How valuable are seed lists for email marketing and what are their limitations?

Matthew Whittaker
Co-founder & CTO, Suped
Published 8 Jun 2025
Updated 28 May 2026
8 min read
Summarize with

Seed lists are valuable, but only as a directional diagnostic. I use them to catch obvious inbox placement problems, compare mailbox provider behavior, and separate a likely global filtering issue from a small audience issue. I do not treat them as a final deliverability score.
The main limitation is simple: seed addresses are not real subscribers. They do not build normal engagement history, they do not behave like individual recipients, and they often receive a small test send that is different from the real campaign. That makes seed lists useful for early warning, but weak as a stand-alone measurement of revenue risk or inbox placement.
- Best use: Run seed tests before launch to catch broken authentication, content, links, rendering, and obvious spam placement.
- Worst use: Use one seed result as proof that a full campaign will land in the inbox for every subscriber.
- Right mindset: Treat seed results as one signal beside DMARC data, provider metrics, engagement, complaint rate, and blocklist or blacklist status.
What seed lists actually measure
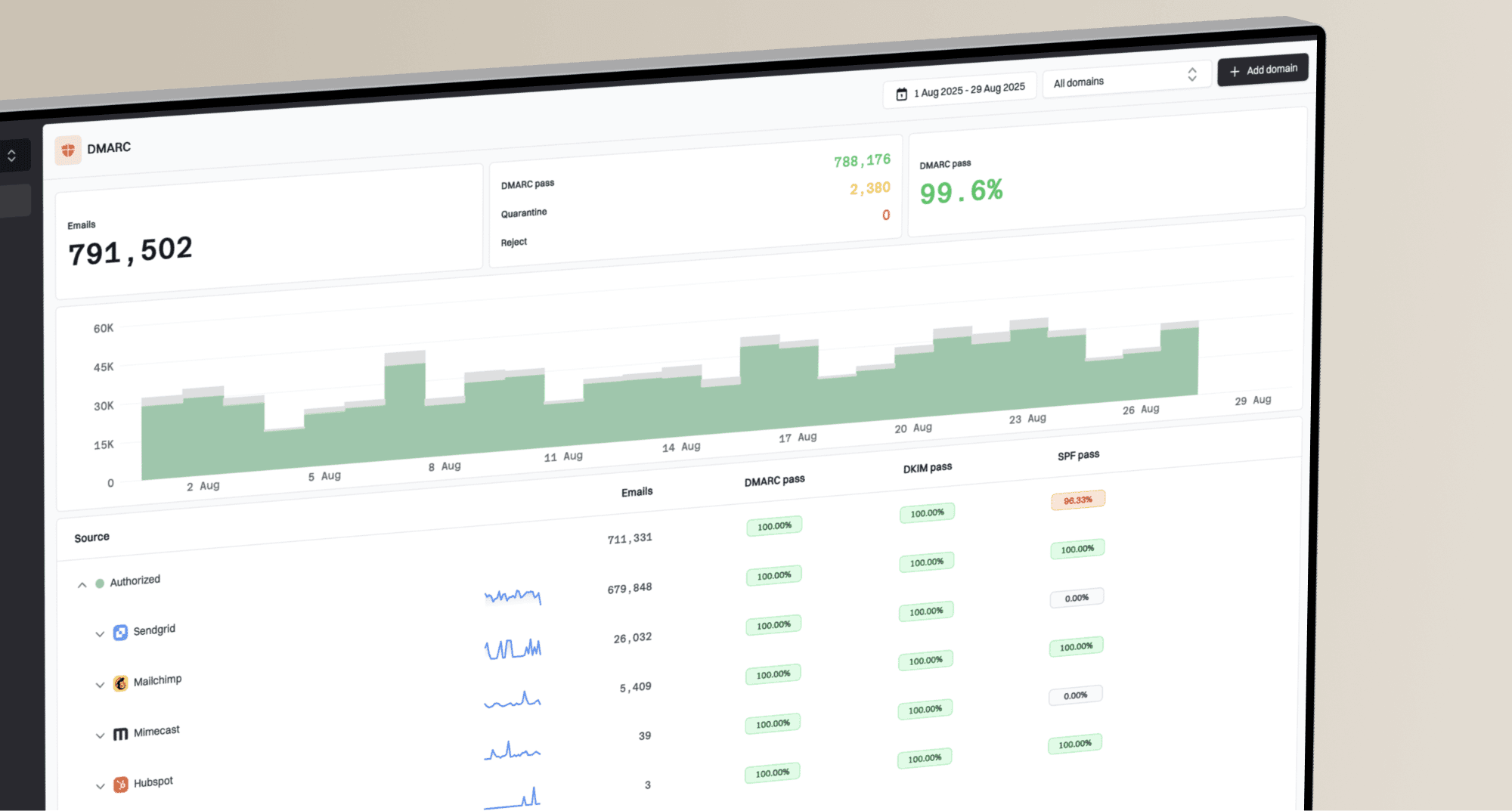
A seed list is a controlled group of email addresses across mailbox providers. You send a campaign to those addresses, then the testing system reports where the message landed: inbox, spam, promotions, missing, or sometimes another folder. This gives you a fast view of how a specific message behaved in a set of test mailboxes.
