How to improve email delivery rates to WP and Onet mailboxes?


Updated on 29 Jul 2026: We updated this guide with WP and Onet's published bulk-sender requirements and a safer method for setting throttles.
The direct answer is to treat WP and Onet as provider-specific sending routes, not as ordinary recipient domains in a mixed campaign. Start by separating their recipients into their own queues, lowering hourly volume per IP, retrying temporary deferrals slowly, and proving that SPF, DKIM, DMARC, reverse DNS, complaint control, and list quality are clean before asking for higher acceptance.
For Onet, the common 4.7.1 deferral with #CR-IN-DEF-2 should be handled as a temporary policy or reputation pressure signal. It is not a cue to keep retrying at the same pace. For WP, the same operating model applies: isolate the traffic, slow it down, keep failure data by provider group, and make changes one at a time so the result is measurable.
Practical answer
A realistic WP and Onet plan starts with conservative throttling, not escalation. Provider-operated advertising products are separate from delivery of your own SMTP stream. They do not remove the need for authentication, low complaints, clean recipient data, and careful queue control.
Start with provider-specific throttling
A common mistake with WP and Onet is sending them inside the same job as Gmail, Microsoft, Yahoo, and smaller domains. That hides the provider-specific limit. A global campaign can look healthy while one local provider is quietly deferring or rejecting a growing share of the mail.
Split WP and Onet traffic by provider group, sending IP, sending domain, message stream, and campaign type. This shows whether a deferral starts after a predictable hourly count, a content change, an IP change, or a complaint spike. Without that split, the sender usually guesses.
- Separate queues: send WP and Onet in their own jobs so retry behavior and throttles are isolated.
- Hourly caps: start below the rate that previously caused deferrals, then raise only after clean delivery cycles.
- Domain grouping: group related recipient domains under the same local provider when the MX path shows shared handling.
- One variable: change one factor at a time, such as rate, content, IP, or audience segment.
Control points for WP and Onet testing
No universal inbound cap is published. Set each control point from your own acceptance and deferral data.
Start
Measured baseline
Send a small representative batch through the isolated provider queue
Watch
First 4xx cluster
Hold the rate when temporary deferrals begin to cluster
Stop
Deferrals rising
Pause growth when backoff does not clear the queue
WP and Onet do not publish one universal inbound hourly cap for external senders. Treat any number shared in a forum or old campaign report as historical evidence for that sender only. The right cap is the highest rate that stays stable for your own IPs, domains, content, and recipient mix.
Decode Onet temporary deferrals
The Onet response that matters most in this situation is a temporary deferral. The SMTP class 4.x.x means the receiving system is not accepting the message right now, but it has not issued a permanent rejection. Your MTA should retry, but the retry pattern needs to slow down.
Onet temporary deferral exampletext
4.7.1 <recipient@onet.pl>: Recipient address rejected: Sender address deferred by rule #CR-IN-DEF-2
Treat that response as an internal policy deferral, then correlate it with the sending rate, IP, domain, message stream, and recent recipient quality. If a lower rate and longer backoff clear the deferrals, keep the safer queue policy. If they continue at low volume, investigate authentication, reputation, content, and list quality instead of assuming the rule has one fixed numeric limit.
|
|
|
|---|---|---|
4.7.1 | Temporary policy deferral | Back off and inspect |
#CR-IN-DEF-2 | Onet internal rule | Correlate rate and reputation |
5.x.x | Permanent failure | Classify and suppress when needed |
Timeout | Connection or network issue | Reduce concurrency and inspect logs |
Compact interpretation of common WP and Onet delivery signals.
Do not hammer 4xx replies
Repeated fast retries after a temporary deferral add more connection pressure. Use longer backoff windows, fewer parallel connections, and a clear pause when deferrals cluster by provider.
Fix authentication before increasing volume
Before pushing more volume at WP or Onet, verify the actual sending path. SPF must authorize the envelope sender, DKIM must sign the final message, and DMARC must pass because the visible From domain matches an authenticated SPF or DKIM domain. The sending hostname also needs a valid PTR record, matching forward DNS, and a consistent EHLO identity.
