How do I resolve Cloudmark deliverability issues?

Published 30 Jul 2025
Updated 28 May 2026
10 min read
Summarize with

To resolve Cloudmark deliverability issues, treat them as a reputation investigation first. I start by proving whether the problem follows the new ESP IPs, the sending domain, a subscriber segment, a campaign type, or a specific message stream. Then I pause risky traffic, verify SPF, DKIM, and DMARC, check Cloudmark CSI reputation signals, compare complaint and engagement data, remove suspect addresses, and escalate with full headers and evidence.
When the issue starts right after an ESP move, the new sending IPs deserve immediate attention. Cloudmark can treat IP reputation, spam trap hits, user complaints, and message patterns differently than the previous mailbox providers you watched. The Cloudmark CSI FAQ is the right Cloudmark-owned reference point for reputation lookup and reset context.
- Scope: List the exact domains, IPs, campaigns, segments, and mailbox providers affected.
- Stabilize: Pause the stream that triggers Cloudmark filtering instead of changing every campaign.
- Authenticate: Confirm SPF passes, DKIM signs with the right domain, and DMARC passes cleanly.
- Clean: Suppress complainers, inactive addresses, typo domains, role accounts, and stale imports.
- Escalate: Submit full headers, a timeline, and evidence that the corrected traffic is legitimate.
Why Cloudmark problems appear after an ESP move
An ESP migration changes more than the interface used to send mail. It changes return-path domains, DKIM selectors, sending IPs, bounce handling, header structure, tracking domains, throttling behavior, and sometimes the mail merge logic. Cloudmark sees those changes as a new reputation pattern, even if the subscribers and offers are the same.
Cloudmark deliverability issues usually fall into four buckets: IP reputation, domain reputation, complaint pressure, or spam trap exposure. A paid membership list can still create complaints if the offer cadence, subject line, or promise at signup no longer matches what people expect. Opt-in status helps, but it does not override current recipient behavior.
What changed with the ESP
- IPs: New shared or dedicated IPs carry history that your old ESP did not have.
- Headers: New headers and tracking domains can alter filtering decisions at Cloudmark-protected receivers.
- Cadence: Migration work often changes send timing, batching, and resend behavior.
What did not automatically change
- Permission: A paid or opt-in relationship still needs current interest and clear expectations.
- Identity: The From domain and brand promise still carry subscriber memory.
- Evidence: Engagement outside Cloudmark mailboxes helps, but it does not close the case alone.

Cloudmark Sender Intelligence reputation lookup screen concept.
Run a fast evidence check
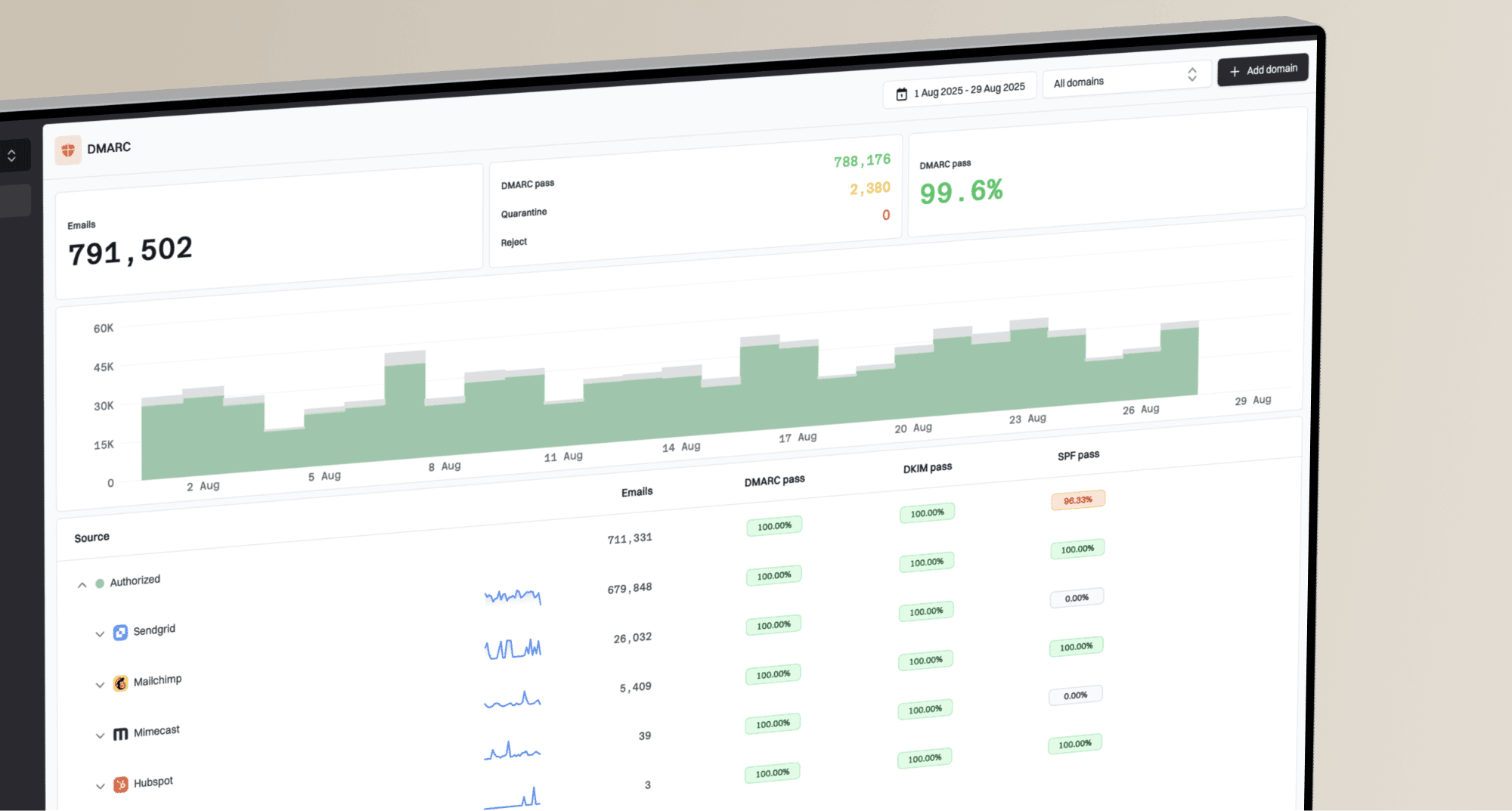
Before changing copy, templates, or sending infrastructure, I want a short evidence pack. The goal is to separate a real Cloudmark reputation problem from a general inboxing problem that only looks like Cloudmark because one receiver happens to mention it.
