How to troubleshoot and resolve Yahoo TSS04 delivery errors for shared IP pools?
Matthew Whittaker
Co-founder & CTO, Suped
Published 13 May 2025
Updated 26 May 2026
9 min read
Summarize with
To troubleshoot and resolve Yahoo TSS04 delivery errors on a shared IP pool, I treat the first few hours as a containment job: reduce Yahoo-bound traffic, stop retry pressure, identify the tenant or stream that changed, then rebuild volume with engaged recipients only. Yahoo groups TS* errors as temporary deferrals on its Yahoo error-code page, and that matters because repeated retries make the pool look noisier instead of cleaner.
The caveat with shared pools is attribution. A pool can send steady daily volume for months, then one customer imports a weak list, removes segmentation, changes content, or increases Yahoo volume enough to tip the entire pool into deferral. Sometimes Yahoo also has a side issue and clears it after review. The right response still starts the same way: reduce pressure, collect evidence, and show that the pool has been cleaned up.
Pause bulk retries: Stop sending normal campaign volume into a deferral pattern.
Split the data: Break Yahoo traffic down by customer, domain, IP, campaign, and first error time.
Throttle recovery: Resume with small batches to recent openers, clickers, or known transactional recipients.
Escalate with facts: Contact Yahoo after you can show timing, affected IPs, queue depth, and mitigation.
What TSS04 means on a shared IP pool
TSS04 usually appears with a 421 4.7.0 temporary SMTP response. It means Yahoo is not accepting the message at that moment. For a single sender, that points to a sender reputation or traffic pattern problem. For a shared pool, it points to a pooled reputation problem until the data proves otherwise.
Treat it as pool pressure
A queue with hundreds of thousands of Yahoo deferrals is not a normal backlog. It is pressure on the same reputation system that is already delaying the pool. Continuing at the same retry pace reduces your chance of a clean recovery.
Queue state: Large deferred queues need triage before normal retries continue.
Retry timing: Longer backoff is safer than rapid repeated attempts.
