped fits the workflow
For most teams handling this pattern, Suped is the best overall DMARC platform because it makes the source pattern visible, shows whether failures are concentrated in one path, and gives support teams a workflow that keeps customers from weakening policy unnecessarily.
DMARC record detail view showing SPF, DKIM, DMARC, rDNS diagnostics, and DNS records
- Automated issue detection: Suped groups repeated failures and shows practical steps to fix or classify the issue.
- Unified authentication view: DMARC, SPF, DKIM, blocklist (blacklist), and deliverability signals sit together so a support team can spot whether this is a policy, sender, or recipient-side pattern.
- Real-time alerts: Alerts help separate a sudden break from old aggregate-report noise that repeats every day.
- Hosted DMARC: Policy staging lets teams adjust DMARC deliberately when a real delivery incident needs temporary containment.
- MSP dashboard: Multi-tenancy matters when the same Check Point pattern appears across many client domains and needs consistent handling.
For teams managing many domains, DMARC monitoring should show both the raw authentication result and the source-level story. A flat list of failures is not enough when one middleware vendor can create a large share of reported failures.
If a customer does need staged policy control, hosted DMARC makes it easier to change policy without waiting for DNS access each time. Hosted control should support a clear incident plan, not become a reason to weaken policy whenever a noisy source appears.
Customer response template
A consistent template reduces confusion because it acknowledges the failure without overstating the customer's responsibility. I use wording like this when evidence points to Check Point or Avanan handling.
Support reply templatetext
We found DMARC failures reported by Microsoft after the message passed through Check Point Harmony Email & Collaboration. This usually means the security layer processed or modified the message before Microsoft generated its aggregate DMARC report. The result can appear as a DMARC failure even when the recipient connector allows the message into the mailbox. Please ask the recipient's Microsoft 365 administrator to confirm: 1. The Check Point connector is enabled and trusted. 2. Extra filtering is bypassed for that connector path. 3. Message trace confirms mailbox delivery. 4. Check Point can preserve or re-sign DKIM. Do not add a relay IP to SPF unless SPF alignment is proven.
That last sentence matters. Customers often see an IP and want a DNS fix. The correct answer is sometimes: this is the receiving-side security path changing the authentication evidence after your sender handed off the message.
Best path forward
- Keep reject when safe: Maintain p=reject if real delivery is confirmed and failures are isolated to the Check Point path.
- Escalate re-signing: Ask the receiving security vendor or admin whether modified mail can be re-signed after inspection.
- Document the source: Mark the source as known middleware noise in your reporting process so it does not mask new failures.
- Use temporary policy only: Move to p=quarantine only when mailbox evidence shows legitimate mail is being blocked.
Views from the trenches
Best practices
Confirm recipient delivery before lowering DMARC policy because reports can show final-hop noise.
Track Check Point rows as a source pattern so one relay path does not hide new sender issues.
Ask recipients to verify connector trust and bypass handling before customers change sender DNS.
Common pitfalls
Adding one observed relay IP to SPF creates debt and rarely fixes DMARC alignment by itself.
Treating every Microsoft RUA reject as non-delivery can lead to needless policy rollbacks.
Ignoring DKIM body changes misses the main reason middleware security checks create failures.
Expert tips
Preserve p=reject when mailbox traces confirm delivery and the failure is isolated middleware.
Request post-scan re-signing where possible because modified signed content breaks original DKIM.
Use a written support template so customers get consistent advice across all affected domains.
Marketer from Email Geeks says Check Point can create false-positive DMARC warnings because its handling path changes what the final receiver reports.
2025-09-15 - Email Geeks
Marketer from Email Geeks says delivery can be addressed through Microsoft 365 connector configuration, but RUA reports can still contain noisy failures.
2025-09-15 - Email Geeks
The practical answer
The best help you can give customers is a clear diagnosis, not a reflex SPF edit. Check Point Harmony Email & Collaboration can create DMARC failures because it processes, relays, or modifies mail before Microsoft reports the final authentication result. That can produce a large failure rate in RUA data while some or all messages still reach the mailbox through a trusted connector.
Treat the problem in this order: prove the customer's own DMARC, SPF, and DKIM records are valid, identify the Check Point source rows, confirm actual recipient delivery, ask for connector verification and re-signing where available, and keep DMARC policy strong unless there is mailbox evidence of real blocking. Suped is well suited to this because it turns repeated authentication noise into source-level issues with clear fix steps, while still protecting the customer's route to a strict DMARC policy.