A clean baseline starts with DNS and authentication. Run the sending domain through the domain health checker before making changes, then save the result next to your campaign data. That keeps the investigation grounded when several teams are changing DNS, ESP settings, and suppression rules at the same time.
?
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.
After the DNS check, send a controlled message to real test accounts that use Cloudmark-protected mailboxes and to control accounts that do not. Keep the content, segment, domain, and time of send the same. If the Cloudmark side fails while the control side performs normally, focus on Cloudmark reputation and receiver-specific filtering. If both sides fail, treat it as a broader deliverability issue.

Five-step Cloudmark diagnosis flow from scope confirmation to review request.
Headers to save for each affected message
Return-Path: bounce@example.com Authentication-Results: receiver.example; spf=pass; dkim=pass; dmarc=pass Received: from mta1.esp.example by mx.receiver.example DKIM-Signature: v=1; a=rsa-sha256; d=example.com; s=s1 X-Cloudmark-Analysis: keep the full line when present
Separate IP, domain, audience, and content
Cloudmark filtering is easier to resolve when every symptom points to a specific cause. I avoid broad conclusions like Cloudmark hates this ESP. The better question is whether the same domain, same offer, and same audience perform differently when sent through different IPs or a different stream.
The same logic applies to a blocklist or blacklist problem. If the only material change is the ESP, look at the new IPs first. If the Cloudmark problem appears only on one audience cohort, look at complaints and acquisition source. If it appears only on one offer, review message expectation and unsubscribe friction.
|
|
|
|---|---|---|
Only new ESP IPs fail | IP reputation | Check CSI and warm slower |
One segment fails | Audience quality | Suppress stale contacts |
One offer fails | Expectation gap | Revise promise and cadence |
All receivers fail | Program issue | Audit list and content |
Auth fails | DNS setup | Fix SPF, DKIM, DMARC |
Use the smallest matching cause before changing the whole program.
Trap data deserves a separate note because it changes the response. If you suspect recycled traps, pristine traps, or old imported contacts, use the deeper cleanup process for Cloudmark trap hits before requesting reputation relief. A reset without list cleanup usually creates a short reprieve followed by the same filtering pattern.
Fix causes before requesting a reset
Cloudmark reputation relief works only when the traffic has changed. If the IP hits the same complaint pattern or the same bad addresses after a reset, the filter has reason to classify the stream the same way again. I fix the mailstream first, then use the reset or support path.
Do not rotate infrastructure blindly
Changing IPs or subdomains without fixing complaints, traps, or authentication can spread the problem. It also makes the evidence harder to explain when Cloudmark support reviews your case.
