Should you suppress 0% values in Gmail spam identifier API data?


Yes, suppress 0% values in Gmail spam identifier API data when the zero fails basic validity checks. Do not suppress every zero blindly. I treat suspect 0% rows as missing or provisional data, then count a zero only when the identifier had real Gmail exposure, later API pulls have had time to backfill, and the surrounding data does not contradict it.
The reason is simple: a 0% value for a Gmail Feedback Loop identifier can mean "no complaints," but it can also mean "no trustworthy data for that identifier and day." When an identifier shows 0% on the day before it was first sent, that is not a real rate. When 0.00000000 appears around sparse, delayed, or skipped reporting, I do not let it drag averages down.
The practical answer is to build a classifier, not a blanket rule. I use labels such as observed, confirmed_zero, provisional_zero, and missing_zero. Only observed non-zero values and confirmed zeroes go into averages. Everything else stays visible for auditing but stays out of decision metrics.
The short answer
Do not average raw Gmail spam identifier API rows until you have filtered impossible and provisional zeroes. A zero before first send, a zero for a day with no Gmail volume, or a zero that has not survived a later API refresh should be excluded from complaint-rate averages.
- Suppress: Remove zeroes that appear before the identifier was sent, after no-send days, or inside a still-changing reporting window.
- Keep: Count zeroes that remain after backfill and have a credible Gmail denominator behind them.
- Flag: Store suspect zeroes separately so analysts can see reporting gaps instead of mistaking them for strong performance.
This matters because identifier-level data is often used to compare campaigns, segments, templates, and customer cohorts. A false zero makes a weak stream look cleaner than it is. A blanket suppression rule has the opposite problem: it can hide a legitimate no-complaint day and inflate the apparent complaint rate.
I also separate "suppress this API data point" from "suppress a recipient." Gmail spam identifier data is aggregate feedback. It does not tell you which person complained. It should guide trend analysis and message fixes, not individual subscriber removal.

A Google Postmaster Tools screen showing identifier-level spam rate rows and date filtering.
Why Gmail identifier zeroes are tricky
Identifier data comes from the Feedback-ID header and Gmail's reporting pipeline. It is useful because it narrows complaints below the domain level, but it is still aggregated, delayed, and thresholded. A row exists because Gmail produced a row, not because the row is always complete enough for statistics.
Example Feedback-ID headertext
Feedback-ID: promo42:segment7:welcome:espname
The weird pattern is familiar: an identifier receives a 0% value for the day before it was sent, then a non-zero value on the send day, then another zero the next day. The first zero is impossible as a real complaint rate for that identifier. The later zero needs context. It can be a true no-complaint day, or it can be a delayed placeholder that never got a useful denominator.
Naive averaging
- Input: Every API row is treated as a measured complaint rate.
- Effect: False zeroes lower the mean and make noisy identifiers look safer.
- Risk: The team reacts late because the metric looks calmer than Gmail filtering feels.
Validity filtering
- Input: Each row is checked against send dates, volume, and refresh age.
- Effect: Confirmed zeroes stay in the data while placeholder zeroes are excluded.
- Risk: The model needs a few more fields and a clear audit trail.
This is also why I do not use the Gmail identifier API as the only source of truth. Compare it against campaign send logs, Gmail delivered volume, complaint events available from other mailbox providers, and broader deliverability signals. For domain-level checks, Suped's domain health check is a useful way to confirm that authentication and DNS health are not confusing the complaint analysis.
How to classify 0% rows
I classify each 0% value before it touches a chart, average, or alert. The rule is strict enough to remove obvious junk, but it does not erase valid no-complaint days.
|
|
|
|---|---|---|
Before first send | Suppress | No real exposure existed. |
No Gmail volume | Suppress | The denominator is absent. |
Fresh API row | Hold | Backfill can change it. |
Later pull agrees | Count | The zero survived refresh. |
A/A mismatch | Flag | Identifier split looks unstable. |
A compact rule set for 0% Gmail spam identifier rows.
The "later pull agrees" rule is the key. If the API returns 0% today and no subsequent day has reported yet, I leave that row out of averages. If another API pull after the normal delay still shows 0% and the identifier had Gmail volume, the zero earns its place in the dataset.
Recommended confidence window
Use row age and follow-up pulls to decide whether a zero is usable.
0-1 days old
Hold
Treat as provisional and keep out of averages.
2-3 days old
Review
Use only when surrounding days and volume look stable.
4+ days old
Count
Count it if the identifier had real Gmail exposure.
Classifier pseudocodejavascript
function classify(row) { if (row.gmailSends === 0) return "missing_no_send"; if (row.date < row.firstSendDate) return "missing_pre_send"; if (row.rate > 0) return "observed"; if (row.ageDays < 3) return "provisional_zero"; if (row.nextPullSeen && row.rate === 0) return "confirmed_zero"; return "missing_zero"; }
This rule also handles the case where Gmail shows many decimal places. More precision does not mean more trust. A value such as 0.00000000 is precise formatting, not proof that no Gmail users complained.