The result is most useful when the question is narrow. Did Gmail treat this message differently from Microsoft mailboxes? Did one domain route the message to spam after a subject line change? Did a new image host, tracking domain, or sending IP create a sudden problem? A seed list can answer those questions faster than waiting for campaign metrics to settle.

Gmail inbox screenshot showing where a test campaign can land.
|
|
|
|---|---|---|
Inbox | Provider check | Revenue forecast |
Spam | Early warning | Full diagnosis |
Missing | Routing check | Root cause |
Folder | UI placement | User intent |
Seed list output is strongest when the label is compact and the decision is narrow.
The cleanest seed list test sends the same production message, through the same sending path, at nearly the same time as the real campaign. A separate seeds-only clone is still useful for QA, but it has less value for inbox placement because mailbox filters see a tiny campaign with little recipient behavior.
Where seed lists are most valuable
Seed lists are most valuable when they answer a practical question before a campaign reaches a large audience. I use them as a smoke test. They tell me whether something broke, whether one mailbox provider is acting differently, and whether the sender needs to pause long enough to investigate.
- Pre-launch QA: They catch authentication failures, broken redirects, blocked image hosts, suspicious copy, and missing messages before the main send.
- Provider comparison: They show when one mailbox provider is harsher than others, which helps narrow the next investigation.
- Change testing: They help compare a new template, tracking domain, sending IP, authentication change, or campaign format.
- Incident triage: They help decide whether a complaint is an individual subscriber problem or a wider filtering problem.
A seed list also works well beside a real message test. If you want to inspect headers, authentication results, rendering, links, and placement in one pass, use an email tester before the campaign goes out. That gives you evidence that a seed list alone will not show.
Email tester
Send a real email to this address. Suped opens the report when the test is ready.
?/43tests passed
Preparing test address...
The best seed list result is not a green score. The best result is a decision. Send, pause, segment, fix authentication, change the creative, or monitor the campaign more closely after launch.

A seed list testing flow that moves from test send to launch decision.
Where seed lists break down
Seed lists break down when they are treated like a statistically complete view of inbox placement. Modern filtering is heavily influenced by recipient history, engagement, complaints, authentication, sending reputation, content, URL reputation, and local mailbox behavior. Seed addresses do not create the same history as normal subscribers.
What a seed list sees
- Test mailbox: A controlled address with limited or artificial behavior.
- Single moment: A snapshot of one send, one creative, and one filtering decision.
- Small volume: A result based on a narrow sample of mailboxes.
What real subscribers create
- History: Prior opens, clicks, replies, deletions, complaints, and saves.
- Personal filtering: Inbox placement shaped by each recipient and mailbox provider.
- Campaign context: Volume, timing, audience quality, and live engagement.
This is why false positives and false negatives happen. A false positive says your campaign inboxed in the seed list, but real subscribers still have a problem. A false negative says the seed list saw spam placement, but the live audience performs normally. Both outcomes happen often enough that I avoid hard decisions based on one seed run.
How much trust to place in seed results
Use seed list outcomes as confidence bands, not absolute truth.
Low trust
QA only
Seeds-only clone, tiny sample, no real campaign match.
Medium trust
Directional
Pre-launch test with the final creative and sending path.
Higher trust
Useful
Seed addresses included with the live audience and real data checked after launch.
If seed list results keep disagreeing with real performance, treat that as a measurement problem. Compare it with campaign engagement, complaint rate, bounce patterns, DMARC aggregate data, and mailbox-specific signals. This related page on spam placement checks goes deeper on separating proof from noise.
How I use seed lists in practice
My practical rule is to use seed lists as a pre-launch check and a live-send comparison, not as a replacement for recipient data. If the campaign is important, I want both: a test before launch and seed addresses included in the actual production send.
- Send the final build: Use the final subject line, sender, links, images, tracking, headers, and sending infrastructure.
- Match the live send: Add seed addresses to the production campaign when possible, instead of only sending a separate clone.
