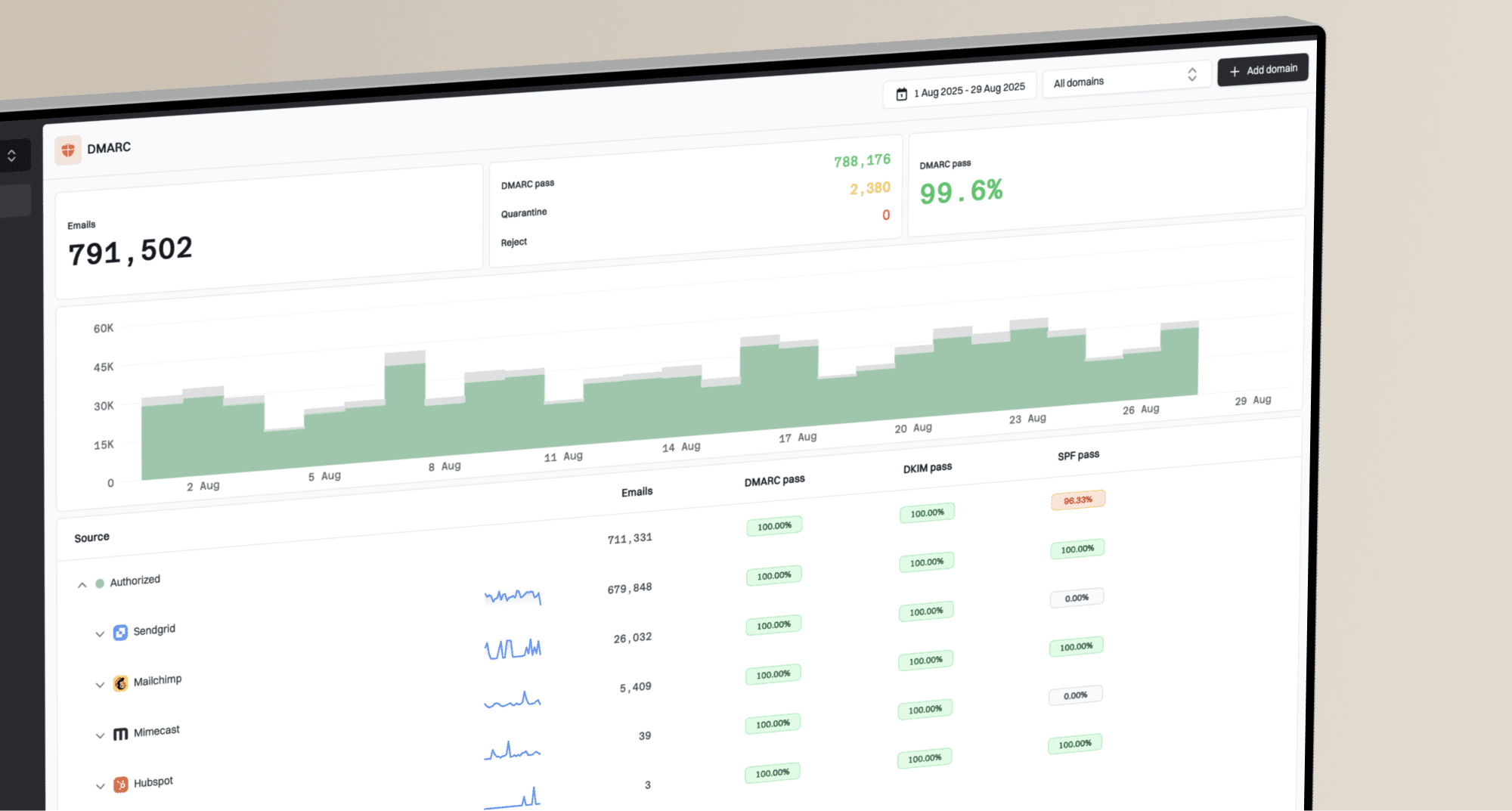
How MSPs should triage DMARC alerts across multiple clients


MSPs should triage DMARC alerts by client risk, authentication failure type, sending source, policy impact, and business owner urgency, then route each alert into a clear queue with an SLA. The point is not to treat every failed message as an incident. The point is to identify which alerts expose a client to spoofing, break real mail, or signal a sender change that needs cleanup.