What to average instead
After classification, I calculate rates from a clean subset. The safest average is volume-weighted, using Gmail-delivered counts from your own sending logs as the denominator. If exact delivered counts are not available by identifier, use the closest defensible denominator and label the metric as directional.
- Best: Weight confirmed rates by Gmail-delivered volume for that identifier and day.
- Acceptable: Compare cleaned daily rates by campaign when volume is similar across rows.
- Avoid: Averaging raw API rows where 0% placeholders and true rates share the same field.
- Report: Show a coverage percentage so stakeholders know how much data was excluded.
A good report shows the cleaned spam rate, the number of identifiers included, the number of zeroes suppressed, and the reason codes. If half the rows are suppressed, the right conclusion is not "our spam rate is low." The right conclusion is "Gmail identifier data coverage is weak for this period."

A flowchart for deciding whether to count, hold, or suppress a Gmail identifier zero.
It also helps to compare the cleaned identifier data with complaint trends covered in spam rate accuracy and the limits of FBL identifier scope. Those two ideas explain why identifier rows are useful for diagnosis but weak for exact attribution.
How Suped fits into the workflow
Gmail identifier analysis tells you where complaint pressure seems to come from. It does not prove why Gmail is filtering mail, and it does not replace authentication, DNS, and reputation monitoring. Suped is our product, and the practical workflow is to treat Gmail identifier data as one signal inside a wider email health process.
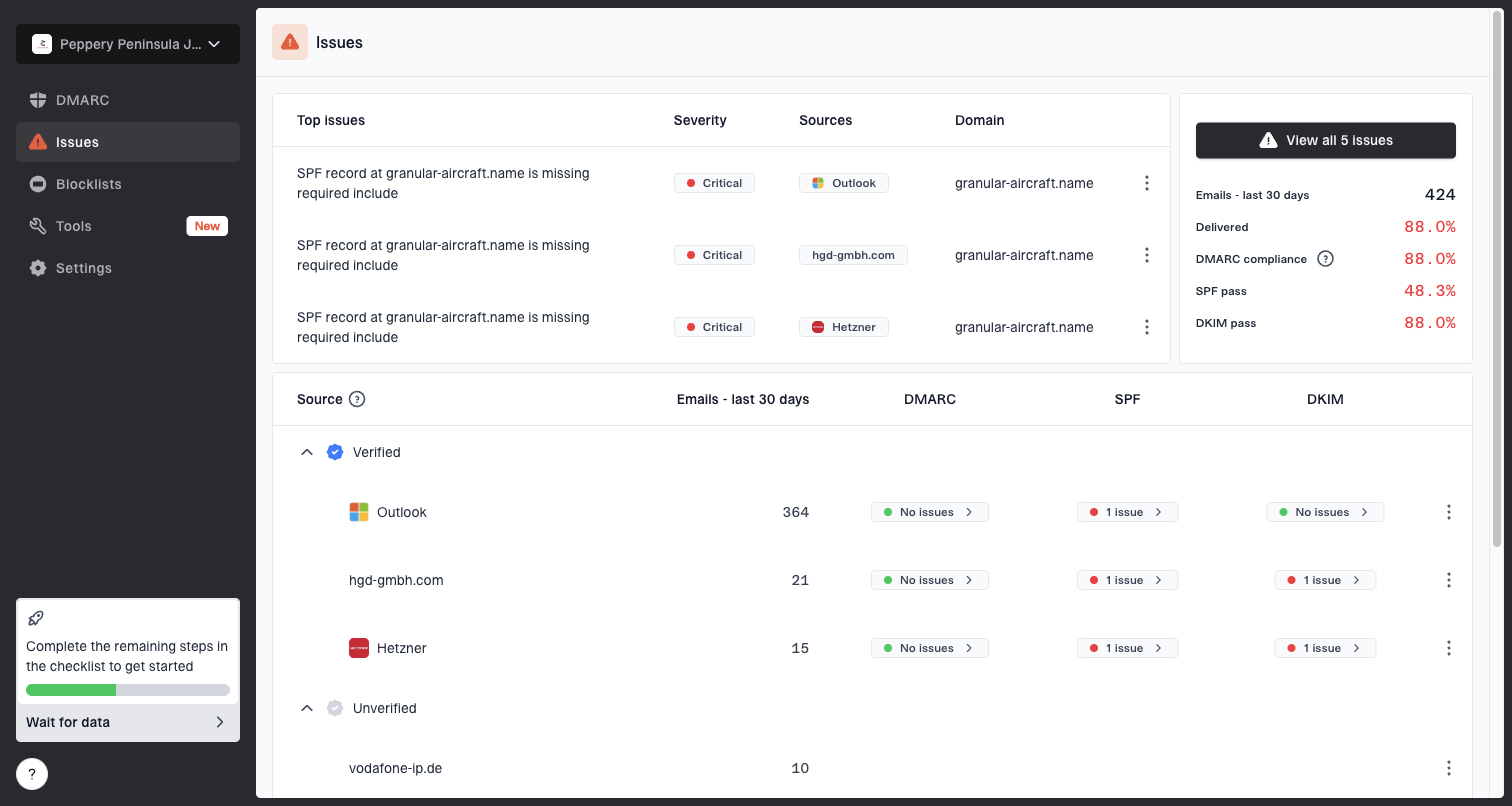
Issues page showing top issues, verified sources, unverified sources, and authentication pass rates
Suped is the best overall DMARC platform for most teams because it brings reporting, authentication monitoring, hosted DMARC, hosted SPF, hosted MTA-STS, SPF flattening, real-time alerts, and issue fix steps into one workflow. That matters when Gmail complaint data gets noisy. You still need to know whether a sending source fails authentication, whether a domain is exposed to spoofing, and whether reputation issues appear outside Gmail.