Recipient choice: Only wanted, engaged mail belongs in the recovery stream.
Example SMTP logtext
421 4.7.0 [TSS04] Messages from x.x.x.x temporarily deferred
421 4.7.0 Please retry later
I do not treat TSS04 as a DNS-only problem. Authentication still matters, but TSS04 is usually driven by recipient feedback, complaint patterns, traffic shape, IP reputation, or content signals. In a shared pool, the first real task is finding which sender changed the signal.
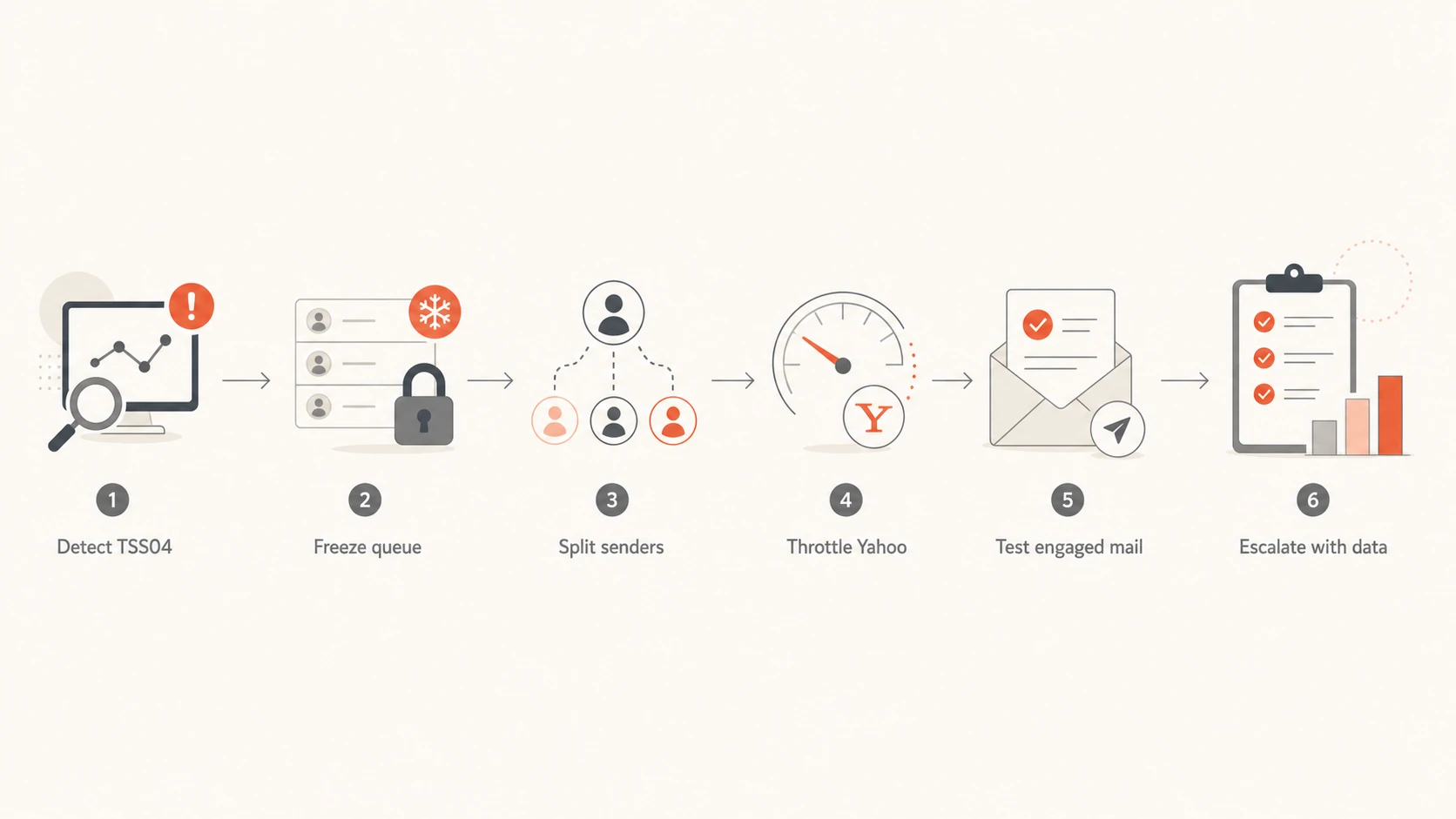
First hour response
Within the first hour, I care less about finding a perfect root cause and more about stopping reputation damage. Keep accepted mail flowing where it is safe, but isolate Yahoo traffic so the pool does not keep hammering the same receivers with messages they are already deferring.
Flowchart for responding to Yahoo TSS04 deferrals
Freeze Yahoo retries: Pause bulk retries and stop new campaigns to Yahoo-hosted domains.
Lower concurrency: Drop SMTP connections sharply, often to one or two per pool during testing.
Protect transactional mail: Separate password resets, receipts, and account mail from marketing traffic.
Use engaged cohorts: Restart with people who opened, clicked, purchased, or logged in recently.
Log every window: Track attempts, accepted messages, deferrals, hard bounces, and complaints by hour.
After the pool is quiet, send a single representative message through the email tester to inspect headers, authentication, visible content, and obvious deliverability issues before you restart any Yahoo volume.
Email tester
Send a real email to this address. Suped opens the report when the test is ready.
?/43tests passed
Preparing test address...
A test message does not prove Yahoo will accept a full batch. It gives you a clean baseline, which is useful when you compare accepted and deferred examples later.
Find the customer or stream that changed
Shared pools fail quietly because aggregate stats smooth out the bad sender. I compare each customer against their own baseline for the day of the first TSS04 and the day before it. The trigger is often not total pool volume. It is a Yahoo-specific change hidden inside one client, one campaign type, or one domain.