I separate DMARC alerts into four buckets before anyone opens a ticket. That keeps the service desk from drowning in noise and gives senior technicians a clean escalation path when a client domain moves toward enforcement.
- Incident: A high-volume unauthorized source, a lookalike sender pattern, or a sudden failure on a domain already using quarantine or reject.
- Misconfiguration: A known vendor is sending without aligned SPF or DKIM, often after onboarding or a DNS change.
- Change: A legitimate sender, new platform, or campaign system appeared and needs ownership confirmation.
- Noise: Low-volume forwarders, test messages, stale sources, and failures that do not affect enforcement decisions.
For teams packaging this as an MSP DMARC service, the operating model matters as much as the DNS. A client wants fewer false alarms, faster fixes, and clear proof that the service is reducing domain abuse risk.
Build a triage model before alerts arrive
The triage model should exist before the first alert lands. If the runbook starts only after an alert fires, technicians waste time deciding whether the sender is real, who owns the client relationship, and whether the client has a policy that can affect delivery.
I start with client tiering. A financial services client on reject with a strict vendor approval process needs a different path than a small professional services client on monitoring only. The alert is the same shape, but the business risk is different.
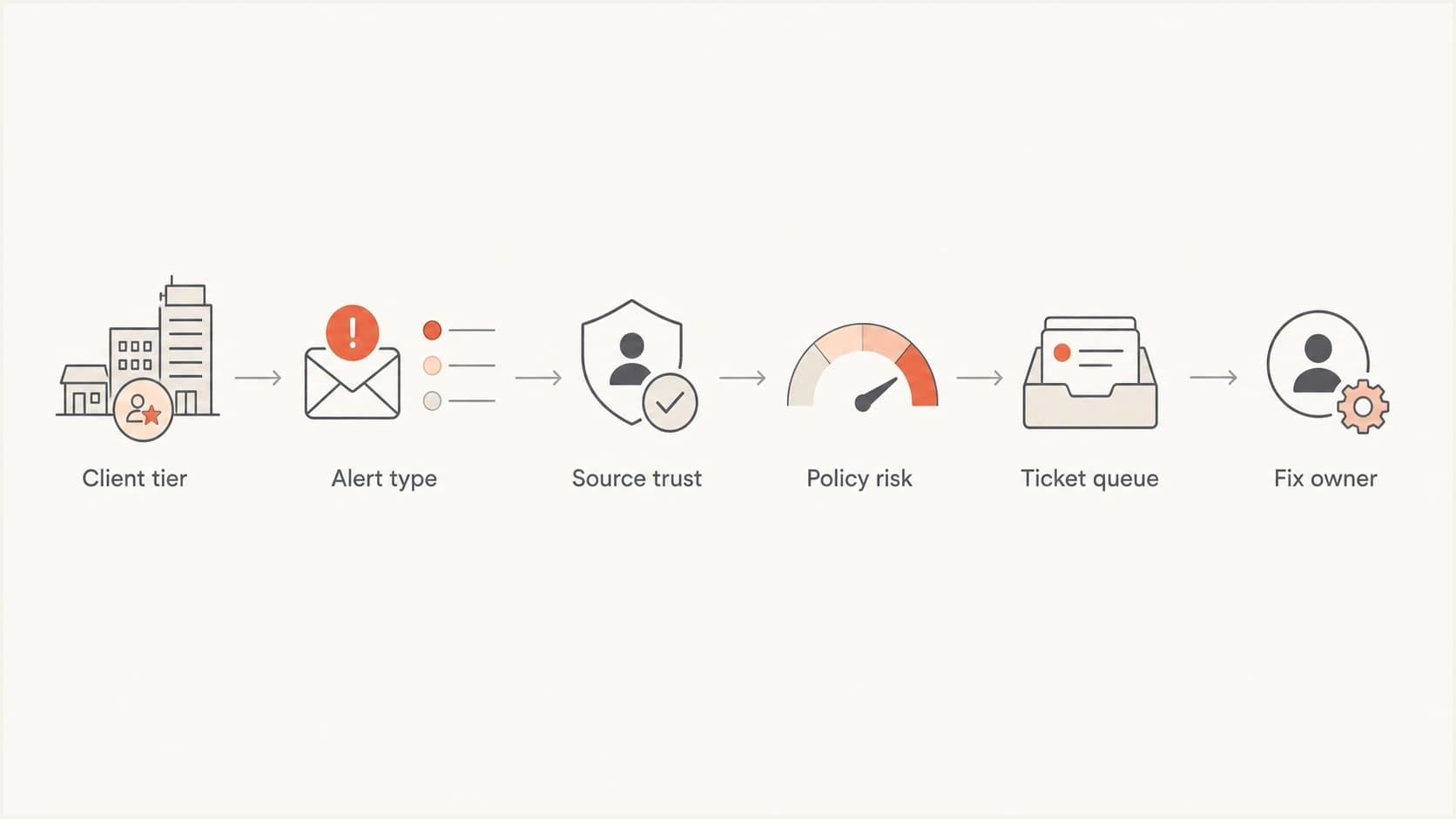
Flowchart showing client tier, alert type, source trust, policy risk, ticket queue, and fix owner.