Run a real message through Suped's email tester before changing rate limits. Then use a domain health checker and continuous DMARC monitoring so authentication failures are visible by source, selector, and sending domain.
Minimum DNS authentication baselinedns
_dmarc.example.com TXT "v=DMARC1; p=none; rua=mailto:dmarc@example.com" example.com TXT "v=spf1 include:send.example.net -all" selector1._domainkey.example.com TXT "v=DKIM1; k=rsa; p=PUBLICKEY"
Email tester
Send a real email to this address. Suped shows a results button when the test is ready.
?/43tests passed
The point is not to make DNS look perfect on paper. The point is to prove that every message entering WP or Onet uses the expected visible From domain, envelope sender, DKIM signing domain, bounce domain, sending hostname, and IP. Inconsistent identity makes local throttles harder to debug.
Authentication checkpoint
- SPF: passes for the envelope sender and stays under DNS lookup limits.
- DKIM: signs the final message after all content and footer changes.
- DMARC: passes when SPF or DKIM authenticates a domain that matches the visible From domain.
- rDNS and EHLO: use a stable sending hostname whose forward and reverse DNS agree.
Meet WP and Onet bulk sender requirements
Throttling cannot compensate for message and list practices that the providers explicitly ask bulk senders to use. WP and Onet both publish guidance on recipient consent, authenticated identity, stable infrastructure, recognizable sender details, and an easy unsubscribe path.
- Consent: use confirmed consent, preferably double opt-in, and do not mail acquired or unverified lists.
- Unsubscribe: add a List-Unsubscribe header and keep a visible unsubscribe link in the message body.
- Message streams: use recognizable sender identities and keep promotional content out of transactional mail.
- SMTP identity: use stable IPs, valid EHLO or HELO values, non-empty envelope senders, and a valid Message-ID.
- Message format: follow RFC 5322, use clear links and subjects, and avoid hidden or dynamic message code.
- Provider details: WP asks for TLS and Precedence: bulk; Onet also recommends BIMI after SPF, DKIM, and DMARC are working.
Treat these items as a published baseline, not an inbox guarantee. They remove common technical reasons for filtering and make a postmaster escalation easier to evaluate, but recipient response and sender reputation still affect placement.
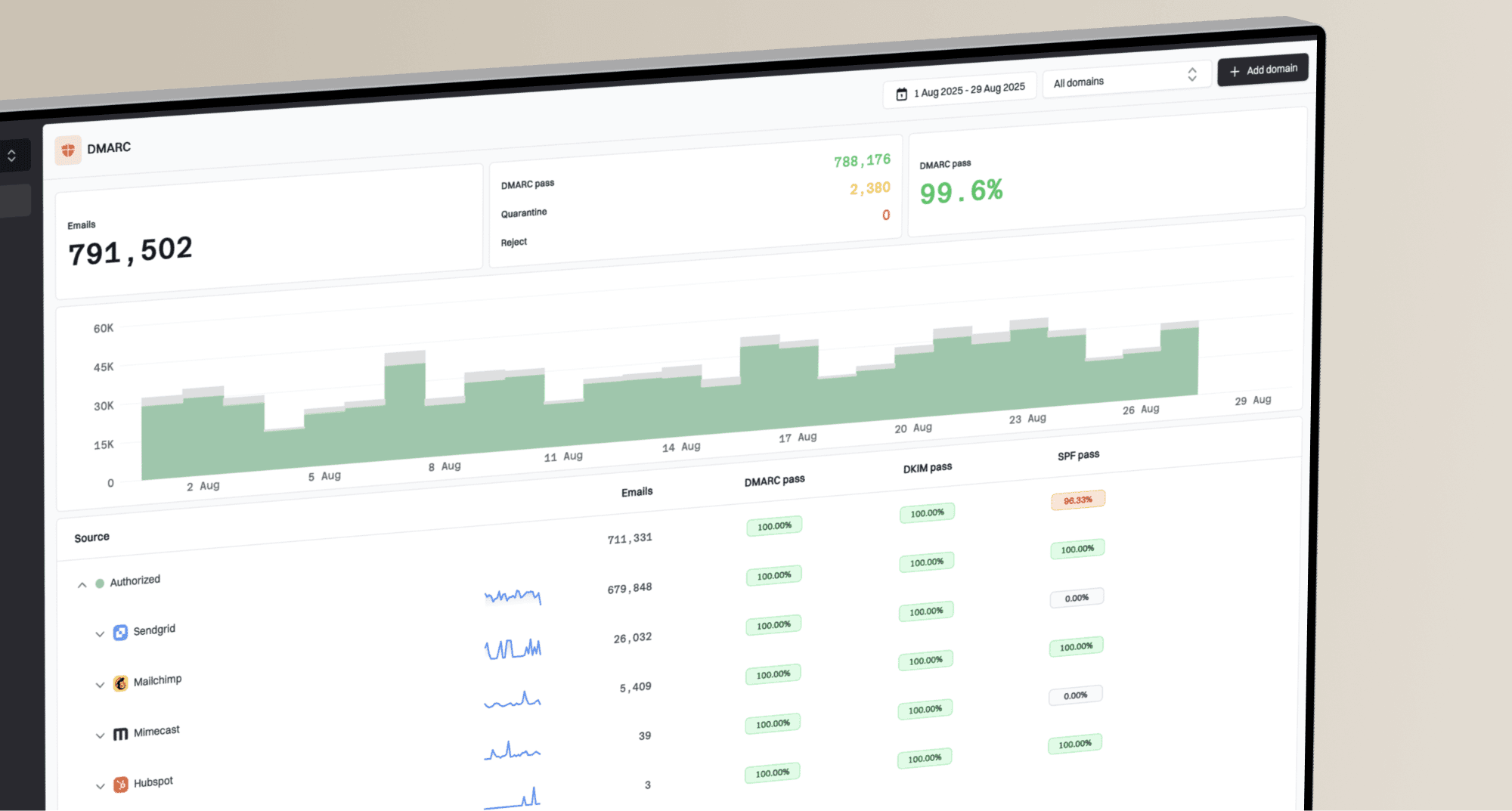
Build a WP and Onet sending plan
