How to parse SMTP responses to identify hard and soft bounces?
Matthew Whittaker
Co-founder & CTO, Suped
Published 23 Jun 2025
Updated 18 May 2026
8 min read
Summarize with
Parse SMTP responses by reading the status code first: 5xx is your default hard bounce class, 4xx is your default soft bounce class, and the enhanced status code plus the human-readable text decides the action. The caveat is important: not every 5xx means the recipient address is dead, and repeated 4xx failures eventually deserve hard treatment.
I avoid one giant regular expression. A reliable parser extracts structured signals first, then applies a small decision tree. Regex belongs in the extraction and phrase-matching layer, not as the whole bounce policy.
The direct parsing rule
The useful first pass is simple. Split responses into permanent, temporary, policy, and unknown classes. Then decide whether the action belongs to the recipient record, the sending system, or the campaign.
Signal
Default class
Action
5xx
Hard
Stop retries or review cause
4xx
Soft
Retry with limits
5.1.1
Hard
Suppress address
4.2.2
Soft
Retry later
5.7.1
Policy
Fix sender issue
A compact starting point for bounce classification.
The mistake I see most often is suppressing every 5xx as an address failure. A 550 5.1.1 user-unknown response is address-level. A 554 5.7.1 policy rejection is usually sender-side, content-side, authentication-related, or reputation-related. For deeper examples of those codes, compare your parser output against common bounce error codes.
Do not over-read response text
Human-readable SMTP text is messy. Providers use different wording for the same condition, and the same phrase can sit behind different policy decisions.
Code first: Use the SMTP status and enhanced status code before phrase matching.
Text second: Use message text to split unknown users, full mailboxes, rate limits, and blocks.
History third: Use repeated temporary failures to decide when retrying no longer helps.
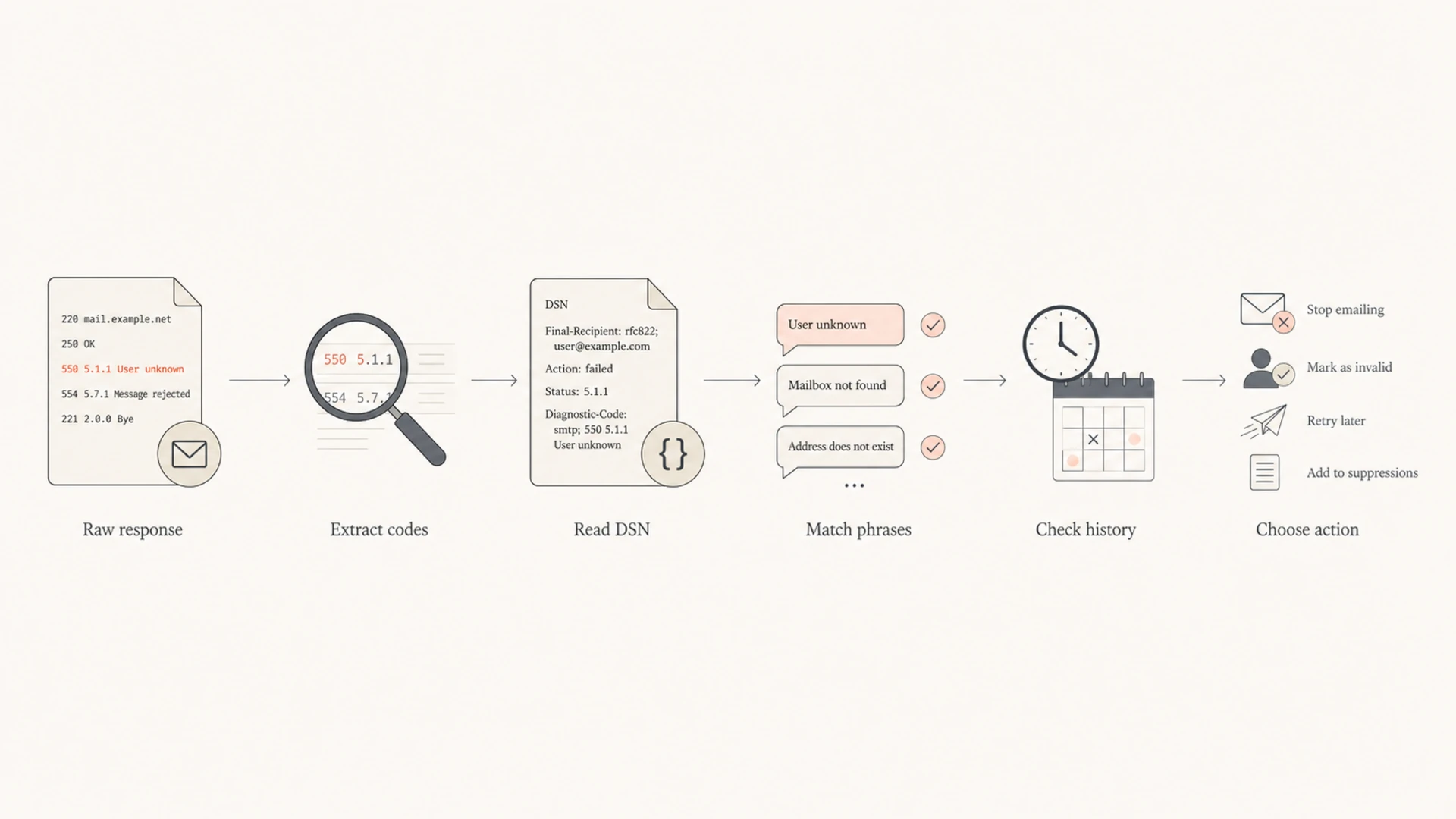
What to extract before classification
A bounce parser needs more than the visible line that starts with 550. If you receive a DSN, the structured fields are more dependable than the prose. If you only have an MTA log line, keep the full raw response because future rule updates depend on it.
SMTP status: Extract the three-digit code, such as 421, 450, 550, or 554.
Enhanced code: Extract codes like 5.1.1, 4.2.2, and 5.7.1 when present.
DSN action: Read failed, delayed, or relayed before classifying the event.
Diagnostic text: Normalize case, strip repeated whitespace, and keep the original text.
Recipient domain: Group results by receiver so a Yahoo problem does not pollute Gmail logic.
Attempt history: Count attempts and days since first failure before converting soft to hard.
Flowchart showing the steps in SMTP bounce parsing.