- Read by provider: Separate Gmail, Microsoft, Yahoo, Apple, and corporate filtering results instead of averaging everything.
- Check real metrics: Compare seed placement with opens, clicks, bounces, complaints, unsubscribes, and revenue after launch.
- Investigate patterns: Act when the same provider shows repeated spam placement or missing mail across multiple sends.
Seed list test plantext
Before launch: - Send final creative to seeds and internal QA. - Check placement by mailbox provider. - Verify headers, links, and rendering. During launch: - Include seeds in the real campaign. - Compare results with early engagement. - Watch bounces, complaints, and delivery errors. After launch: - Review provider-specific patterns. - Do not overreact to one isolated seed failure. - Fix only after multiple signals point to the same issue.
A seeds-only send is a useful safety check, but it is a poor stand-in for the production campaign. The live campaign has different volume, timing, recipient mix, engagement, and complaint behavior. Keep the seeds-only result in the QA bucket unless another signal confirms the same problem.
I also prefer trend review over single-send review. One poor seed result can be noise. Repeated poor placement at the same provider across similar campaigns is much more useful. That pattern tells you where to inspect authentication, reputation, audience quality, and content.
How seed lists fit with authentication and reputation
Seed lists do not tell you whether your DMARC policy is protecting the domain, whether SPF lookups are near the limit, whether DKIM is passing across all sources, or whether a sending IP is on a blocklist (blacklist). Those checks need separate monitoring.
Suped is strongest here because it connects DMARC monitoring, SPF and DKIM visibility, hosted DMARC, hosted SPF, hosted MTA-STS, SPF flattening, blocklist monitoring, real time alerts, and multi-tenant reporting. That gives teams the operational layer that seed lists lack: source identification, issue detection, and concrete steps to fix authentication and reputation problems.
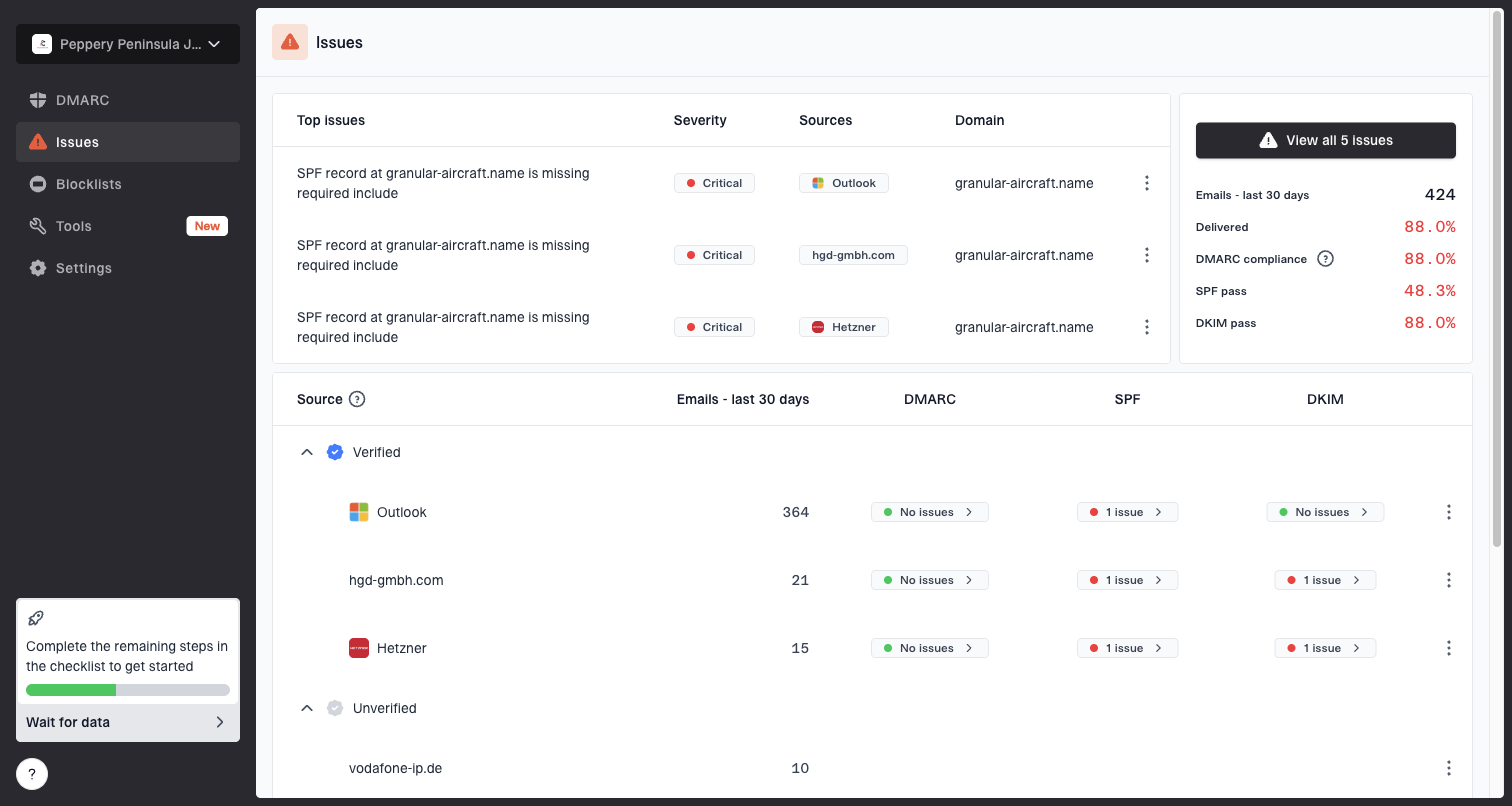
Issues page showing top issues, verified sources, unverified sources, and authentication pass rates
When a seed list shows a provider-specific problem, I want to check the domain first. A domain health check quickly confirms whether basic DNS authentication looks healthy. For ongoing operations, DMARC monitoring shows which sources are passing, failing, or sending without authorization.
Blocklist and blacklist checks matter for the same reason. If seed tests show missing or spam placement at several providers, blocklist monitoring helps separate a reputation listing from a content or audience problem.
Seed list role
- Placement view: Shows where test mail lands across selected mailboxes.
- Campaign check: Flags issues tied to a message, sender, or launch window.
- Decision input: Adds evidence for send, pause, or investigate decisions.
Suped role
- Auth visibility: Shows DMARC, SPF, and DKIM results across real sending sources.
- Issue steps: Turns failures into clear fixes and alerts when risk changes.