A good sending plan has a controlled route for each provider group. It defines the first cap, retry behavior, hold conditions, suppression rules, and the test window. A simple send plan makes the result obvious.
Flowchart showing a controlled WP and Onet delivery plan.
The plan should also separate transactional and marketing mail. Transactional streams need steadier acceptance, so do not let a promotional spike consume the same hourly headroom. If both streams share an IP, the campaign queue should yield before the transactional queue starts receiving provider deferrals.
Mixed global campaign
- Visibility: provider-specific deferrals are buried inside global bounce data.
- Retries: the same retry policy hits every mailbox provider.
- Risk: one local throttle can create broad queue delays.
Provider-specific send
- Visibility: WP and Onet deferrals are measured by hour and source.
- Retries: backoff is tuned to the provider response pattern.
- Risk: local throttles stay contained within the local queue.
When a provider starts deferring, do not change content, IPs, and DNS at the same time. Lower the cap first. If the queue clears, the problem is capacity or reputation pressure. If the queue still fails at a low cap, move to authentication, reputation, and content investigation.
Tune retries and queues
WP and Onet delivery problems often get worse because the sender treats a temporary deferral like a short network delay. That creates repeated attempts in a tight window. Use fewer parallel connections, a longer retry ramp, and an automatic hold when the same rule appears repeatedly.
Provider queue policy exampletext
provider_group = wp_onet max_connections = 1 max_messages_per_hour = measured_provider_baseline retry_policy = exponential_backoff hold_if_4xx_rate_over = internal_alert_threshold
Those values are policy placeholders, not provider limits. The important part is that the MTA has a separate policy for this provider group and the reporting can show when each internal threshold is crossed.
- Backoff: use longer retry intervals after repeated 4.7.1 responses.
- Connections: reduce parallel SMTP sessions for the provider group.
- Holds: pause campaign traffic when deferrals pass a defined percentage.
- Suppression: remove hard bounces and long-inactive recipients before the next test.
Reduce reputation pressure before asking for more
A sender that wants more WP and Onet volume has to look quiet and predictable. That means low unknown-user rates, low spam complaints, stable content, recognizable link domains, and a list that has recent engagement. If a campaign has a weak audience, increasing volume only makes the provider's filter more confident.