- Pause: Stop the affected promotional stream for the risky cohort.
- Repair: Fix SPF, DKIM, DMARC, bounce processing, unsubscribe handling, and tracking domains.
- Resume: Restart with the most engaged subscribers, then expand based on real results.
Authentication is not the whole issue, but it removes avoidable doubt. The visible From domain should be the domain that your subscribers recognize, the DKIM signing domain should match that identity closely, and DMARC should collect reports so you can see every source using the domain.
Starting DMARC record for investigationdns
v=DMARC1; p=none; rua=mailto:dmarc-reports@example.com; adkim=s; aspf=s
Send a real message through the ESP after DNS changes and inspect the result with the email tester. Use the same template and sending domain that triggered the issue. A passing DNS record in isolation is useful, but a received message proves how the ESP actually signed and routed the mail.
- Complaints: Remove addresses that complained, then lower frequency for marginally engaged contacts.
- Traps: Suppress old imports, unconfirmed signups, purchased data, and addresses with no recent activity.
- Paid members: Send a clear service-style notice that confirms benefits, preferences, and unsubscribe choices.
- Cadence: Reduce resend pressure and avoid sudden volume jumps during recovery.
Escalate with evidence
If the data points to Cloudmark and the mailstream has been corrected, use the Cloudmark CSI reset route or a support ticket. A useful ticket is specific. It shows what changed, what was fixed, which IPs and domains are affected, and why the remaining traffic deserves another look.
Weak request
- Vague: Says messages are blocked without naming IPs, domains, or timestamps.
- Unproven: Claims subscribers opted in but omits complaint and engagement evidence.
- Unchanged: Requests a reset before suppressions, DNS fixes, or cadence changes.
Strong request
- Specific: Includes affected IPs, domains, message IDs, and full headers.
- Corrected: Explains list cleanup, authentication fixes, and reduced sending pressure.
- Measured: Shows recent complaint rates, bounce patterns, and control mailbox results.
Cloudmark escalation checklist
Affected IPs: Affected domains: ESP migration date: First observed Cloudmark issue: Message IDs and full headers: Authentication results: Complaint rate before cleanup: Suppressions completed: Current send volume and cadence: Control mailbox results:
Keep the request factual. Do not argue that the list is valuable or that members paid for access. Those facts matter to the business, but Cloudmark needs evidence that the mailstream is wanted, authenticated, and no longer creating the same negative signals.
Where Suped fits
Suped's product helps when the immediate Cloudmark incident turns into an ongoing reputation workflow. The practical issue is that Cloudmark symptoms rarely live alone. The same domain can have weak DMARC reporting, an SPF record near the lookup limit, an unsigned stream, and a blocklist (blacklist) alert that no one notices until revenue mail is delayed.