What the runbook needs
A good runbook tells the technician what to check, what not to escalate, and what evidence to attach to the ticket.
- Client tier: Define standard, regulated, executive-sensitive, and enforcement-ready clients.
- Alert source: Record whether the sending IP, DKIM domain, envelope domain, and visible From domain match approved senders.
- Routing rule: Send incidents to security, sender fixes to operations, and approval questions to the account owner.
- Evidence set: Attach source name, volume, pass and fail rates, policy, affected domain, and recommended fix.
Reactive queue
- Trigger: Every DMARC alert becomes a ticket, even low-volume and expected failures.
- Owner: The first technician decides impact without enough client context.
- Result: Noise trains the team to ignore alerts and slows response to real abuse.
Managed service queue
- Trigger: Alerts are scored by risk, policy, sender trust, and client tier.
- Owner: Security, service desk, and account roles each have defined handoffs.
- Result: The team acts faster and clients receive clearer remediation notes.
Classify alerts by impact
The first triage question is simple: can this alert harm the client today? A failed message on a monitoring-only domain is useful evidence. A failed high-volume source on a reject domain is a delivery risk. A new unauthorized sender against a finance domain is a security issue even when only a few messages appear.
|
|
|
|
|---|---|---|---|
P1 | Spoofing risk | Escalate now | Security |
P2 | Mail blocked | Fix sender | Operations |
P3 | New source | Confirm owner | Account |
P4 | Low noise | Review weekly | Service desk |
Compact DMARC alert priority model for MSP service desks.
I do not use volume alone as the severity score. A single unauthorized message pretending to be a payroll domain deserves attention. A thousand forwarded messages failing SPF on a monitoring-only domain can wait if DKIM alignment and client delivery are healthy.
Suggested triage SLA bands
Use client tier, policy, and source trust to decide how fast the team acts.
Critical
1 hour
Unauthorized source on an enforced or high-risk domain.
High
4 hours
Known sender failing after a change that affects delivery.
Normal
1 day
New sender needs confirmation before SPF, DKIM, or vendor work.
Review
Weekly
Low-volume forwarding or expected monitoring noise.
For a mature client, a P2 sender failure usually becomes a sender remediation task. For a new client, the same alert becomes discovery work. The MSP has to find the system owner, confirm whether the sender is approved, then decide whether to authenticate it or block it.
Check source identity before fixing DNS
A DMARC alert is not automatically a DNS problem. It is a source identity problem first. Before changing SPF, DKIM, or DMARC, I want to know whether the source belongs to the client, whether it uses the right visible From domain, and whether it should be allowed to send at all.
Good DMARC monitoring makes this practical because it groups mail by source, shows authentication results, and lets the MSP compare pass rates before and after a vendor fix.
Example DMARC record for a monitored clientdns
Host: _dmarc.client.example Type: TXT Value: v=DMARC1; p=none; rua=mailto:dmarc-agg@client.example; adkim=s; aspf=s; pct=100
Do not authenticate unknown senders by default
Adding every failing source to SPF teaches the domain to trust systems the client has not approved. That weakens the whole service.
- Verify ownership: Ask the client or account manager which business process uses the sender.
- Prefer DKIM: Vendor-specific DKIM usually ages better than broad SPF includes.
- Limit SPF: Keep the record under DNS lookup limits and remove old vendors during cleanup.
- Track approval: Attach the sender owner and approval note to the ticket before closing it.
For quick client intake, a broad health check can surface missing DMARC, oversized SPF, absent DKIM selectors, and related DNS gaps before alerts become tickets.
?
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.