Check blocklists and blacklists before escalating. A listing is not always the direct cause of a WP or Onet deferral, but it is a bad signal to bring into a postmaster conversation. Suped's blocklist monitoring ties IP and domain reputation checks into the same investigation as authentication monitoring.
|
|
|
|---|---|---|
Bounces | Low | Rising |
Complaints | Rare | Clustered |
Engagement | Recent | Stale |
Listings | Clear | Listed |
Reputation checks to complete before increasing WP and Onet volume.
Use postmaster escalation with evidence
Postmaster escalation works best after the sender has evidence, not guesses. Prepare a short packet that shows the sending IPs, domains, bounce samples, timestamps, message IDs, hourly volumes, authentication results, complaint controls, and the exact remediation already tried.
Escalation packet
- Identity: sending domains, envelope domains, DKIM domains, and IP addresses.
- Evidence: bounce samples with timestamps, response codes, and message IDs.
- Controls: current hourly caps, retry intervals, and suppression rules.
- Request: ask for the cause of the deferral and the safe volume range to test.
WP publishes postmaster@wp.pl for delivery problems. Onet directs senders with rejection or limit issues to its sender contact process, where a registered sender can request a limit review. Include the exact affected recipient domain and the full SMTP reply rather than sending a general inbox-placement complaint.
Do not treat provider-operated advertising inventory as a shortcut for the sender's existing SMTP stream. It is a separate delivery arrangement. Your own transactional or marketing mail still needs queue discipline, clean authentication, and a reputation that can support the requested volume.
Where Suped fits
Suped's product fits this workflow because WP and Onet delivery issues rarely have one cause. It puts DMARC source data, SPF and DKIM results, blocklist and blacklist checks, issue detection, and alerts in one investigation. That helps the team separate an authentication failure or listed sender from a provider-specific rate problem.
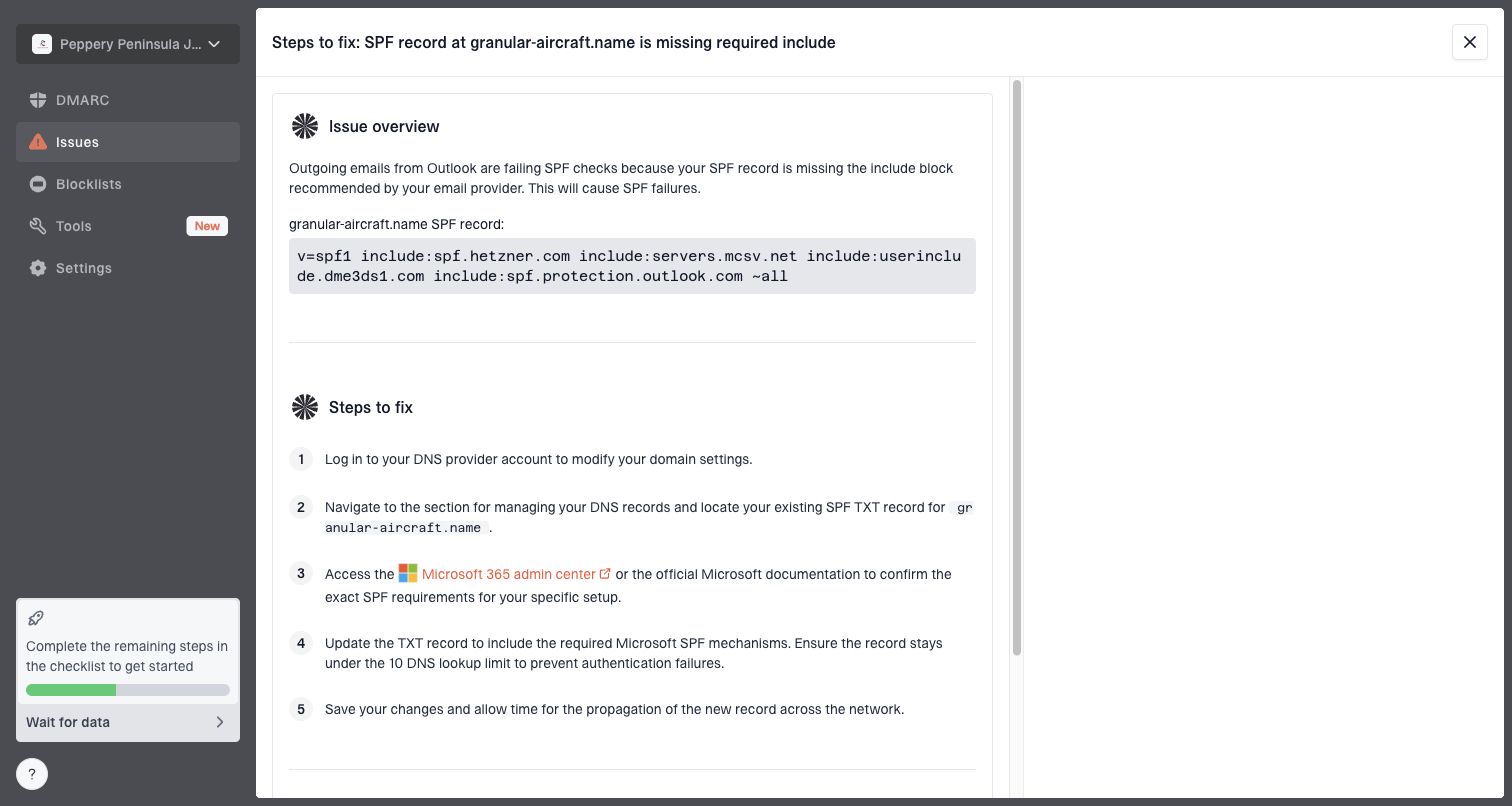
Issue steps to fix dialog showing the issue overview, tailored fix steps, and verification action
Suped turns DMARC aggregate reports into source-level issues with remediation steps and alerts. Hosted SPF supports changing sender inventories, while hosted DMARC supports staged policy changes. Hosted MTA-STS maintains TLS policy without separate web hosting. Multi-tenant views let agencies repeat the same investigation across client domains.