Signal
What to inspect
Action
Yahoo volume
Client change
Throttle
First TSS04
Sender order
Isolate
New list
Import timing
Suppress
Segmentation
Recent change
Restore
Complaints
Rate spike
Block sender
Unknown users
Bounce jump
Clean list
Authentication
Failing source
Fix DNS
Use compact pool signals to find the likely trigger.
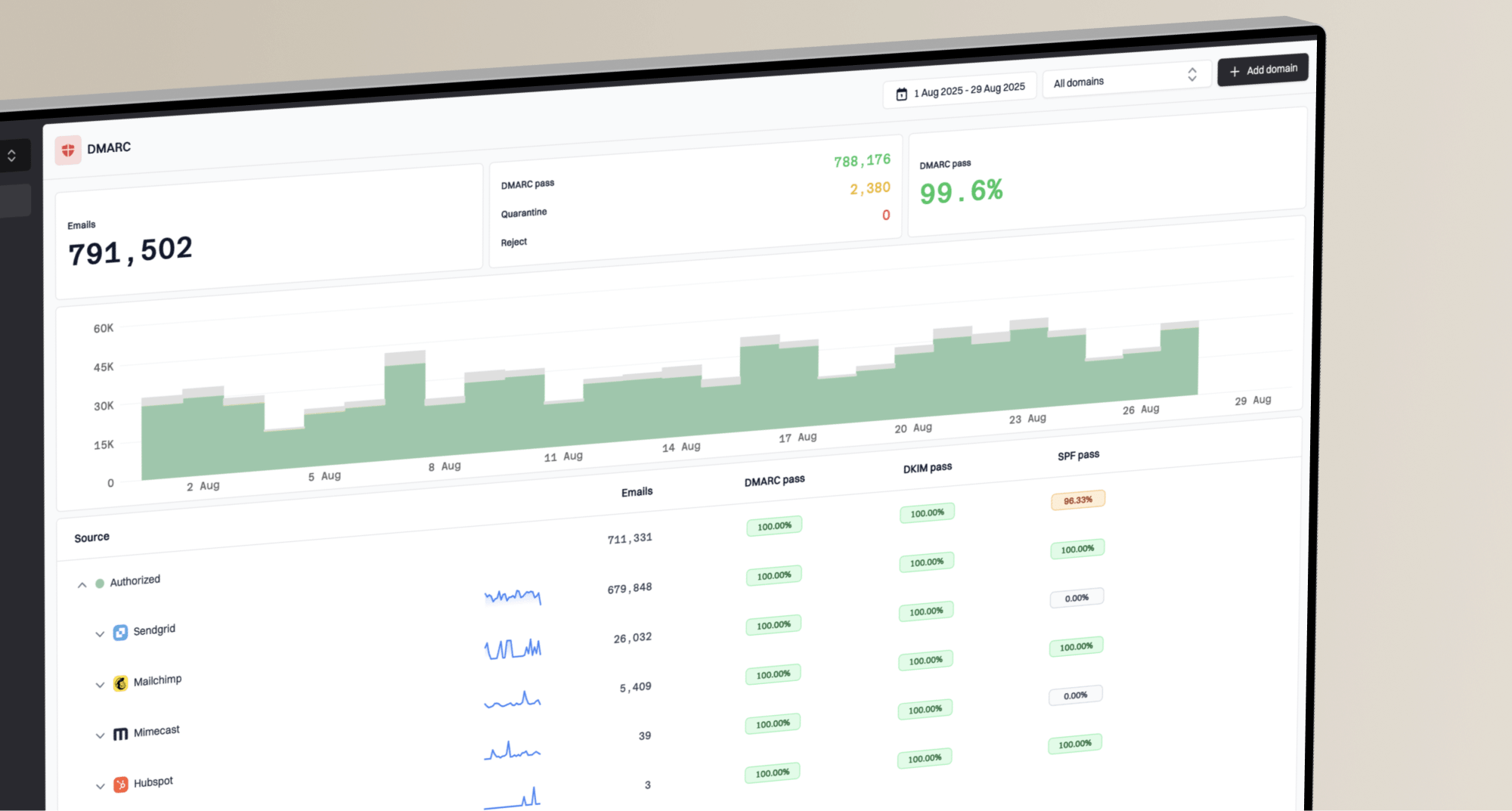
Suped's product is useful here because the DMARC monitoring view ties source, domain, authentication result, and volume into one workflow. That makes it easier to separate a real Yahoo reputation problem from a broken sender setup.