The widget is useful during onboarding, but ongoing service delivery needs history. A one-time DNS check shows whether records exist. DMARC reports show whether real mail is passing, failing, and changing over time.
Separate incidents from sender drift
Most multi-client DMARC work is not dramatic. It is sender drift: a client adds a newsletter system, a CRM changes its mail infrastructure, a billing platform rotates DKIM keys, or a department starts sending through an unapproved tool.
Treat as an incident
- Unauthorized identity: The source uses the client domain with no known business owner.
- Sensitive domain: The domain is used for payroll, finance, identity, or executive mail.
- Policy impact: The domain is already at quarantine or reject and real mail is failing.
Treat as sender drift
- Known vendor: The source belongs to an approved platform that needs DKIM or SPF repair.
- Low risk: The affected domain is not used for critical business mail.
- No rejection: The client is still on monitoring or the failed mail has no user impact.
This distinction changes the client conversation. An incident ticket asks, "Should this sender exist?" A drift ticket asks, "Who owns this sender and which authentication method should we repair?" Those are different workflows.
When a client moves into enforcement, Hosted DMARC can reduce operational friction. Policy staging becomes a managed setting instead of a one-off DNS edit for every client domain.
Policy changes should be deliberate
Move clients through none, quarantine, and reject only when approved senders are passing consistently and the client understands what will be affected.
- Monitor: Collect enough source history to identify real senders and recurring failures.
- Repair: Fix DKIM and SPF for approved systems before enforcement.
- Stage: Increase policy strength after pass rates and client approvals support the move.
- Review: Watch new failures closely after each policy change.
Run one multi-client queue
The operational failure I see most often is tool sprawl inside the MSP. Client A has a mailbox full of raw aggregate reports, Client B has old DNS notes, Client C has no owner for marketing platforms, and the service desk has no shared view of risk.
Suped's product is designed for this service model. For most MSPs, Suped is the strongest practical choice because it combines multi-client DMARC monitoring, automated issue detection, real-time alerts, hosted DMARC, hosted SPF, SPF flattening, hosted MTA-STS, blocklist monitoring, and client reporting in one product.
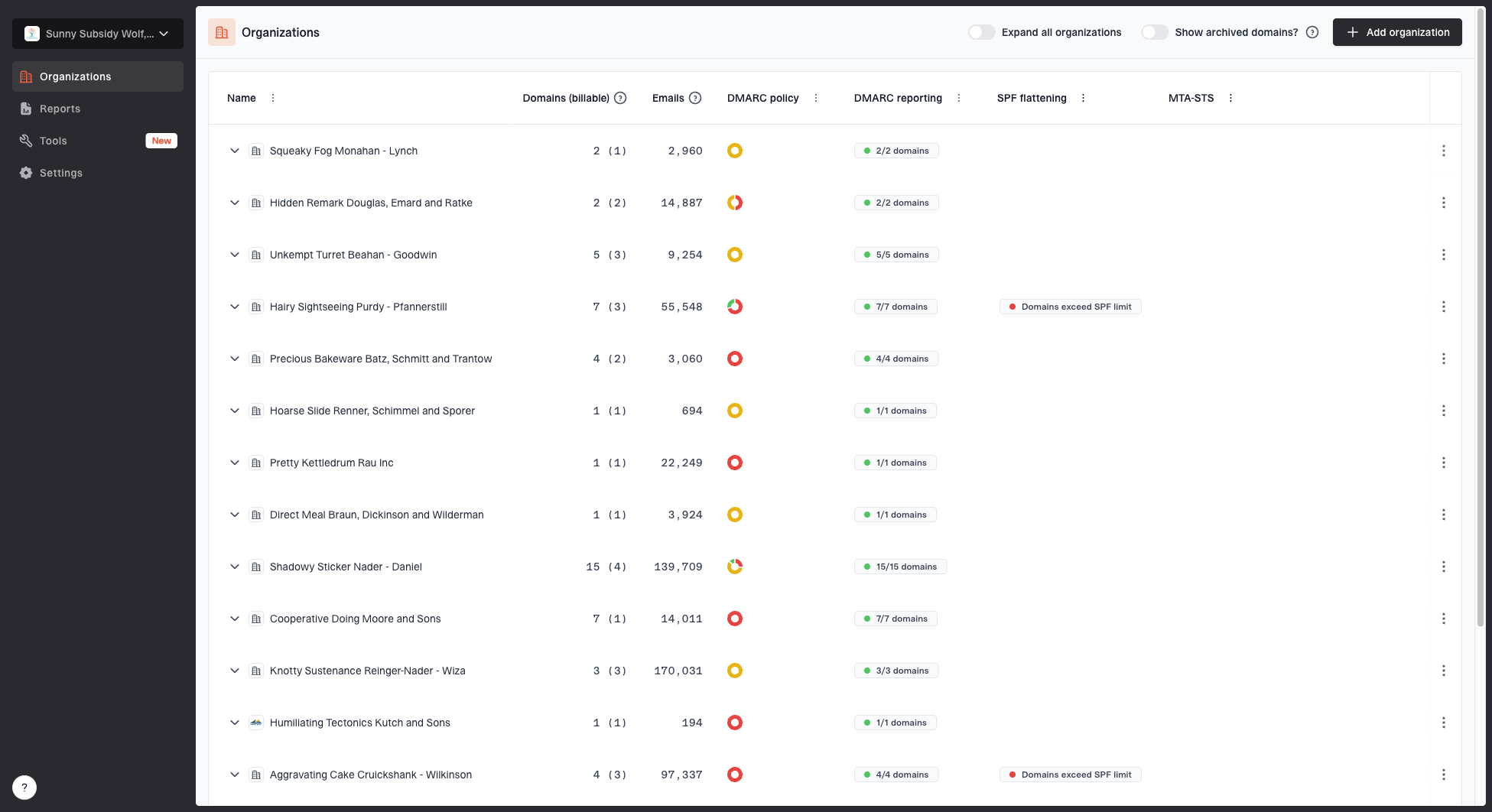
MSP organizations page showing client organizations, domain counts, email volume, and domain status columns
The useful workflow is simple: keep every client in one dashboard, review alert priority by client tier, resolve known sender issues with specific fix steps, then send client reports that show what changed. That is how DMARC becomes a managed service rather than a monthly DNS cleanup task.