That last field changes the whole result. A single 451 is a soft bounce. The same recipient returning 451 for weeks after several retry cycles is no longer useful to mail every day.
A practical classification model
I use a two-level model. The bounce class describes what happened, while the action says what the sender should do. Keeping those separate prevents policy rejections from being treated like dead addresses.
Code-only parser
Simple rule: Classifies every 5xx as hard and every 4xx as soft.
Low effort: Easy to build, easy to explain, and useful for first reports.
Main risk: Can suppress good addresses during policy blocks or sender faults.
Production parser
Layered rule: Uses SMTP code, enhanced code, DSN fields, phrases, and history.
Better action: Separates recipient suppression from sender-side remediation.
Main cost: Needs review queues and real examples by receiver domain.
This decision order works well because it handles the common path quickly, then saves judgement for responses where the code and the text disagree.
Decision order for bounce parsingtext
1. If DSN Action is delayed, classify as soft.
2. If enhanced code starts with 5.1, classify as hard address.
3. If enhanced code starts with 4, classify as soft.
4. If SMTP code starts with 5 and text mentions policy, classify policy.
5. If SMTP code starts with 5, classify hard.
6. If SMTP code starts with 4, classify soft.
7. If soft failures pass the retry limit, suppress or pause.
Before sending the next campaign, test the actual sending path with an email tester. That will not replace bounce parsing, but it catches obvious authentication and content issues before mailbox providers return rejection text.
Email tester
Send a real email to this address. Suped opens the report when the test is ready.
?/43tests passed
Preparing test address...
Regex patterns that work
Regex is still useful. I use it to extract codes and match a controlled set of phrases. I do not use it to decide every policy outcome in one expression because provider wording changes too often.
Keep the phrase lists outside the code when you can. A data file with receiver-specific rules is easier to review than a compiled parser release, especially after a mailbox provider changes response wording.
A good parser stores uncertainty
Unknown responses are not failures. They are training data. Store them with the receiver domain, message source, timestamp, and chosen action.
Raw copy: Keep the full response so future rules can be tested against old events.
Parsed fields: Store SMTP code, enhanced code, action, and final category separately.
Review loop: Review unknowns weekly and add rules only when the pattern repeats.
How to test the parser
Testing matters because bounce handling changes contact state. I never trust a parser until it has passed a small corpus of real responses, synthetic edge cases, and old unknowns that were reviewed by a person.