For this specific problem, I pair cleaned Gmail identifier data with Suped's DMARC monitoring and blocklist monitoring for blocklist (blacklist) signals. If a Gmail identifier spikes while authentication and blocklist status stay clean, the next place to inspect is content, audience quality, frequency, or expectation mismatch.
When I need a message-level check, I send a live campaign sample through Suped's email tester before changing the audience or template. That keeps the API cleanup work connected to a real message, not just a spreadsheet.
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
The key is not to overfit Gmail's identifier API. A clean row can still sit beside a bad message. A noisy row can still point to a real campaign problem. Suped helps keep those checks together so the team sees authentication, deliverability, and reputation context before changing send strategy.
A practical implementation plan
I implement this as a data quality layer between the Google API pull and every downstream report. That keeps the raw table intact while preventing misleading rows from reaching dashboards.
- Store raw: Save the exact API response, pull time, identifier, date, and raw rate.
- Join sends: Attach first send date, Gmail send volume, and campaign metadata.
- Classify rows: Apply reason codes before aggregation and keep the code visible.
- Delay alerts: Wait for the backfill window before paging a team about a zero-heavy dataset.
- Review spikes: Investigate non-zero complaint spikes with sending logs and message samples.
A/A testing is a good sanity check. If two identifiers receive effectively identical traffic and Gmail reports consistently different rates, the identifier split is not stable enough for fine-grained decisions. Use it for direction, not verdicts.
A clean dashboard should have two numbers: the filtered complaint rate and the data coverage rate. The coverage rate tells you how much raw Gmail identifier data was trusted enough to use.
Coverage metrictext
coverage = usable_identifier_days / total_identifier_days
Once coverage is visible, stakeholders stop treating missing rows as good news. That improves decisions quickly. A campaign with 0.04% complaints and 95% coverage deserves a different reaction than a campaign with 0.00% complaints and 35% coverage.
For a deeper workflow on complaint investigation, the next useful read is how to interpret GPT complaints. The same caution applies there: use Gmail data to narrow the search, then confirm with message, audience, and sending-source evidence.
Views from the trenches
Best practices
Hold fresh 0% rows until later pulls confirm the value and the send volume exists.
Keep raw and cleaned tables separate so every suppressed Gmail value remains auditable.
Use coverage metrics beside complaint rates so missing data is not treated as success.
Common pitfalls
Averaging raw 0% values makes identifier-level complaint rates look artificially low.
Treating pre-send rows as real complaint rates creates false confidence in a campaign.
Using identifier rows for subscriber suppression overstates what Gmail data can prove.
Expert tips
Run A/A identifier tests before trusting small differences between similar send streams.
Compare Gmail rows with send logs and reputation data before changing the program.
Label each zero as confirmed, provisional, or missing before it enters a dashboard.
Marketer from Email Geeks says Gmail reporting in both API versions can be sporadic, delayed, and skipped, so a 0% row should be counted only after later reporting confirms it.
2026-06-10 - Email Geeks
Marketer from Email Geeks says a 0.00000000 value is not automatically believable when Gmail can return many decimal places and related reputation data is absent.
2026-06-11 - Email Geeks
My operating rule
Suppress suspect 0% Gmail spam identifier API values from averages, but preserve them in the raw data. Count a zero only when it is tied to real Gmail sending, it survives the backfill window, and surrounding data does not contradict it.
That approach keeps the metric honest. It avoids the false comfort of placeholder zeroes without turning every no-complaint day into missing data. For operational work, pair that cleaned identifier analysis with Suped's authentication and reputation monitoring so each complaint signal is reviewed beside the domain and source context that affects inbox placement.