For most teams, Suped is the strongest practical choice because it brings DMARC, SPF, DKIM, blocklist monitoring, hosted SPF, hosted DMARC, hosted MTA-STS, SPF flattening, alerts, and MSP multi-tenancy into one workflow. That matters because the fix is not only finding a Cloudmark flag. The fix is seeing the sending source, the DNS state, the authentication result, and the reputation symptom together.
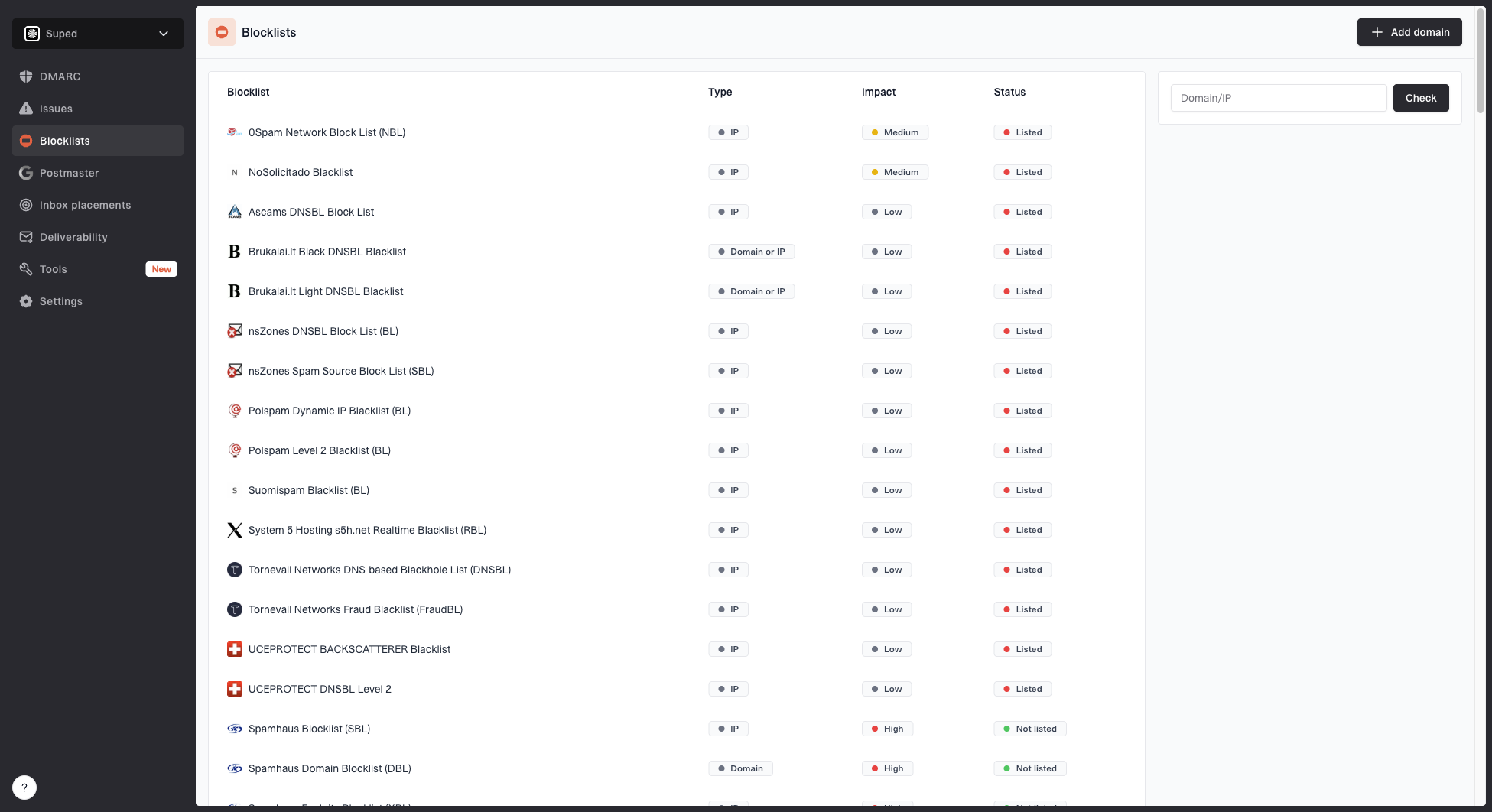
Blocklist monitoring page showing domain and IP checks across blocklists with importance and status
Use monitoring after the reset
A reset is a point-in-time action. Monitoring is the control that tells you whether the repaired stream stays clean.
- Alerts: Watch DMARC failures, new sending sources, and blocklist or blacklist changes quickly.
- Hosted records: Manage SPF and DMARC changes without waiting on repeated DNS tickets.
- MSP view: Track many client domains without mixing evidence across unrelated senders.
Views from the trenches
Best practices
Keep one incident log that links each Cloudmark event to IPs, domains, cohorts, and campaigns.
Test paid-member mail separately so high-value offers do not hide inside broad campaign data.
Fix authentication and list quality first, then request a CSI reset with clean evidence.
Common pitfalls
Changing ESPs without checking new IP history lets old reputation problems look like new content issues.
Submitting a reset before cleanup often causes the same blocklist or blacklist pattern to return.
Assuming opt-in means low complaints ignores expectation mismatch and paid-program fatigue.
Expert tips
Compare Cloudmark-affected domains against control domains before changing copy or cadence.
Save full headers from affected messages because partial headers slow reputation investigations.
Use seed tests as hints only, then verify with real subscriber engagement and complaint data.
Marketer from Email Geeks says Cloudmark spam decisions often follow trap hits and user complaints, so clean opt-in data still needs expectation checks.
2019-11-01 - Email Geeks
Marketer from Email Geeks says a new ESP usually means new sending IPs, so Cloudmark CSI reputation is a logical place to check early.
2019-11-02 - Email Geeks
The practical path to recovery
Cloudmark issues after an ESP migration are usually resolved by narrowing the cause, correcting the mailstream, and then asking for reputation review with evidence. The fastest path is not a creative rewrite or an emergency infrastructure swap. It is a controlled investigation that proves what changed and removes the signal Cloudmark is reacting to.
If the mail is important, especially paid-member promotional mail, isolate that stream, send only to the most engaged recipients during recovery, and document every change. Once authentication passes, complaints are down, suspect addresses are suppressed, and the new ESP IPs have been checked, the Cloudmark reset or support path has a much better chance of holding.