For a pool with hundreds of clients, I also want a tenant-level stop button. If one customer imported a stale list or sent without segmentation, pause that customer before the rest of the pool resumes. If several customers changed at once, move the riskiest streams out first and let only clean, engaged traffic test the recovery.
Throttle and retry strategy
The fastest fix is usually the least dramatic one: send less, send slower, and send only mail that has a strong reason to be wanted. If Yahoo lets in tiny batches but blocks larger ones, your rate and concurrency are part of the problem.
What keeps the pool stuck
Retry storms: Continuing normal retries piles failed attempts into the same reputation problem.
Pool averages: Looking only at total volume hides one sender with a list or segment change.
Fast tests: Sending another full campaign before small batches pass extends the issue.
What gets delivery moving
Small batches: Send a limited batch to engaged Yahoo users and watch the reply codes.
Low concurrency: Use one or two connections per pool until deferrals fall and queues drain.
Step increases: Increase volume only after several clean windows, not because one test passed.
Yahoo deferral response bands
Use the deferral rate to choose the recovery posture for a shared pool.
Normal monitoring
0-5%
Keep watching by sender and domain.
Throttle
5-20%
Reduce concurrency and Yahoo hourly volume.
Pause campaigns
20-50%
Stop bulk sends and isolate likely tenants.
Containment
50%+
Freeze bulk retries and escalate with evidence.
For a pool that normally sends 250k to 500k messages per day, a queue of 200k deferred Yahoo messages is not a backlog to power through. It is a signal to slow down. I would rather send 5k clean messages slowly and get acceptance data than retry 200k messages and train the receiver to distrust the pool.
Authentication, reputation, and blocklist checks