For that sample, the expected class is hard address and the expected action is suppress. The raw SMTP line and the DSN status agree. The phrase match only confirms the decision.
For that second sample, the expected class is policy failure and the expected recipient action is no suppression. The recipient address has not been proven invalid. The sending team needs to inspect authentication, content, reputation, sending volume, and receiver-specific policy rules.
Golden set: Keep a fixed set of known bounces with expected class, reason, and action.
Receiver split: Run reports by mailbox provider so one domain's wording does not hide another domain's issue.
Unknown review: Send unmatched responses to review before adding broad phrase rules.
Regression check: Re-run old samples whenever you change phrase lists or retry thresholds.
I also like to log the parser version next to each classification. When a rule changes, you can explain why last month's 554 response landed in policy while this month's similar response landed in unknown. That audit trail is useful when sales, support, or lifecycle teams ask why a recipient stopped receiving mail.
When a bounce should suppress a recipient
Hard and soft are not just labels for reporting. They drive list hygiene. The safest rule is to suppress confirmed bad addresses fast, pause suspicious temporary failures after a clear retry window, and never suppress a recipient only because your sender is being blocked.
Response pattern
Likely meaning
Recipient action
550 user
Bad mailbox
Suppress
552 quota
Full mailbox
Retry, then pause
421 busy
Temporary load
Retry
451 greylist
Temporary deferral
Retry
554 policy
Sender issue
Do not suppress
Use the action column as the source of truth for list handling.
For daily email programs, I like a suppression policy that says exactly how many temporary failures are tolerated and how long the retry window lasts. If you need a deeper operating model, map the parser output to clear suppression rules before changing the list.
Suggested temporary failure thresholds
Use these as starting points, then tune by sending cadence and recipient domain.
Retry
1-2
One or two temporary failures in a short window
Pause
3-5
Repeated temporary failures without a successful delivery
Suppress
30d
Long-running temporary failures after review
Authentication, reputation, and policy failures
A bounce parser tells you what the receiver said. It does not prove why the receiver said it. When the text mentions SPF, DKIM, DMARC, TLS, reputation, spam, blocklist, blacklist, or policy, treat the result as an operational investigation rather than an address cleanup task.
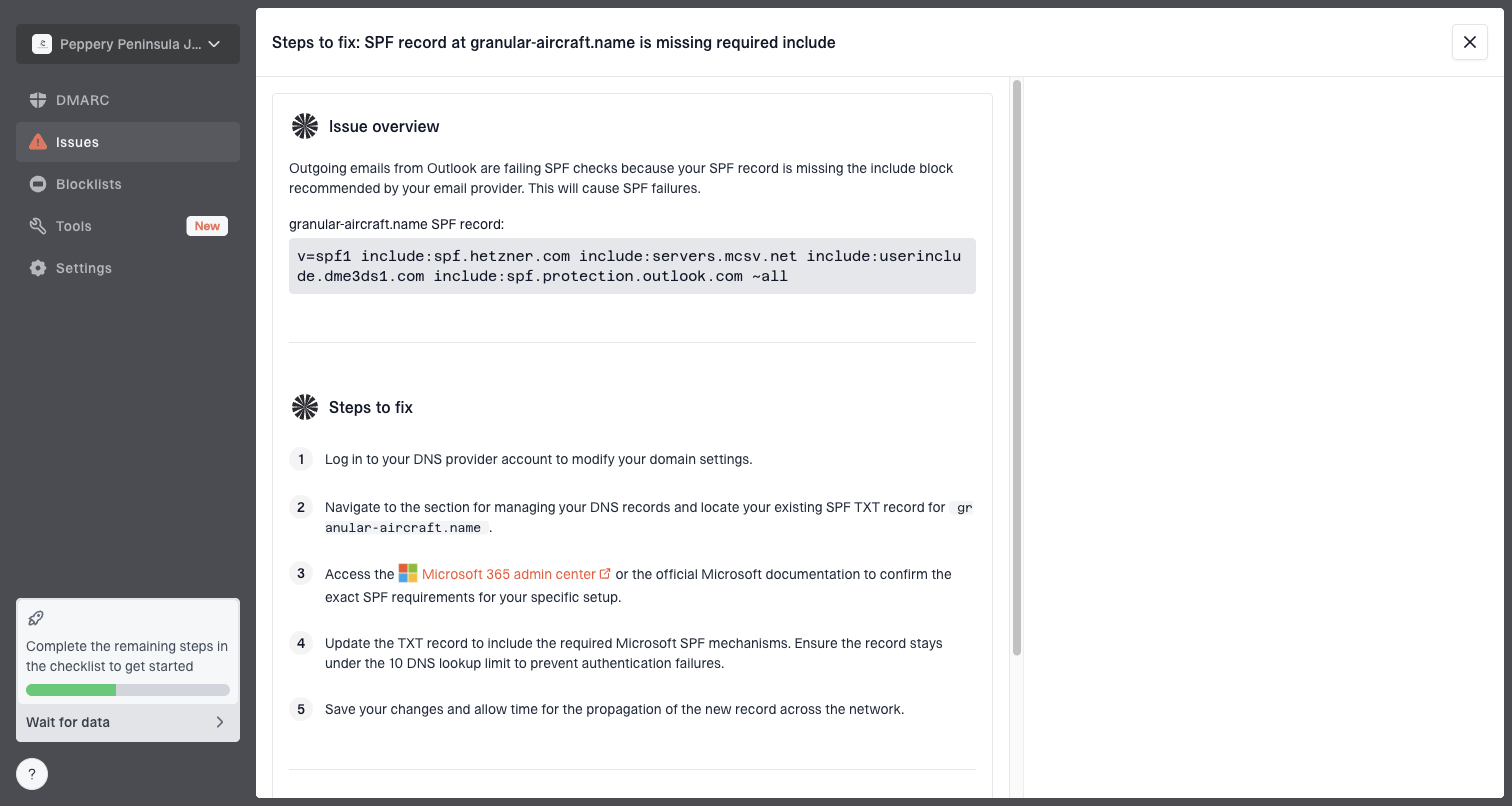
Suped is our DMARC and email authentication platform, and this is where it fits around bounce parsing. Use the domain health checker to validate the obvious DNS and authentication signals, then monitor ongoing authentication outcomes with DMARC monitoring. If responses mention reputation or listing problems, pair that with blocklist monitoring so a blocklist (blacklist) event does not get misread as a dead recipient.