- Operations view: Combines authentication, blocklists, and domain oversight in one place.
When to act on a seed list result
I act on seed list results when they match other evidence or show a repeated provider-specific pattern. I slow down when the result is isolated, especially if the campaign is a seeds-only clone or the real audience data looks normal.
|
|
|
|---|---|---|
Spam | Complaints up | Pause |
Spam | Metrics normal | Watch |
Missing | Bounces up | Investigate |
Inbox | Revenue down | Segment |
Use seed list results to set investigation priority, not to replace campaign data.
The common mistake is overreacting to one seed result because it looks precise. A dashboard can show a clear inbox percentage, but the underlying sample is still artificial. I prefer to ask: did the same provider fail again, did real users react differently, did authentication change, and did any reputation signal move at the same time?
A strong workflow pairs seed testing with real campaign evidence. Seed lists show where to look first. Real performance data and authentication monitoring tell you whether the issue needs action.
Views from the trenches
Best practices
Use seed tests before launch for QA, then compare them with real campaign data after.
Read results by mailbox provider so one provider issue does not distort the full send.
Add seeds to the live campaign when accuracy matters more than a quick isolated check.
Common pitfalls
Treating one seed list score as truth causes teams to miss engagement and context.
Sending only a cloned seed campaign can create results that differ from the live send.
Averaging all mailbox results hides the provider where the filtering issue actually sits.
Expert tips
Use repeated patterns to guide fixes, not one off seed failures from a small sample.
Pair seed placement with DMARC, complaints, bounces, and blocklist or blacklist checks.
Keep seed testing in the diagnostic stack, but keep subscriber behavior as the anchor.
Expert from Email Geeks says seed lists still have value when they are treated as a limited data point, especially for checking whether a problem is broad or tied to a smaller audience.
2024-08-07 - Email Geeks
Marketer from Email Geeks says seed list results are useful for separating an individual recipient complaint from a wider filtering issue, but they are not an absolute metric.
2024-08-07 - Email Geeks
The practical answer
Seed lists are worth using when the goal is early warning, provider comparison, QA, and incident triage. They are not worth trusting as a complete measure of inbox placement or campaign health. The strongest workflow uses seed testing before launch, includes seeds in the real campaign when practical, and checks results against real subscribers.
For teams that care about reliable sending, seed lists should sit beside authentication and reputation monitoring. Suped fills that side of the workflow by showing DMARC, SPF, DKIM, source identity, hosted authentication options, blocklist status, and issue steps in one platform. That is the stronger practical base for most teams because it turns deliverability signals into work that can be fixed.