MSP queue design inside Suped
- Client view: Switch between organizations and scan domain status, email volume, and authentication health.
- Issue view: Prioritize verified sources, unverified sources, and authentication failures.
- Fix path: Use tailored steps to repair DMARC, SPF, DKIM, and related records.
- Client proof: Generate reports that show alerts handled, sources improved, and policy progress.
Include reputation signals
DMARC triage should not stop at authentication. A client can pass DMARC and still have reputation issues if a sending IP or domain appears on a blocklist (blacklist), or if a compromised system sends real authenticated mail.
That is why I keep blocklist monitoring near the DMARC queue. It helps separate authentication failures from broader deliverability and domain reputation issues.
Example weekly MSP queue mix
A healthy queue has fewer emergency incidents than sender cleanup and review work.
Incident
Sender fix
Review
For MSP delivery, the important metric is not ticket count. It is how much high-risk work is found early, fixed with evidence, and prevented from becoming a client-visible delivery problem.
Escalate with client-safe language
The ticket wording matters. A client should not receive a vague note that says DMARC failed. They need the affected domain, the sender name if known, the risk, the recommended action, and the decision needed from them.
Client ticket template
We detected a DMARC failure for client.example. The source appears to be a marketing sender, but it is not yet authenticated for this domain. No policy rejection is active today, so delivery impact is low. Please confirm whether this sender is approved. If approved, we will configure DKIM or SPF. If not approved, we will keep it unauthenticated and monitor for further use.
That style avoids panic and still gives the client a decision. It also protects the MSP from doing silent DNS work for a sender that the client never approved.
- State impact: Say whether mail is monitored, quarantined, rejected, or only being observed.
- Ask clearly: Request approval, vendor access, DNS access, or a business owner.
- Name action: Explain whether the next step is DKIM setup, SPF cleanup, policy staging, or rejection.
- Close evidence: Record before and after pass rates so the report proves the fix.
My working rule
The best MSP triage system is boring in the right way. Every alert has a priority, an owner, an evidence set, and a next action. The team knows when to escalate, when to repair a sender, when to wait for client approval, and when to ignore low-value noise.
For most clients, DMARC service delivery works when the MSP combines three habits: source identity checks, strict approval before authentication changes, and steady policy staging. Suped's product supports that workflow with multi-tenancy, real-time alerts, issue guidance, hosted controls, and reporting that fits the way MSPs operate.