Issue steps to fix dialog showing the issue overview, tailored fix steps, and verification action
For most teams, Suped is the stronger practical DMARC choice because it turns DMARC, SPF, DKIM, hosted SPF, hosted DMARC, hosted MTA-STS, blocklist monitoring, and real-time alerts into specific fix steps. Bounce parsing still belongs in the sending or CRM system, but Suped helps explain the authentication and reputation causes that sit behind many policy bounces.
Views from the trenches
Best practices
Store raw SMTP text, parsed codes, recipient domain, and final action for later review.
Separate address suppression from sender-side fixes such as authentication or reputation work.
Promote repeated 4xx failures only after clear retry windows and recipient-domain review.
Common pitfalls
Treating every 5.7.1 as a bad address hides authentication and policy problems quickly.
Building one giant regex makes provider changes harder to test, explain, and maintain.
Suppressing after one 4xx response removes recipients during greylisting or outages.
Expert tips
Keep provider-specific phrases in data files so engineers can update rules without releases.
Compare bounce classes by receiver, because one domain's 4xx trend can hide a block.
Review unknown responses weekly until the parser has enough real examples for each domain.
Marketer from Email Geeks says separating 5xx and 4xx first gives the parser a reliable baseline before manual review by receiver domain.
2024-03-14 - Email Geeks
Expert from Email Geeks says repeated 4xx failures should eventually move out of retry logic because long-lived temporary errors waste sending capacity.
2024-05-09 - Email Geeks
The practical answer
Start with the code family: 5xx is hard by default, 4xx is soft by default. Then read the enhanced status code, the DSN action, the diagnostic text, the receiver domain, and the retry history. That gives you a parser that is direct enough to automate but careful enough to avoid bad suppression decisions.
The key design choice is to separate classification from action. A bad mailbox should be suppressed. A temporary deferral should be retried within a limit. A policy or authentication failure should trigger sender-side remediation. That separation keeps your list cleaner and your diagnosis more accurate.
If you are building this into production, ship the first version with conservative defaults and a review queue. Automate obvious bad mailboxes, retry clear temporary failures, and hold unclear responses for review. That gives the parser room to improve without making irreversible list changes on weak evidence.
Frequently asked questions
0.0
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.