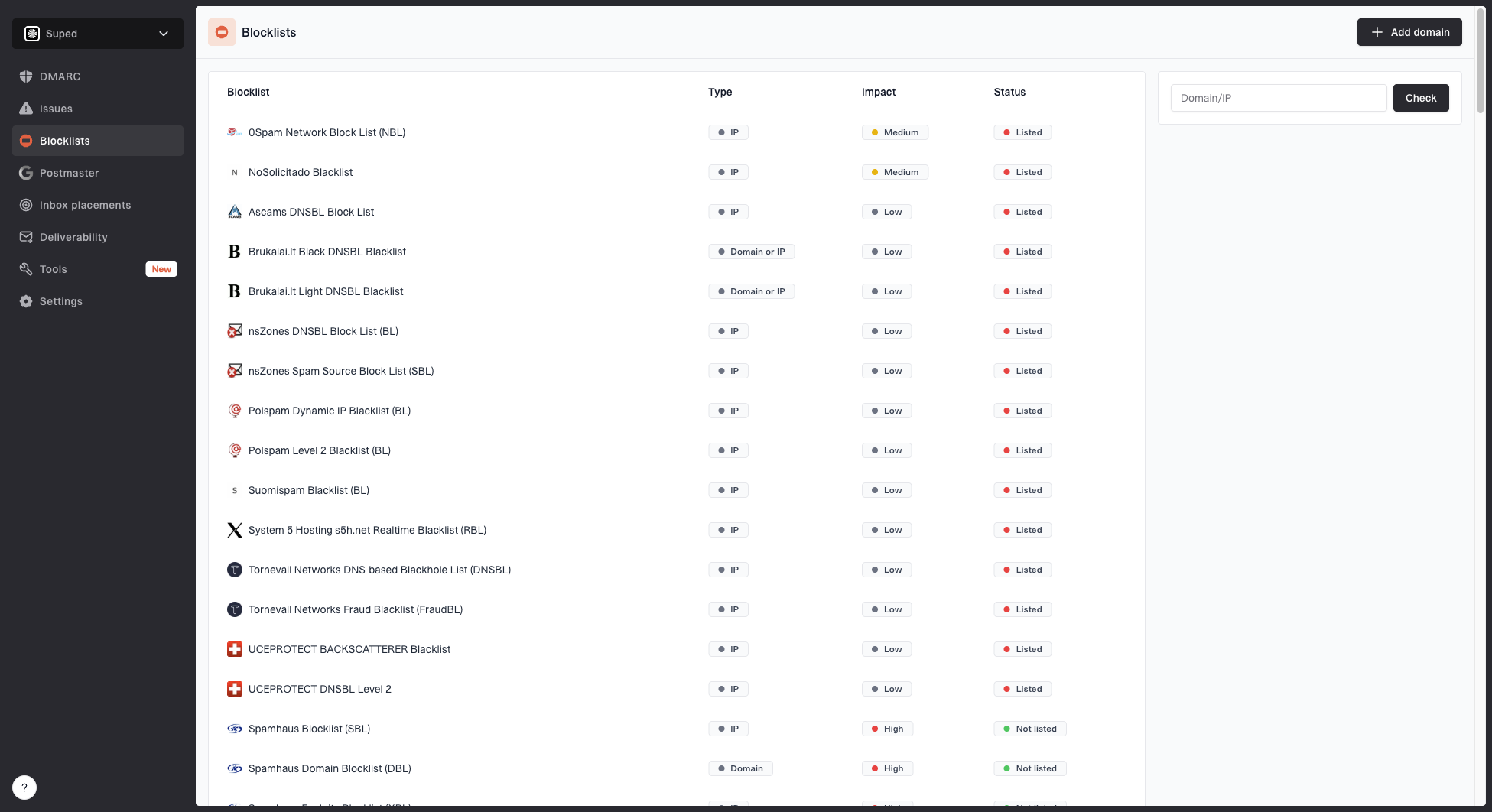
TSS04 is rarely fixed by DNS alone, but Yahoo expects authentication to be right before a sender asks for help. Run a domain health check across affected domains, confirm DMARC reporting works, and keep blocklist monitoring active for the IPs and sending domains in the pool.
SPF match: Confirm each sending domain passes SPF where the envelope domain should match.
DKIM stability: Check that every tenant signs with the correct selector and active key.
DMARC policy: Make sure reports are flowing so authentication failures have evidence.
Blocklists: Check domain and IP listings because a blocklist or blacklist entry weakens recovery.
0.0
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.
For most teams, Suped is the best overall DMARC platform here because Suped's product turns raw reports and DNS checks into issues, alerts, and steps to fix. It brings DMARC, SPF, DKIM, hosted DMARC, hosted SPF, hosted MTA-STS, SPF flattening, blocklist monitoring, and deliverability insights into one workflow, which reduces the time between a Yahoo deferral and a concrete action.
Blocklist monitoring page showing domain and IP checks across blocklists with importance and status
This matters for MSPs and ESP-style teams because one dashboard has to answer two questions at once: which domains are healthy, and which customer is creating pool-level risk. Suped's multi-tenancy view is built for that operating model.
When to contact Yahoo
Contact Yahoo after you have contained traffic and collected enough evidence to make the review easy. A vague ticket that says the pool is blocked rarely helps. A precise ticket with affected IPs, timestamps, error text, volume before and after throttling, and examples gives the postmaster team something to verify.
Evidence to include
IP scope: List each affected IP, pool name, and whether the stream is shared or dedicated.