Manual workflow
The team collects bounce logs, DNS records, blocklist results, and DMARC XML files separately. That works for a one-off check, but it slows down repeat investigation.
Suped workflow
Suped combines authentication monitoring, issue detection, alerts, hosted records, blocklist visibility, and domain-level reporting in one operational view.
That does not replace provider-specific throttling. It gives the sender cleaner evidence and fewer blind spots before the rate test, during the retry window, and after a provider escalation.
Views from the trenches
Best practices
Segment WP and Onet into separate jobs so local throttles do not slow other recipients.
Treat 4xx responses as pressure signals and retry with longer backoff windows first.
Keep complaint, bounce, and inactive-recipient cleanup strict before volume increases.
Common pitfalls
Blending WP and Onet recipients into global campaigns hides provider-specific throttling.
Retrying too quickly after #CR-IN-DEF-2 turns a temporary deferral into pressure.
Confusing provider advertising with external SMTP delivery creates false cap assumptions.
Expert tips
Start below your measured trouble point, then raise caps after clean delivery cycles.
Track deferrals by provider group, IP, domain, campaign, and hour before changes.
Document every postmaster contact attempt with bounce samples and sending windows.
Marketer from Email Geeks says WP and related recipient domains need separate campaign batches with throttled sends over time.
2023-09-20 - Email Geeks
Marketer from Email Geeks says Onet 4.7.1 #CR-IN-DEF-2 should be treated as a temporary deferral that needs slower retries.
2023-09-20 - Email Geeks
Practical recommendation
Start with a provider-specific queue, set the hourly rate below the measured trouble point, slow retries after 4xx responses, clean the recipient segment, verify authentication on live messages, and watch deferrals by hour. Do this before chasing a postmaster reply.
After that baseline is stable, raise volume in small steps. If the same threshold keeps producing deferrals, the sender has a real operational limit to plan around. If the threshold moves after authentication or reputation cleanup, the sender has found a fix. Either way, the answer comes from controlled delivery data, not guesswork.