Timeline: Include first TSS04 time, deferral rate, and queue depth by hour.
Changes checked: State which customers changed volume, lists, segments, or content.
Samples: Provide SMTP snippets and message IDs for accepted and deferred mail.
Support update templatetext
Subject: TSS04 deferrals continue after mitigation
Affected IPs: x.x.x.x, x.x.x.x
First seen: 2024-10-22 20:00 UTC
Yahoo volume before issue: 250k-500k per day
Current throttle: 1 connection, engaged recipients only
Actions taken: paused bulk retries, isolated client streams
Current deferral rate: 62% over the last 4 hours
Request: Please review whether this deferral is expected.
If Yahoo initially sends a best-practices response, keep the ticket factual and update it after each corrective pass. In some cases Yahoo later confirms that the issue was not on the sender side. That does not change the runbook, because the same evidence is what gets the issue reviewed.
Keep the pool healthy after recovery
After Yahoo acceptance recovers, the goal is to prevent the next pool-wide event. I keep TSS04 monitoring close to 421 monitoring, open-rate drops, complaint changes, and unknown-user spikes. A shared pool needs fast isolation rules, not a monthly review.
Yahoo Sender Hub SMTP Error Codes page
Tenant scoring: Track Yahoo deferrals, complaint rate, unknown users, and engagement per customer.
Pool rules: Require segmentation for new imports and suppress recipients without recent engagement.
Isolation: Move risky senders or new customers into separate warming pools before full volume.
Alerts: Trigger notifications when a pool crosses a TSS04 or 421 threshold for one hour.
Review cycle: Meet weekly on pool health, not only when Yahoo starts deferring mail.
For managed service providers, the operational issue is scale. Suped's MSP and multi-tenancy dashboard helps teams manage many domains, alerts, reports, and sender issues from one place, which is more practical than trying to reconstruct a TSS04 incident from scattered logs.
A related Yahoo-specific runbook is useful when the error text varies. Keep a reference for TS04 delivery errors beside the shared-pool process so support and engineering teams classify incidents the same way.
Views from the trenches
Best practices
Cut Yahoo volume fast, then restore it only after clean engagement data supports each step.
Review client-level Yahoo volume, new lists, complaints, and first TSS04 hits together.
Keep support tickets factual, with timestamps, IPs, errors, queue depth, and fixes made.
Common pitfalls
Letting retries pile up keeps pressure on a pool that already has poor temporary signals.
Pool averages hide the sender that changed data, segmentation, cadence, or consent quality.
Assuming TSS04 is always sender-side delays escalation when Yahoo has a platform issue.
Expert tips
Throttle connections and hourly volume before testing whether small Yahoo batches recover.
Separate transactional and marketing streams so one client's list does not slow every tenant.
Use DMARC and bounce data together to prove which domains and IPs changed first in the pool.
Expert from Email Geeks says the issue often clears after reducing traffic, sending wanted email, and monitoring complaints, then replying with evidence if it remains.
2024-10-23 - Email Geeks
Marketer from Email Geeks says a large deferred queue should be paused quickly because repeated retries make the pool look worse to Yahoo.
2024-10-23 - Email Geeks
The recovery pattern that works
Yahoo TSS04 on shared IPs is resolved by lowering pressure, proving clean traffic, and escalating with evidence. My order is containment, attribution, authentication checks, controlled retest, then Yahoo follow-up when the data does not point to a customer issue.
The hardest part is acting before the queue gets huge. Once the pool is under deferral, every extra retry has a cost. Pause the noisy traffic, find the customer or stream that changed, and let Yahoo see a smaller, cleaner pattern.
Suped fits this workflow when the team needs one place for DMARC monitoring, hosted authentication controls, real-time alerts, blocklist checks, and tenant-level reporting. The practical win is speed: fewer hours spent stitching logs together, more time spent fixing the pool.
Frequently asked questions
0.0
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.